







索引和事务
索引
概念
索引就好比书的目录,用于加快查找的效率,如果数据库中没有索引,此时查找的时候就需要把整个表遍历一遍

作用
1、索引就是为了避免数据库进行顺序查找,提高查找效率,但是会减慢插入、修改和删除效率(需要同步修改索引)
2、索引会占用额外的空间(用空间换时间)
3、给某列加索引时加在主键上的索引和其他列上的索引是不同的
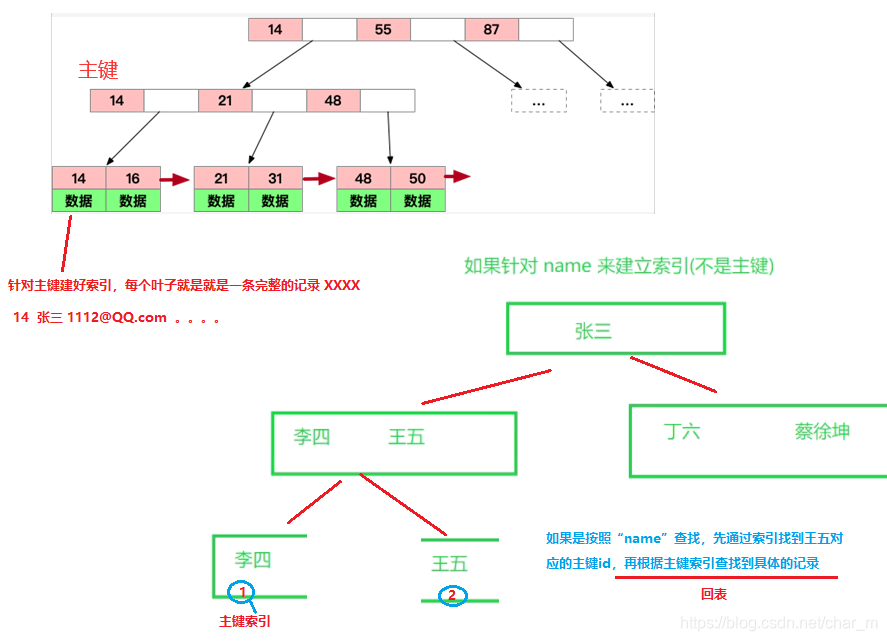
主键索引叶子节点存储的就是数据的完整记录
其他索引叶子节点存的是主键id
应用场景
1、数据量较大,且经常对这些列进行查询
2、改数据库表的插入、修改和删除操作频率较低
3、有足够的磁盘空间

数据结构(B+树)
真实的索引的数据结构是一种N叉搜索树=》 B+树
B树
说起B+树,先从B树来看
B树,也就是B-树(就念B树)

B树和二叉树差异:
1、每个节点不是二叉而是n叉
2、每个节点可能存储多个数据
3、每个节点存的数据的个数和该节点的度是相关的,度=存的数据个数+1
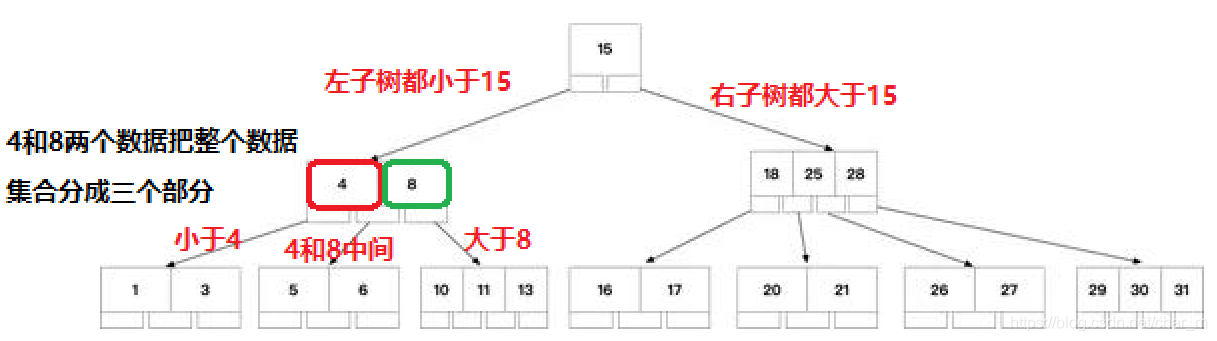
1、所以在B树上查找就是N分查找,效率比二分快很多,
2、由于每个节点存储了多个数据,每个节点又有多个度,和二叉树相比,在保存相同个数元素时,B树的高度就会更低些。
B树的叶子和非叶子都是存储数据,都要放在磁盘上,B树在MYSQL这种关系型数据库中不是特别适用,但是在有些非关系型数据库(MongoDB),索引结构就是B树
B+树
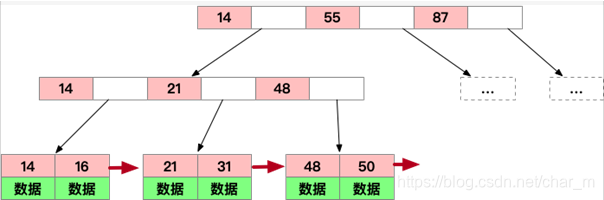
和B树相比
1、每一层的元素之间都链接到一起
2、数据都在叶子节点上,非叶子节点上只保存了一些辅助查找的边界信息
3、B树的叶子和非叶子都是存储数据,都要放在磁盘上,但是B+树 叶子放到磁盘上,非叶子放到内存中,查找效率就更高了(减少了读磁盘的次数)
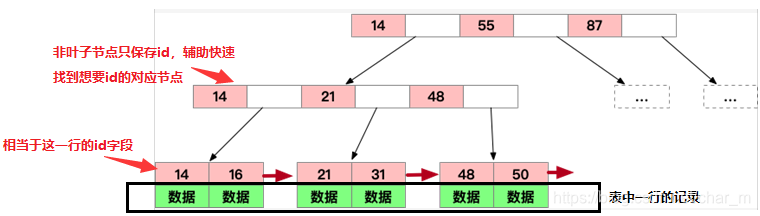
特点:
-
1、仍然是N叉树,层级小,非叶子节点不再存储数据,数据只存储在同一层的叶子节点上,B+树从根到每一个节点的路径长度一样,而B树不是这样== -
2、叶子之间,增加了链表(图中红色箭头指向),获取所有节点,不再需要中序遍历,使用链表的next节点就可以快速访问到 -
3、范围查找方面,当定位min与max之后,中间叶子节点,就是结果集,不用中序回溯(范围查询在SQL中用得很多,这是B+树比B树最大的优势) -
4、 叶子节点存储实际记录行,记录行相对比较紧密的存储,适合大数据量磁盘存储;非叶子节点存储记录的PK,用于查询加速,适合内存存储 -
5、非叶子节点,不存储实际记录,而只存储记录的KEY的话,那么在相同内存的情况下,B+树能够存储更多索引
查询任何一条记录速度是比较平均的,不会出现效率差异大的情况,不需要进行额外的中序遍历,遍历链表就是得到中序结果,处理范围查找更高效。
为什么不用二叉搜索树
如果二叉树比较平衡查找效率为O(logN)
二叉搜索树,内部元素是有序的,中序遍历结果就是有序的
如果借助二叉搜索树实现查找id<6并且>3的学生信息
可以先找到中序遍历中id=3以及id=6,(按照二叉搜索树的典型方式查找也就是折半查找既可)
中序遍历 (中序遍历的效率是O(N)) 中3到6之间的就是要查找的结果。
相比于哈希表二叉搜索树虽然能够处理范围查找,但是处理效率低
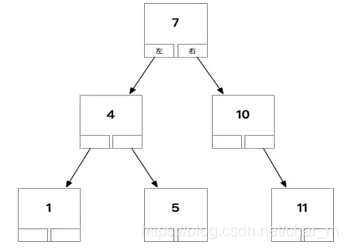
为什么索引不用二叉搜素树:
1、二叉搜索树每个节点最多两个子节点,当数据量比较大的时候,树的高度就会比较高,这样中序遍历递归的次数也就会多,最终操作效率低。
2、二叉搜索树,直接获取中序遍历也不是很高效。O(N),如果是O(N),就跟顺序查找差不多了,甚至可能还会更慢。
3、二叉树每个节点只存储一个记录,一次查询在树上找的时候花费磁盘IO次数较多
为什么不用哈希表
哈希表的查找效率为O(1)
数据库的索引使用哈希表,只能解决一些匹配相等的情况但是无法解决比较范围的问题。
eg:查找id<6并且>3的学生信息
select * from student where id < 6 and id >3 ,哈希表是不能处理的。
哈希表只能处理相等的情况,像 > < <= >= between and这种是无法处理的;
因为哈希表查找是先把key通过哈希函数映射计算得到下标再根据下标取到对应的链表,再去遍历比较key是否相等****,所以如果想要判断大于等于就无法实现。
操作
查看索引

只要指定了primary key 就是主键索引,跟数据表中的自增无关
创建索引

删除索引


补充 explain

事务
概念
把一组操作封装到一起,成为了一个共同的执行单元,此时执行整个事务就会避免其他的干涉影响。
事务指逻辑上的一组操作,组成这组操作的各个单元,要么全部成功,要么全部失败。在不同的环境中,都可以有事务。对应在数据库中,就是数据库事务。
基本特性
1、原子性: 事务中的若干个操作,要么全部成功,要么全都不执行 (并不是真的不执行,如果一旦中间某个步骤执行出错,就把前面已经执行完毕的步骤回滚,把原来操作造成的影响进行还原,操作可逆)
2、一致性: 执行事务前后,数据始终处于合法状态,例如转账,减账户余额时,不能把账户减成负数。
3、持久性: 事务一旦执行完毕,对数据的修改就是持久生效(写入磁盘)数据存到磁盘就是持久的,数据存到内存就是不持久的重启就没了。
4、隔离性: 涉及到并发执行事务,多个事务并发执行时,事务之间不能相互干扰(本质就是线程安全问题)
隔离性和并发
隔离性和并发是相悖的
隔离是为了保证数据准确
并发是为了提高事务执行的效率
如果多个事务之间隔离性越强,并发程度就越低,效率越低;
如果多个事务之间隔离性越弱,并发程度就越高,效率越高
虽然两者相悖,但是在不同的应用场景下,对于数据的准确性的要求不一样,可以在满足数据准确性要求的前提下,尽可能的提高并发程度。 涉及到MySQL中的事务隔离级别。
并发执行事务
此处考虑的并发执行多个事务,可以类比成多线程执行一些逻辑
但是此处的"写加锁" "读加锁"不要和sychronized类比
写加锁的意思是:我写代码的时候,大家不能读.但是大家读的时候,我还能写.
读加锁的意思是:大家读的时候我也不能写了.
同时具备写加锁和读加锁=>等同于sychronized
1、脏读
事务A读取了事务B提交之前的数据很可能在B最终提交之后,把这个数据又给改了.于是事务A就产生了脏读.
如果一个事务A正在修改数据,还没有提交,另外一个事务B读取了这里的修改内容,此时这样的事务B的读操作就是脏读,因为事务A在提交数据之前,随时可能又修改了刚才的数据
解决:
给写操作加锁,在写的时候不能读,直到写完提交,将锁释放,才能读取。 A在修改数据的过程中,B尝试读,就会阻塞,一直阻塞到A提交数据之后,B才能读到数据。
引入写加锁,事务的并发程度就降低了,效率就低了,隔离性就提高了。
2、不可重复读
一个事务A在执行过程中,事务B第一次读和第二次读,两次读取到的数据不相同
解决:
上面的脏读,是写的时候不能读,但是在读的时候可以写(修改),现在在写加锁的基础上给读也加锁,意思在读取的时候,不能写
引入读加锁,事务的并发性就更低了,效率也就更低了,隔离性就更高了。
3、幻读
同一个事务中,两次读到的结果集不-一致.,虽然读锁加了之后,读的时候不能改,但是可以新增或者删除记录.
一次事务执行过程中,多行读取到的结果集不一样,(具体的结果是一致的)
解决:
串行化,读的时候不能改,改的时候不能读,这个时候并发性最低,效率最低,但是数据可靠性最高。
语句
start transaction 开启事务,表示接下来的操作都是在同一个事务中。
commit 事务结束,开始正式执行,一旦中间某个步骤执行出错,就会进行回滚。
mysql> select * from accout;
+----+--------------+---------+
| id | name | money |
+----+--------------+---------+
| 1 | 阿里巴巴 | 5000.00 |
| 2 | 四十大盗 | 1000.00 |
+----+--------------+---------+
2 rows in set (0.00 sec)
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql> update accout set money=money-2000 where name = '阿里巴巴';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> update accout set money=money+2000 where name = '四十大盗';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> commit;
Query OK, 0 rows affected (0.01 sec)
mysql> select * from accout;
+----+--------------+---------+
| id | name | money |
+----+--------------+---------+
| 1 | 阿里巴巴 | 3000.00 |
| 2 | 四十大盗 | 3000.00 |
+----+--------------+---------+
2 rows in set (0.00 sec)
假如在执行以上第一句SQL时,出现网络错误,或是数据库挂掉了,
阿里巴巴的账户会减少2000,但是 四十大盗的账户上就没有了增加的金额。
MySQL的隔离级别
MySQL的隔离级别:对隔离性的要求具体多高(隔离性高了,并发程度就低了,数据可靠性高了,效率就低了)
- read uncommitted:
- 允许读取未提交的数据(隔离程度最低,并发性最高,会有脏读问题)
- read committed:
- 只允许读取已经提交的数据,相当于写加锁. (隔离性提高了- -些, 并发性降低了一一些解决了脏读,但是会有不可重复读)
- repeatable read(MySQL的默认隔离级别):
- 给读也加锁. (隔离性又提高了,并发性又降低了,解决了不可重复读,但是会有幻读问题).
- serializable :
- 严格串行化执行. (隔离性性最高,并发最低解决了幻读问题)
SQL语句中显式的指定当前的SQL使用哪种隔离级别.不指定,默认就是repeatable read

















 1795
1795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









