



CVPR2020原论文:https://arxiv.org/pdf/2005.04668v1.pdf
代码地址(pytorch框架):https://github.com/HUSTSYJ/DA_dahazing
摘要
近年来,使用基于学习的方法的图像去雾已经实现了最先进(SOAT)的性能。然而,大多数现有方法在合成的模糊图像上训练去雾模型,由于域偏移,该去雾模型不太能够很好地推广到真实的模糊图像。为了解决这个问题,我们提出了一个领域适应范例,它包括一个图像翻译模块和两个图像去雾模块。具体来说,我们首先应用双向翻译网络,通过将图像从一个域翻译到另一个域来弥合合成域和真实域之间的差距。然后,我们使用翻译前后的图像来训练一个有一致性约束的双图像去雾网络。在这个阶段,我们通过利用清晰图像的属性(例如,暗通道先验和图像梯度平滑)将真实的模糊图像合并到去雾训练中,以进一步提高域适应性。通过对图像平移和去雾网络进行端到端的训练,可以获得更好的图像平移和去雾效果。在合成图像和真实图像上的实验结果表明,该模型的性能优于现有去雾算法。
引言
为了解决这个问题,我们提出了一个单幅图像去雾的域自适应框架。所提出的框架包括两个部分,即图像平移模块和两个域相关去雾模块(一个用于合成域,另一个用于实域)。为了减少域之间的差异,我们的方法首先使用双向图像翻译网络将图像从一个域翻译到另一个域。由于图像模糊是一种高度依赖于场景深度的噪声和不均匀性,我们将深度信息引入到翻译网络中,以指导合成模糊图像到真实模糊图像的翻译。然后,与域相关的去雾网络获取该域的图像,包括原始图像和翻译图像,作为执行图像去雾的输入。此外,我们使用一致性损失来确保两个去雾网络生成一致的结果。在这个训练阶段,为了进一步提高网络在真实域中的泛化能力,我们将真实的模糊图像加入到训练中。我们希望真实模糊图像的去雾结果能够具有清晰图像的一些性质,如暗通道先验和图像梯度平滑。我们以端到端的方式训练图像翻译网络和去雾网络,以便它们可以相互改进。
本文贡献:
(1)提出了一个端到端的图像去雾域自适应框架,有效地弥补了合成图像和真实图像之间的差距。
(2)将真实的模糊图像融入训练过程可以提高去雾性能。
我们的模型首先应用图像平移网络将图像从一个域平移到另一个域,然后使用平移图像及其原始图像(合成或真实)在合成和真实域上执行图像去雾。该方法能有效解决域转移问题
有用的零碎知识点:
一、引言
基于深度学习的方法需要依赖大量真实的模糊图像及其无模糊对应物进行训练。一般来说,在现实世界中获取大量地面实况图像是不切实际的。
二、域适应
领域适应旨在减少不同领域之间的差异。现有的工作或者执行特征级或者像素级的适应。特征级适应方法旨在通过最小化最大平均差异或在特征空间上应用对抗性学习策略来对齐源域和目标域之间的特征分布。另一项研究侧重于像素级适应。这些方法通过应用图像到图像翻译学习或风格转移方法来增加目标域中的数据,从而处理域转换问题。
我们利用CycleGAN来调整真实的模糊图像,以适应我们在合成数据上训练的去雾模型。此外,由于深度信息与图像模糊的形成密切相关,我们将深度信息纳入到翻译网络中,以更好地指导真实模糊图像的翻译。
三、提出的方法
3.1
域自适应框架包括两个主要部分:图像翻译网络和
和两个去雾网络.图像翻译网络将图像从一个域翻译到另一个域,以弥合它们之间的差距。然后去雾网络使用转换的图像和源图像来执行图像去雾。
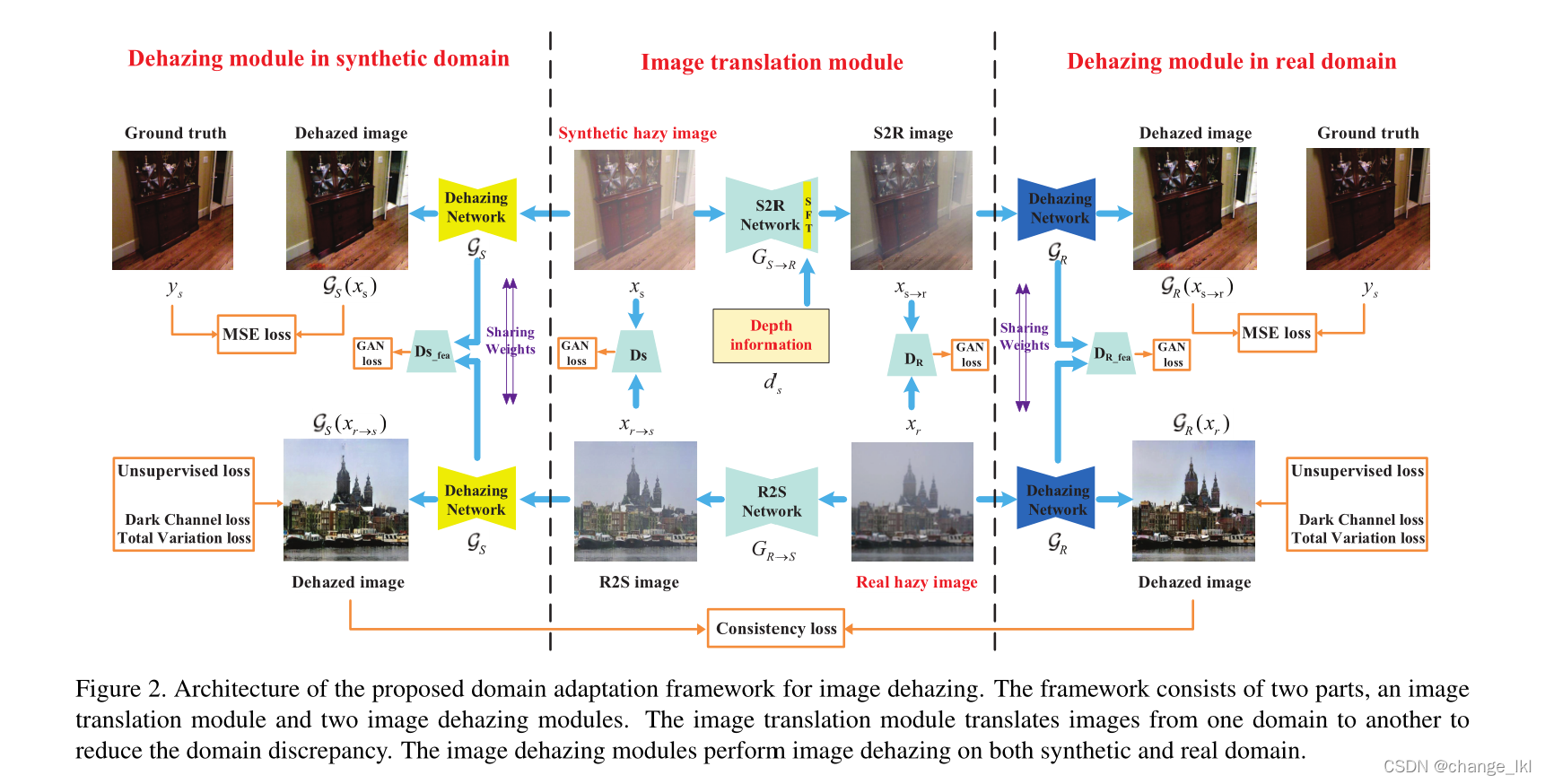
3.2图像翻译模块
图像翻译模块包括两个翻译器:合成到真实网络和真实到合成网络
我们采用空间特征变换(SFT)层将深度信息纳入翻译网络,这可以有效地融合深度图和合成图像的特征。如图3所示
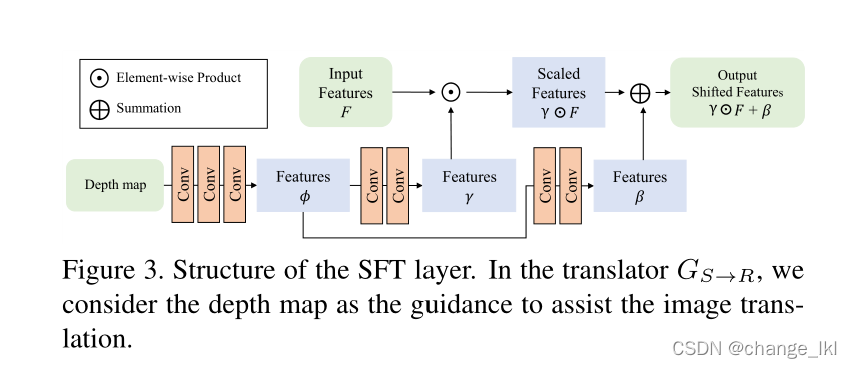
在翻译器中,我们将深度图视为指导,并使用SFT层来转换倒数第二个卷积层的特征。如图4所示,翻译后的合成图像相对更接近真实世界的模糊图像
3.3. 去雾模块
两个去雾模块,一个用于真实图像图像去雾(包括本身真实图像或者由合成图像翻译成的真实图像),另一个用于合成图像去雾(包括真实的合成图像和真实图像由翻译模块翻译成的合成图像)
3.4训练损失
图像翻译损失:
目的:使translator生成的图像和真实雾图
难以分辨。引入像素级辨别器
和特征级辨别器
对抗性损失定义为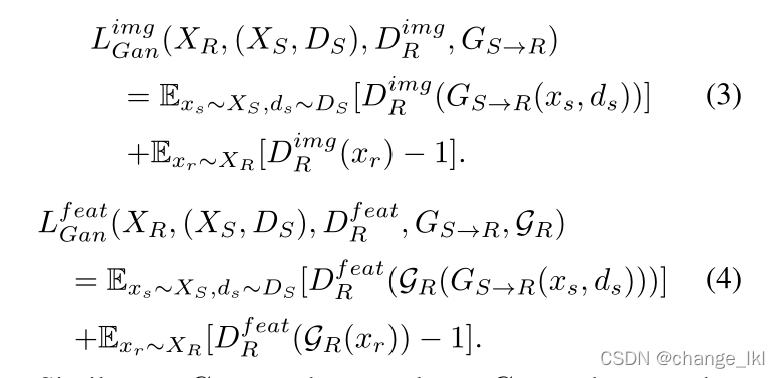
循环一致性损失:
依次传递到
和
希望
(
(
,
))=
同理
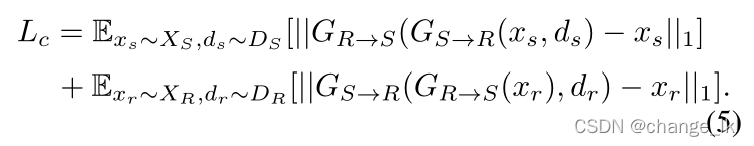
身份映射损失:
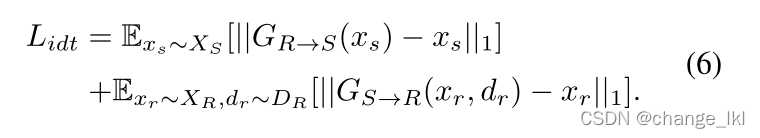
翻译模块的全损耗函数如下:
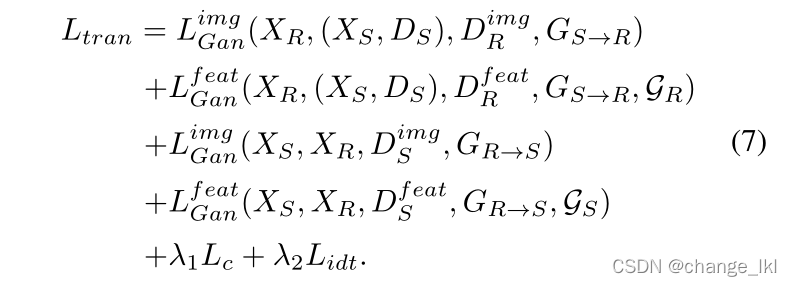
图像去雾损失:
半监督的方式训练一个图像去雾网络,受监督的分支,我们应用均方损失来确保预测的图像接近干净的图像
,
![]()
无监督分支中,我们引入了总变分和暗通道损失,这使去雾网络正则化,以产生具有与清晰图像相似的统计特征的图像
![]()
∂h代表水平梯度算子,∂v代表垂直梯度算子。
暗通道(DC)损失来确保预测图像的暗通道与干净图像的暗通道一致:
![]()
监督损失和非监督损失来训练去雾网络:
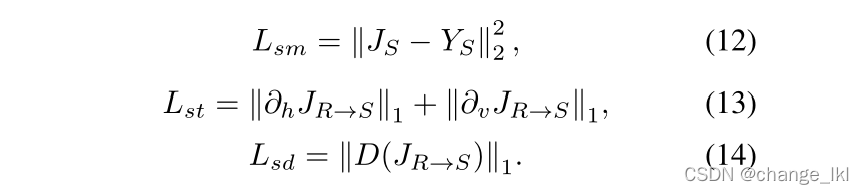
两个去雾网络的输出对于真实的有雾图像应该是一致:
![]()
总体损失函数:
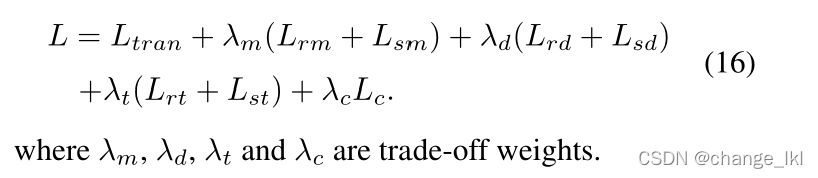
本文方法:
我们的模型首先应用图像平移网络将图像从一个域平移到另一个域,然后使用平移图像及其原始图像(合成或真实)在合成和真实域上执行图像去雾。该方法能有效解决域变问题。
图像翻译网络将图像从一个域翻译到另一个域,以弥合它们之间的差距。然后去雾网络使用转换的图像和源图像(例如,合成的或真实的)来执行图像去雾。
知识点补充:
(1)自监督方式:自监督学习介绍 - 简书 (jianshu.com)
(2)半监督方式:
- 既有有标记数据 xr,又有无标记数据 xu,一般无标记数据的数量远大于有标记数据。半监督学习又可以分为两种:
- Transductive learning:无标记数据就是
Testing data. - Inductive learning:无标记数据不是 testing data,假设在训练时不知道 testing set.
- Transductive learning:无标记数据就是
(3)无监督:
缺乏足够的先验知识,因此难以人工标注类别或进行人工类别标注的成本太高。很自然地,我们希望计算机能代我们完成这些工作,或至少提供一些帮助。根据类别未知(没有被标记)的训练样本解决模式识别中的各种问题,称之为无监督学习。(来自百度百科)
(4)评价指标
SSIM:SSIM (Structure Similarity Index Measure) 结构衡量指标+代码 - 知乎 (zhihu.com)
图像质量评价指标之 PSNR 和 SSIM - 知乎 (zhihu.com)
(6)cycleGan:CycleGAN详细解读 - 知乎 (zhihu.com)

















 3576
3576

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









