






CUDA编程模型是一个异构模型,需要CPU和GPU协同工作。在CUDA中,host和device是两个重要的概念,一般用host指代CPU及其内存,而用device指代GPU及其内存。CUDA程序中既包含host程序,又包含device程序,它们分别在CPU和GPU上运行。host和device之间可以进行通信,他们之间需要进行数据拷贝。典型的CUDA程序的执行流程如下:
1.分配host内存,并进行数据初始化;
2.分配device内存,并从host将数据拷贝到device上;
3.调用CUDA的核函数在device上完成指定的运算;
4.将device上的运算结果拷贝到host上;
5.释放device和host上分配的内存。
上面流程中最重要的一个过程是调用CUDA的核函数来执行并行计算,kernel是CUDA中一个重要的概念,kernel是在device上线程中并行执行的函数,核函数用__global__符号声明,在调用时需要用<<<grid, block>>>来指定kernel要执行的线程数量,在CUDA中,每一个线程都要执行核函数,并且每个线程会分配一个唯一的线程号thread ID,这个ID值可以通过核函数的内置变量threadIdx来获得。
由于GPU实际上是异构模型,所以需要区分host和device上的代码,在CUDA中是通过函数类型限定词开区别host和device上的函数,主要的三个函数类型限定词如下:
__global__:在device上执行,从host中调用(一些特定的GPU也可以从device上调用),返回类型必须是void,不支持可变参数参数,不能成为类成员函数。注意用__global__定义的kernel是异步的,这意味着host不会等待kernel执行完就执行下一步。
__device__:在device上执行,单仅可以从device中调用,不可以和__global__同时用。
__host__:在host上执行,仅可以从host上调用,一般省略不写,不可以和__global__同时用,但可和__device__,此时函数会在device和host都编译。
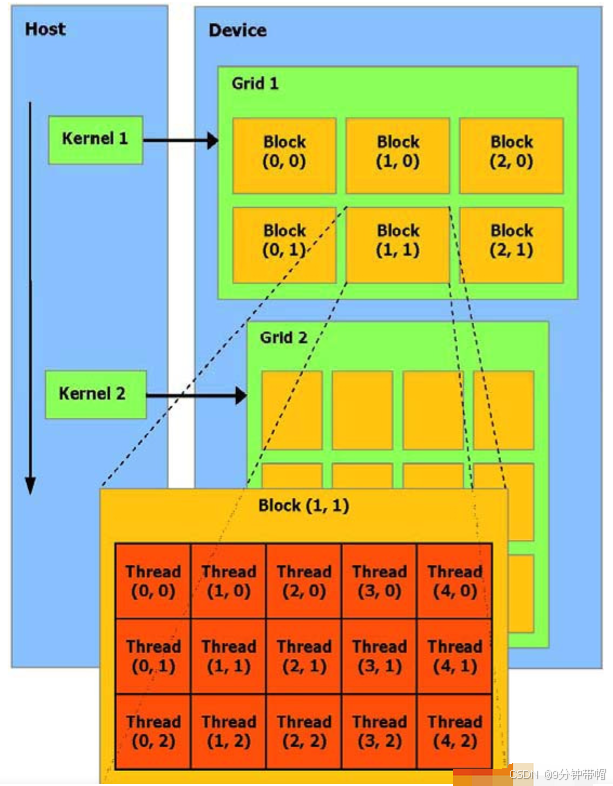
图中显示一个kernel会被grid中的线程块一起执行。这里就有几个概念,gird、block和thread。一个grid有多个block构成;一个block有多个thread构成。
grimDim.x 代表 在grid中的x方向上有多少个block
grimDim.y 代表 在grid中的y方向上有多少个block
blockDim.x 代表 在block中的x方向上有多少个thread
blockDim.y 代表 在block中的y方向上有多少个thread
blockIdx.x 代表该thread所在的block中的x方向上的索引
blockIdx.y 代表该thread所在的block中的y方向上的索引
其中grid中的block有x/y/z三个维度,总数有最大值,每个维度上有各自的最大值,需要查阅当前的cuda规范。同时block中的线程也分x/y/z三个维度,总数有最大值,每个维度上有各自的最大值。一般来说,block中的线程数最大为1024个。线程的序号由block数目和线程在block中的位置,对于上述kernel1,thread(4,2)来说,线程Id的计算为:
threadId
=(threadIdx.x+threadIdx.y*blockDim.x)+(blockIdx.x+blockIdx.y*gridDim.x)*(blockDim.x*blockDim.y)
=(4+2*5)+(1+1*3)*(5*3)=14+60=74使用kernelFunction<<<gridDim,blockDim>>>()来指定对应的gridDim和blockDim并且启动和函数。根据wiki的数据显示:每一个gird有多少个block 最大2^31-1 x方向最大2^31-1 y,z 方向65535; 每一个block有多少个线程 最大1024 x,y方向最大1024 z最大64。
以下是一个向量加法的代码demo:
CMakeLists.txt
cmake_minimum_required(VERSION 3.16)
project(ArrayAdd LANGUAGES CXX)
set(CMAKE_CXX_STANDARD 17)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
#CUDA
option(CUDA_USE_STATIC_CUDA_RUNTIME OFF)
set(CUDA_GEN_CODE "-gencode=arch=compute_86,code=sm_86")
set(CUDA_NVCC_FLAGS ${CUDA_NVCC_FLAGS};-std=c++17;-g;-G;-gencode;arch=compute_75;code=sm_75;)
set(CUDA_DIR "C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v12.1")
include_directories(${CUDA_DIR}/include)
link_directories(${CUDA_DIR}/lib/x64)
link_libraries(cudnn;cublas;cudart;nvrtc)
find_package(CUDA REQUIRED)
enable_language(CUDA)
set(EXECUTABLE_OUTPUT_PATH ${CMAKE_SOURCE_DIR}/bin)
add_executable(ArrayAdd add.h add.cu main.cpp)
add.h
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
#include <iostream>
#define CHECK(call) check_runtime(call, #call, __LINE__, __FILE__)
static bool check_runtime(cudaError_t e, const char* call, int line, const char* file)
{
if (e != cudaSuccess) {
printf("CUDA Runtime error %s # %s, code = %s [ %d ] in file %s:%d", call, cudaGetErrorString(e), cudaGetErrorName(e), e, file, line);
return false;
}
return true;
}
void add_arrays(int* A, int* B, int* C, int N);
add.cu
#include "add.h"
__global__ void addArraysKernel(int *A, int *B, int *C, int N)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
int stride = blockDim.x * gridDim.x;
printf("blockIdx.x:%d threadIdx.x:%d\n", blockIdx.x, threadIdx.x);
for(int i=index; i<N; i+=stride)
C[i] = A[i] + B[i];
}
void add_arrays(int* A, int* B, int* C, int N)
{
int *d_A, *d_B, *d_C;
// 分配GPU内存
CHECK(cudaMalloc((void**)&d_A, N * sizeof(int)));
CHECK(cudaMalloc((void**)&d_B, N * sizeof(int)));
CHECK(cudaMalloc((void**)&d_C, N * sizeof(int)));
// 将数据从主机复制到设备
CHECK(cudaMemcpy(d_A, A, N * sizeof(int), cudaMemcpyHostToDevice));
CHECK(cudaMemcpy(d_B, B, N * sizeof(int), cudaMemcpyHostToDevice));
// 调用核函数
// size_t blocks = 256;
// size_t threads = 10;
dim3 blocks = dim3(256, 1, 1);
dim3 threads = dim3(32, 1, 1); //block size 32,32,x
addArraysKernel<<<blocks, threads>>>(d_A, d_B, d_C, N);
// 同步以确保核函数执行完成
cudaDeviceSynchronize();
// 将结果从设备复制回主机
CHECK(cudaMemcpy(C, d_C, N * sizeof(int), cudaMemcpyDeviceToHost));
// 释放GPU内存
CHECK(cudaFree(d_A));
CHECK(cudaFree(d_B));
CHECK(cudaFree(d_C));
}
#include "add.h"
void init_array(int num, int* array, int N)
{
for(int i=0;i<N;i++)
{
array[i]=num;
}
}
int main()
{
const int N = 50000;
int A[N], B[N], C[N];
init_array(2, A, N);
init_array(3, B, N);
init_array(0, C, N);
clock_t start,end;
start=clock_t();
for(int i=0;i<N;i++)
{
C[i]=A[i]+B[i];
}
end=clock_t();
std::cout << "add_cpu time = " << double(end - start)<< std::endl;
init_array(0, C, N);
start=clock_t();
add_arrays(A, B, C, N);
end=clock_t();
std::cout << "add_gpu time = " << double(end - start)<< std::endl;
// 输出结果
for(int i = 0; i < 100; ++i)
std::cout << C[i] << " ";
std::cout<<std::endl;
for(int i = 49900; i < 50000; ++i)
std::cout << C[i] << " ";
return 0;
}
注意,带有__global__ kernel的核函数必须写在.cu后缀的文件中,要不然编译不通过。

















 468
468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









