






文章目录
正则表达式使用单个字符串来描述、匹配一系列符合某个语法规则的字符串。
在很多文本编辑器里,正则表达式通常被用来检索、替换那些符合某个模式的文本。在Linux 中,grep,sed,awk 等文本处理工具都支持通过正则表达式进行模式匹配。
常规匹配
一串不包含特殊字符的正则表达式匹配它自己,例如:
cat /etc/passwd | grep root

就会匹配所有包含root的行。
常用特殊字符
^:匹配一行的开头
# 匹配以a开头的所有行
cat /etc/passwd | grep ^a
cat /etc/passwd | grep ^a
$:匹配一行的结束
# 匹配出所有以t 结尾的行
cat /etc/passwd | grep t$

. 匹配任意字符
cat /etc/passwd | grep r.t

cat /etc/passwd | grep r..t

cat /etc/passwd | grep r...t

*不单独使用,他和上一个字符连用,表示匹配上一个字符0 次或多次
cat /etc/passwd | grep ro*t

.* 所有字符出现多次
# 包含以r开头t结尾的字符串的行
grep r.*t
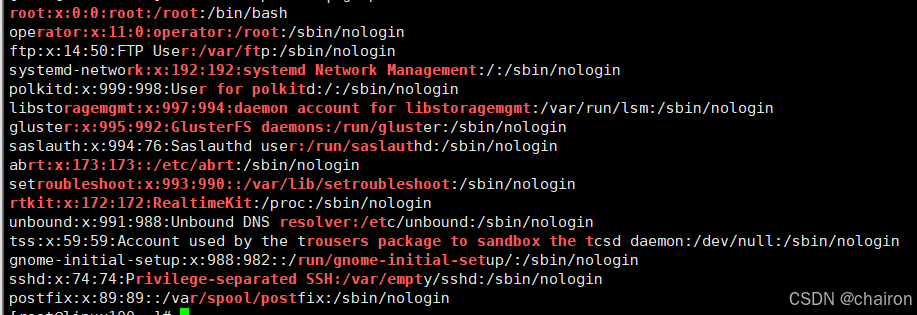
# 以r开头,以bash结尾的所有行(模糊匹配)
cat /etc/passwd | grep ^r.*bash$

# 以r开头以in结尾,中间有var字符的所有行
cat /etc/passwd | grep ^r.*var.*in$

cat /etc/passwd | grep ^r.*var.*ind.*in$

[] 字符区间
[ ] 表示匹配某个范围内的一个字符,例如
- [6,8]------匹配6 或者8
- [0-9]------匹配一个0-9 的数字
- [0-9]*------匹配任意长度的数字字符串
- [a-z]------匹配一个a-z 之间的字符
- [a-z]* ------匹配任意长度的字母字符串
- [a-c, e-f]-匹配a-c 或者e-f 之间的任意字符
# 匹配at或者yt
cat /etc/passwd | grep [a,y]t

# 匹配【a-z】之间的任一字符+t,比如说at,ct
cat /etc/passwd | grep [a-z]t
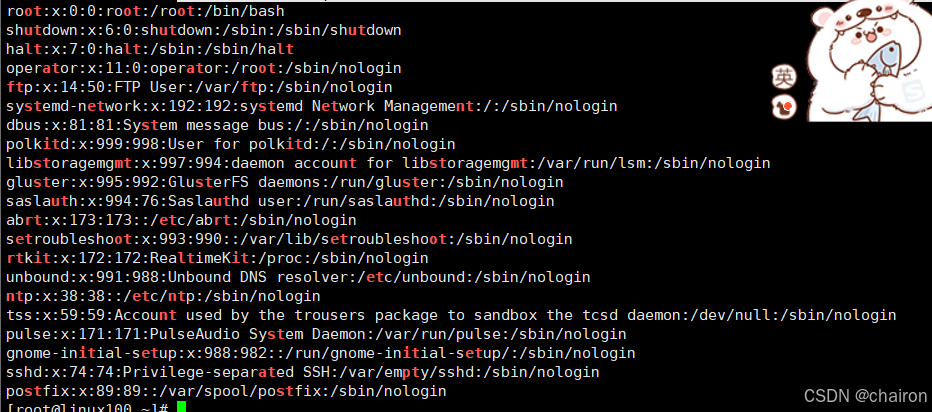
# 匹配【a-d】之间的任意字符任意长度+t,比如说【aaat】
cat /etc/passwd | grep [a-d]*t
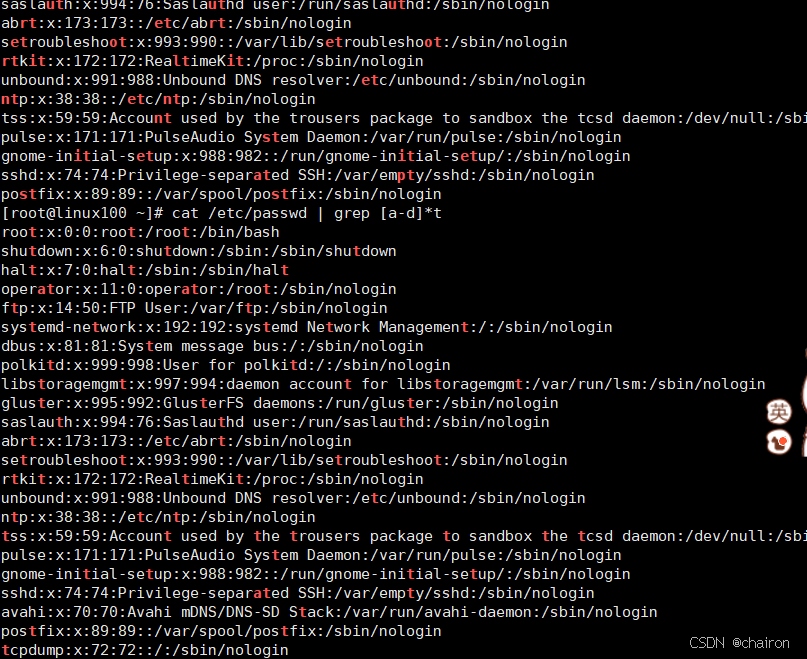
echo 'aaaatmdeiijbbtccdaatffedt' | grep [a-d]*t

特殊字符:\表示转义
由于所有特殊字符都有其特定匹配模式,当我们想匹配某一特殊字符本身时(例如,我想找出所有包含’$’ 的行),就会碰到困难。此时我们就要将转义字符和特殊字符连用,来表示特殊字符本身。需要用’ '引起来。
例如:
# 匹配/$
cho 'aaaatmdeiijbbtcc/$daa$tffedt' | grep '/\$'
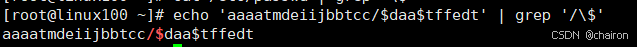
练习:手机号匹配
手机号:11位,1开头 第二位【3、4、5、7、8】,其余【0~9】
echo 18384351871|grep ^1[3,4,5,7,8][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]$
18384351871
echo 183843518711|grep ^1[3,4,5,7,8][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9
# [0-9]{9} 表示出现9次,{}是扩展的正则匹配,grep默认不支持,需要加上参数 -E
echo 18384351871|grep -E ^1[3,4,5,7,8][0-9]{9}$
18384351871

















 856
856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









