




 本文探讨了梯度下降的几种变种,如SGD、SGD with momentum、Adagrad、RMSProp和Adam。重点讲解了在线和离线优化的区别,并详细介绍了Adam的优点和在实际应用中的对比,如BERT和YOLO。此外,还提到了如何通过SWATS、AMSGrad、AdaBound等方法改进Adam和SGDM,以及L2范式对AdamW和SGDWM的影响。
本文探讨了梯度下降的几种变种,如SGD、SGD with momentum、Adagrad、RMSProp和Adam。重点讲解了在线和离线优化的区别,并详细介绍了Adam的优点和在实际应用中的对比,如BERT和YOLO。此外,还提到了如何通过SWATS、AMSGrad、AdaBound等方法改进Adam和SGDM,以及L2范式对AdamW和SGDWM的影响。
1 New Optimizers for Deep Learning
梯度下降:
SGD
SGD with momentum
Adaptive learning rate:
Adagrad
RMSProp
Adam
1.1 Some Notations
| 𝜃t | ∇𝐿(𝜃𝑡) | 𝑚 𝑡+1 |
|---|---|---|
| 在step t时的参数 | 下降的梯度 | 前面t步积累的动量,用来计算𝜃𝑡+1 |
1.2 Optimization’s aim
- 找到一个参数 𝜃 使属性x的损失函数总和最小, lowest σ𝑥 𝐿(𝜃; 𝑥)
- 或者说找到一个参数𝜃 去得到最低的损失函数 𝐿(𝜃) !
1.3 On-line vs Off-line(这节课的重点)
| On-line | Off-line |
|---|---|
| 一个step一个参数 x | 每一个step都要输入所有x |


1.4 SGD
- 随机梯度下降:在曲线上随机初始化一个点,计算微分,下一个点的位置就是这个值-学习率*微分,直到微分为0.

1.5 SGD with Momentum(SGDM)
梯度只是影响速度,然后速度再影响位置。
带有动量的SGD算法,动量不是由梯度(微分)决定,而是由以前的动量决定(上一步的动量)
相当于加入了惯性,让你能够有机会跨国局部最小值,或者很平缓的地方,去寻找全局最优。



1.6 Adagrad(自适应梯度下降算法)
Adagrad是解决不同参数应该使用不同的更新速率的问题。
Adagrad自适应地为各个参数分配不同学习率的算法。
- 随着我们更新次数的增大,我们是希望我们的学习率越来越慢。
- 因为我们认为在学习率的最初阶段,我们是距离损失函数最优解很远的,随着更新的次数的增多,我们认为越来越接近最优解,于是学习速率也随之变慢。

1.7 RMSProp
RMSprop(即均方根传播)目的是解决AdaGrad的学习率急剧下降的问题。
RMSprop更改学习速率的速度比AdaGrad慢,但是RMSprop仍可从AdaGrad(更快的收敛速度)中受益。
RMSProp仍然是基于梯度的大小来对每个权重的学习率进行修改,但其更新不会让学习率单调变小。
-
RMSProp优化算法和AdaGrad算法唯一的不同,就在于累积平方梯度的求法不同。
-
RMSProp算法不是像AdaGrad算法那样暴力直接的累加平方梯度,而是加了一个衰减系数来控制历史信息的获取多少。

-
AdaGrad算法的改进。鉴于神经网络都是非凸条件下的,RMSProp在非凸条件下结果更好,改变梯度累积为指数衰减的移动平均以丢弃遥远的过去历史。
-
经验上,RMSProp被证明有效且实用的深度学习网络优化算法。
起到的效果是在参数空间更为平缓的方向,会取得更大的进步。 因为平缓,所以历史梯度平方和较小,对应学习下降的幅度较小。 并且能够使得陡峭的方向变得平缓,从而加快训练速度。
1.8 Adam
-
SGDM+RMSProp
-
Adam使用动量和自适应学习率来加快收敛速度。
-
“Adam可以理解为加了Momentum 的 RMSprop”
-
在实际操作中,推荐Adam作为默认算法


在训练的最后阶段,大多数梯度都是小的,没有信息的,而后面一些小批量的梯度提供更有用的信息。
- 由于,Adam的机制,会考虑历史的大量的梯度影响,在出现一个真正有意义的重要的梯度时,往往又被削弱了其影响。如图中100999次迭代,产生了超大的gradient,结果由于Adam的机制,最后让他削弱的影响还没有之前的小的gradient的影响大。
2 Optimizers: Real Application
| ADAM | SGDM |
|---|---|
| BERT、Tacotron、Transformer、MAML、Big-GAN | Mask R-CNN、YOLO、ResNet |
Adam:训练快速,泛化误差大,不稳定
SGDM:稳定,泛化误差小,收敛性好
3 improving Adam
3.1 SWATS
Begin with Adam(fast), end with SGDM
- Adam 虽然在初始部分的训练和泛化度量都优于 SGD,但在收敛部分的性能却停滞不前。这令很多研究者开始寻找结合 Adam 和 SGD 的新方法,他们希望新算法不仅能利用 Adam 的快速初始化过程,同时还利用 SGD 的泛化属性。
- 适应性方法因为非均匀的梯度缩放而导致泛化性能的损失,因此我们比较自然的策略是利用 Adam 算法初始化训练,然后在适当的时候转换为 SGD 方法


3.2 AMSGrad
减少非有用信息梯度的影响
消除因最大操作而产生的去偏(de-biasing)
单调递减的学习速率

-
在训练的最后阶段,大多数梯度都是小的,没有信息的,而一些小批量的梯度很少提供大的信息
-
学习率要么非常大(对于小的渐变)要么非常小(对于大的渐变)
-
AMSGrad只处理高学习率
-
AdaBound:
对Learning Rate加阈值,限制其范围,避免过大和过小。
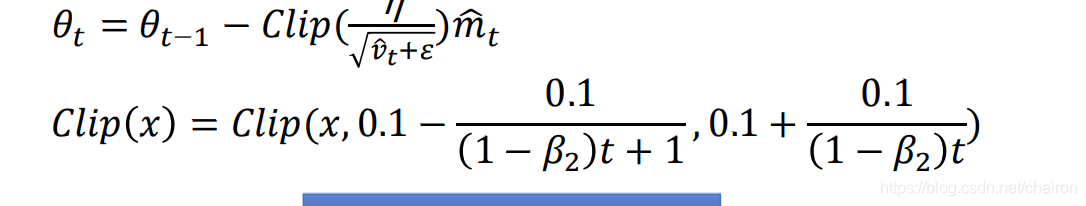
4 Improving SGDM
自适应学习率算法:随时间动态调整学习率
SGD类型的算法:为所有的更新修正学习速率……对于小的学习速率来说太慢,而对于大的学习速率来说则会导致糟糕的结果
4.1 LR range test
4.2 Cyclical LR
周期性改变Learning Rate,周期性变大变小,维持其搜索速度和精度
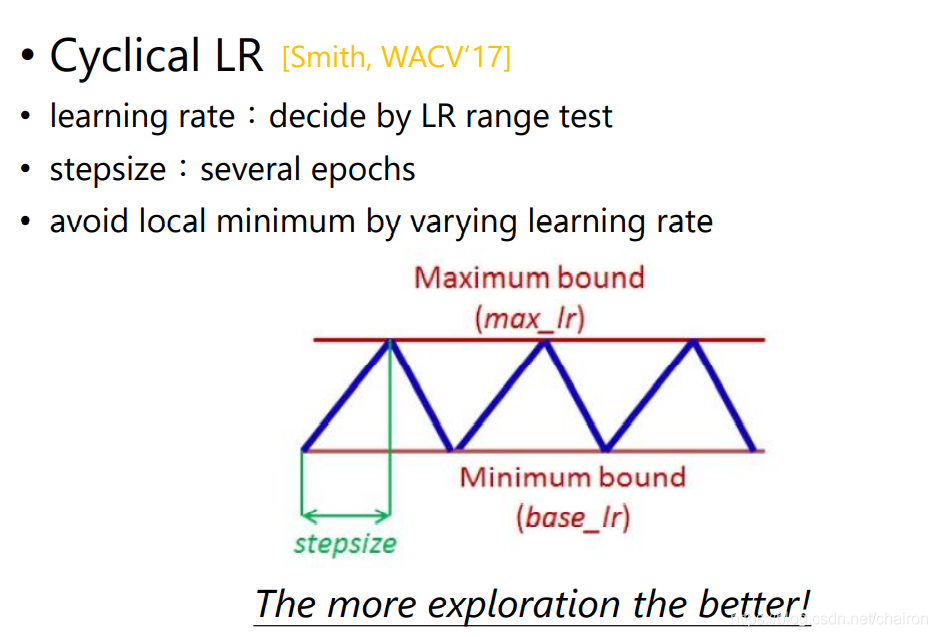
4.3 SGDR
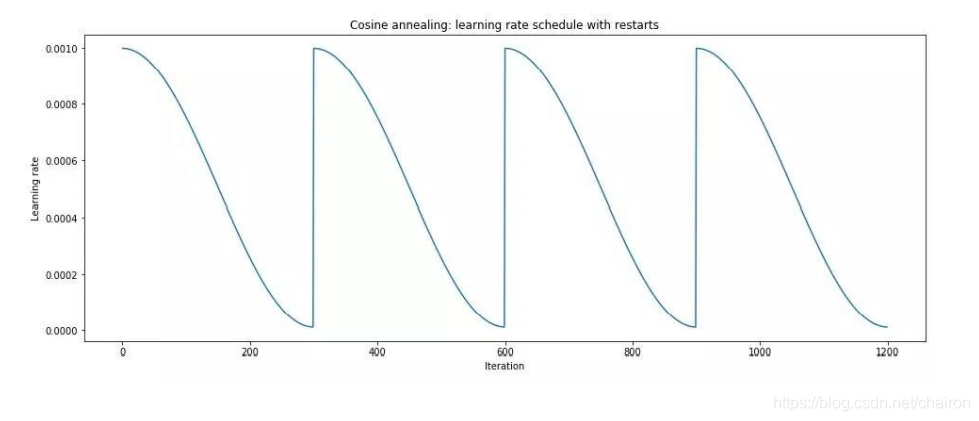
变大过程直接阶跃变最大
4.4 One-Cyclical LR
单个周期内改变其大小。
续
5.2 RAdam: Adam+warm-up
- Adam的梯度分布在开始几步很混乱,会造成不好的学习率
- warm-up要做的就是在训练开始走的很小步来减少梯度的variance,提高稳定性。
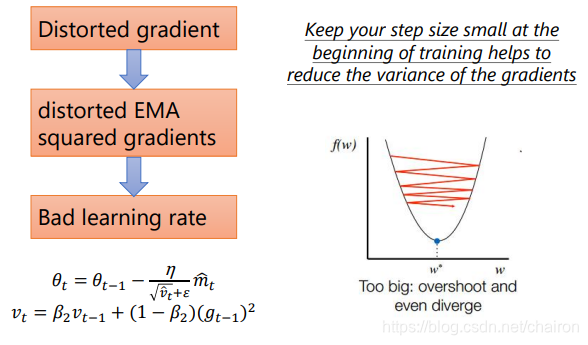

5.2 RAdam vs SWATS
| RAdam | SWATS | |
|---|---|---|
| 解决问题 | 在开始训练时,混乱的梯度会造成自适应学习率的不精确 | Adam的不收敛和泛化差异;SGDM的训练速度慢 |
| 方法 | 使用warm-up learning rate去减少自适应学习率不精确的影响 | 结合两者的优势:先用Adam(快),再用SGDM(稳) |
| 转换 | SGDM to Adam | Adam to SGDM |
| 转换目的 | 在开始训练时 𝑣的variance的近似值可能是无效的,不能用Adam,用SGDM,当近似值有效时就可以转化为Adam了 | 为了追求更好的收敛性 |
| 转换点 | 当近似值变的有效时 | 一些人为标准 |
5.3 k step forward, 1 step back
所有优化器的通用包wapper

- 1 step back:避免太危险的探索----->更稳定
- 寻找一个更平稳的minimum----------->泛化能力更强
5.4 Nesterov accelerated gradient (NAG)
超前部署
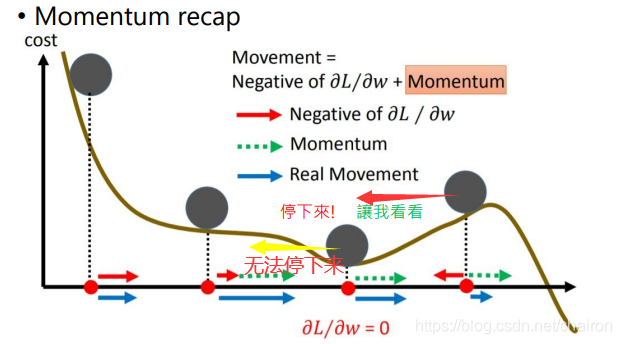
- 如果从右边开始运动,在最低点无法停下来,因为不知道下一个位置是怎样的,无法决定是继续前进还是停止。
- 超前部署,提前判断



5.5 L2范式与AdamW & SGDWM
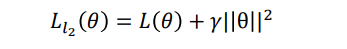
- 相当于添加了噪音,把SGD、SGDM、Adam中的L(e)进行替换,求得:
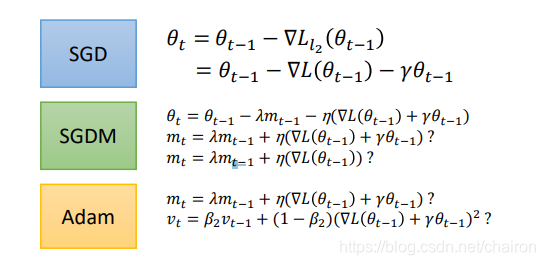
SGDM、Adam是否忽略最后那个小尾巴呢? - 实验表明:SGDM忽略---->SGDWM
- Adam不忽略,要考虑------->AdamW

6 有助于优化的一些点
- 增加数据集的随机性,尽可能让机器多探索
- 让模型更优耐心


summary
| Team SGD | Team Adam |
|---|---|
| SGD、SGDM、Learning rate scheduling、 NAG、SGDWM | Adagrad、 RMSProp、Adam、AMSGrad、 AdaBound(取学习率的极端值)、 Learning rate scheduling、RAdam、Nadam、AdamW |
| SGDM | Adam |
|---|---|
| 慢;更好的收敛性;稳定;更小的泛化误差 | 快;可能不会收敛;不稳定;更大的泛化误差 |
| 应用于计算机视觉、图像分类、图像切割、目标检测 | 应用于NLP、QA、机器翻译、 语音合成、GAN、增强学习 |

















 612
612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









