




 本文详细介绍了大数据生态系统的数据生命周期,重点讲解了Hadoop的核心组件,包括HDFS的分布式存储系统、MapReduce并行计算框架以及数据分析工具。HDFS的NameNode、DataNode和SecondaryNameNode的角色被阐述,同时MapReduce的工作流程、MapReduce1.0与Yarn的对比以及Yarn的角色和交互也进行了深入解析。此外,还提到了MapReduce编程模型中的shuffle过程、MapTask和ReduceTask的执行流程,以及如何在Hadoop上提交和运行应用程序。
本文详细介绍了大数据生态系统的数据生命周期,重点讲解了Hadoop的核心组件,包括HDFS的分布式存储系统、MapReduce并行计算框架以及数据分析工具。HDFS的NameNode、DataNode和SecondaryNameNode的角色被阐述,同时MapReduce的工作流程、MapReduce1.0与Yarn的对比以及Yarn的角色和交互也进行了深入解析。此外,还提到了MapReduce编程模型中的shuffle过程、MapTask和ReduceTask的执行流程,以及如何在Hadoop上提交和运行应用程序。
预备知识
1.大数据生态系统

-
数据生命周期
数据采集,传输,接收,预处理,存储和索引,数据分析与挖掘,可视化与决策。 -
3个核心组件(基础大数据)
- (HDFS)分布式存储系统:
- 统一的存储命名空间
- 据以分块备份的方式保存,数据备份可以达到高可靠性,数据分块实现并行I/O达到高性能
- namenode:目录树、属性
- datanode:实际存储
- secondary namenode:namenode的备份
- datanode和namenode可以相互连接,目录树和文件是分开的。
- 并行计算框架:MapReduce、Tez、Spark和Flink
-
避免多次启动
任务划分 调度(错误处理) 进度监控 -
核心:
任务调度、负责均衡、和错误处理。
-
- 数据分析工具与算法库:SQL on Hadoop
- (HDFS)分布式存储系统:
HDFS安装配置:基础知识
-
系统栈
纵向:下层向上层提供服务 横向:网络进行传输(IP+端口号) -
Hadoop的目录结构

“Hadoop namenode -format”命令用于对集群进行初始化; “start-dfs.sh”和“stop-dfs.sh”为启动和停止集群的脚本。 $HADOOP_HOME/bin:可执行命令所在文件 $HADOOP_HOME/sbin:用于启动停止相关组件如HDFS、MapReduce和Yarn(安全的可执行命令所在文件) $HADOOP_HOME/etc/hadoop:配置文件所在位置 $HADOOP_HOME/logs目录:该目录存放的是Hadoop运行的日志 -
HDFS介绍

NameNode:Master节点,管理HDFS的名称空间和数据块映射 信息,配置副本策略,处理客户端请求。
DataNode:Slave节点,存储实际的数据,汇报存储信息给NameNode。
Secondary NameNode:辅助NameNode,分担其工作量;紧急情况下,可辅助恢复NameNode
Client:切分文件;访问HDFS;与NameNode交互,获取文件位置信息;与DataNode交互,读取和写入数据。
Hadoop安装配置
- 在主节点上安装jdk、Hadoop(可以通过Xftp传输安装包到虚拟机上,进行解压)
- 复制虚拟机为从节点,修改ip地址映射
- 配置免密登录(每个节点都生成密钥,公钥;然后把公钥追加到authourized key文件里,再分发到各个节点)
- 配置环境(横向配置、纵向配置)
- 初始化Hadoop、启动
- 登录网页查看Hadoop的信息
MapReduce编程模型
1.MapReduce编程模型-wordcount(单词计数)

方框:数据
箭头:网络传输
椭圆:计算任务
—
- shuffling:多对多的映射->以字母序归类单词到reduce(B、C、D、开头分别划分到不同reduce)
2.MapReduce编程模型-sort(排序)

- Map任务有4个,Reduce任务有2两个。都是在对数据块进行排序。
- Map:块间无序,块内无序–>块间无序,块内有序
- reduce:块间有序,块内无序–>块间有序,块内有序
3.MapReduce1.0工作流程

- JobTracker(集群瓶颈)
- 资源分配:某个应用程序多少CPU和内存
- 任务调度:根据数据划分来启动计算任务
- 作业进度监控等功能。
- TaskTracker
- 负责启动本地的Map任务和Reduce任务,Map任务和Reduce任务向TaskTracker汇报执行进度,TaskTracker向JobTracker汇报节点状态,任务执行进度。
( Map任务和Reduce任务–>TaskTracker–>JobTracker)
- 负责启动本地的Map任务和Reduce任务,Map任务和Reduce任务向TaskTracker汇报执行进度,TaskTracker向JobTracker汇报节点状态,任务执行进度。
4.Yarn工作流程

(HDFS、mapreduce、yarn主从节点)
-
以ResourceManager为中心
client提交、namenode汇报、appmaster申请资源 -
Yarn的角色有ResourceManager、和NodeManager。
其中ResourceManager负责资源的分配 AppMaster(ApplicationMaster)负责任务的调度 NodeManager负责节点资源的管理。
MapRedcue1.0 和Yarn的对比

MapReduce1.0和Yarn模式下资源分配方式

| Slot | Container |
|---|---|
| mapreduce | yarm |
| Map Slot只能启动Map 任务,ReduceSlot只能启动Reduce任务。 | 容器不分类型,既可以启动Map任务,也可以启动Reduce任务 |
| 静态配置,资源大小相同,资源量无法改变 | Container大小可以动态调整 |
| 集群启动时进程 | 执行任务时增加进程 | |
|---|---|---|
| MapReduce | JobTracker 、TaskTracker | MapTask、ReduceTask |
| Yarn | ResourceManager、NodeManager | ApplicationTask、MapTask、ReduceTask |
Yarn的基本配置(一)
一、预备知识
1.Yarn的角色和交互

ResourceManager交互:Client、NodeManager、AppMaster(ApplicationMaster)
task最先退出
二、Yarn的基本配置



相互声明、配置端口
Mapreduce:
- Map函数:Map函数的接口由框架确定,输入为一组(key, Value), 但具体逻辑由用户自己实现。Map函数会被Map任务反复调用。
- map任务:第一,数据准备。读取一个block的数据为输入,将其转化为1组【key,value】第二,具体执行。反复调用map函数,将【key,value】作为map函数的输入参数,遍历每组key,value。第三,搜集结果,保存map函数的输出。
- map阶段:是MapReduce编程模型的一部分,是数据处理流程逻辑上的功能划分,逻辑上对应数据读取,数据处理、数据结果保存等三部分功能。具体工作由Map任务实现。
- Block和Split的关系:Block对一个文件进行物理划分,逻辑上相邻的两个Block一般存储在不同DataNode上;Split对一个文件进行逻辑划分,每个Split记录了自身在文件中的起止偏移量,并不存在一对一的物理实体。
- 在逻辑上Split可以大于,小于或等于一个Block;一个文件也可以只划分为一个Split。这也意味着每个Map的输入可以是Block的一部分,也可以是整个文件。一般情况下,一个Split对应一个Block。
shuffle过程
而Shuffle过程的功能就是将M个Map任务的输出按一定的规则通过网络拷贝到N个Reduce任务端。
Shuffle过程是一个多对多的映射过程
Map 任务可以细分为五个步骤,分别为: Read,Map,Collect,Spill和Combine阶段
Reduce任务也可以细分为五个步骤,分别是Shuffle/copy,Merge,Sort,Reduce和Write阶段。
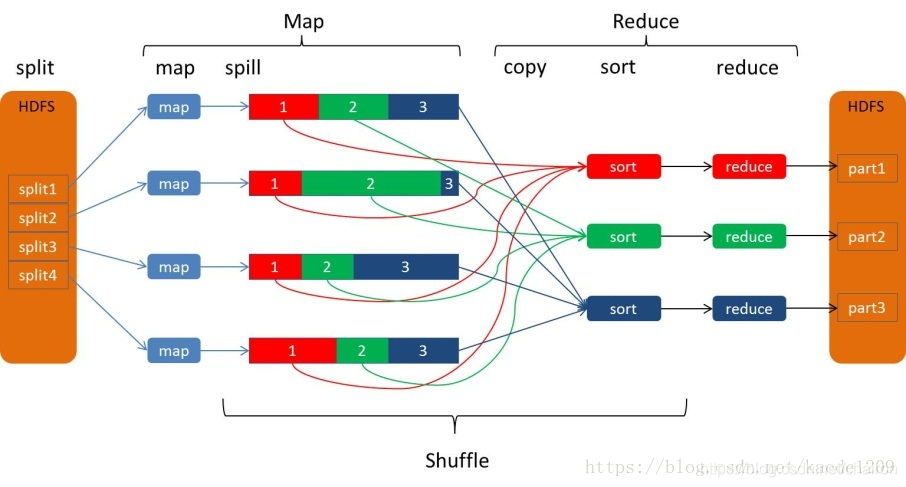
-
Map的shuffle过程:
- Spill过程包括输出、排序、溢写、合并等步骤,如图所示:
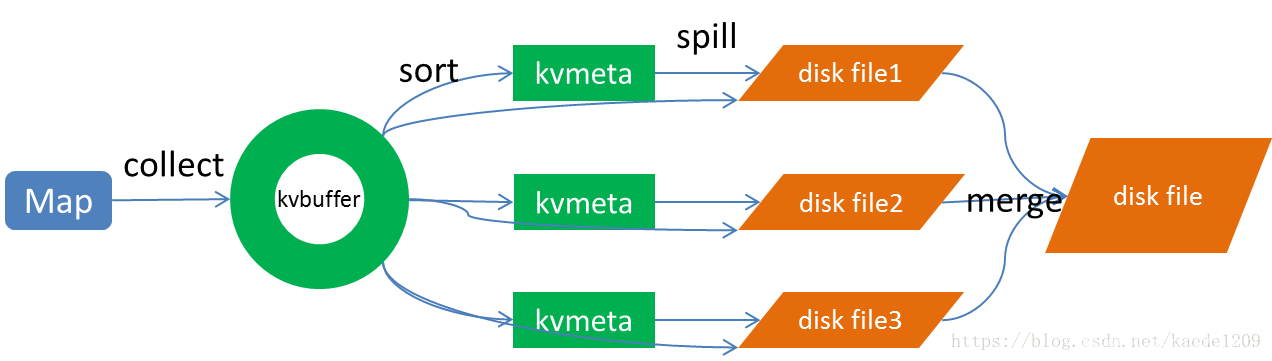
- Spill过程包括输出、排序、溢写、合并等步骤,如图所示:
-
collect:
-
sort
-
Spill(partition:分区):当map task的输出结果很多时,就可能会撑爆内存,所以需要在一定条件下将缓冲区中的数据临时写入磁盘,然后重新利用这块缓冲区。这个从内存往磁盘写数据的过程被称为Spill,中文可译为溢写。比例默认是0.8,也就是当缓冲区的数据已经达到阈值(buffer size * spill percent = 100MB * 0.8 = 80MB),溢写线程启动,锁定这80MB的内存,执行溢写过程。Map task的输出结果还可以往剩下的20MB内存中写,互不影响。
-
merge(group):Map任务如果输出数据量很大,可能会进行好几次Spill,out文件和Index文件会产生很多,分布在不同的磁盘上。最后把这些文件进行合并的merge过程闪亮登场。
Reduce的shuffle过程:
-
Copy:
- Reduce 任务通过HTTP向各个Map任务拖取它所需要的数据。每个节点都会启动一个常驻的HTTP server,其中一项服务就是响应Reduce拖取Map数据。当有MapOutput的HTTP请求过来的时候,HTTP server就读取相应的Map输出文件中对应这个Reduce部分的数据通过网络流输出给Reduce。
-
Merge SORT:
- 这里使用的Merge和Map端使用的Merge过程一样。Map的输出数据已经是有序的,Merge进行一次合并排序,所谓Reduce端的 sort过程就是这个合并的过程。一般Reduce是一边copy一边sort,即copy和sort两个阶段是重叠而不是完全分开的。
当Reducer的输入文件已定,整个Shuffle才最终结束
Map任务和Reduce任务的执行过程
Map Task的执行流程
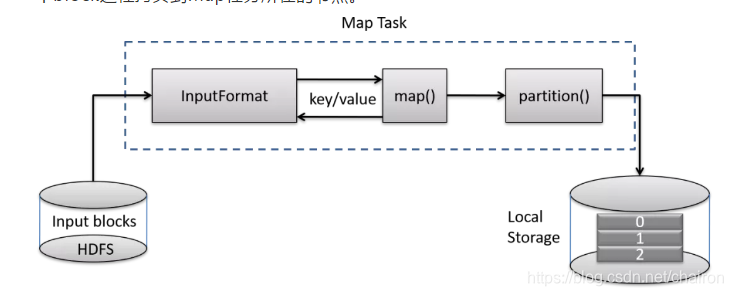
- 1、Map Task先根据split的信息确定底层的数据块block,然后将block数据读入内存迭代解析成一个个key/value对;
- 2、针对这些key/value对,依次调用用户自定义的map()函数进行处理,函数的输出是一组新的key/value对;
- 3、partition()函数根据新的key值将数据进行分区,所有数据都被保存在Map任务所在节点的本地磁盘上。
- 每个分区的数据将被一个Reduce任务处理。如图所示,Map任务的输出被分为了3个分区,意味着这个程序启动了3个Reduce任务。
Reduce Task的执行流程
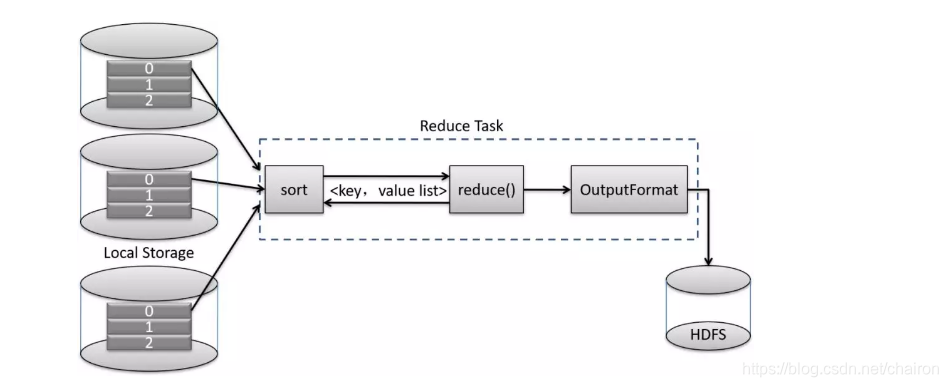
- 1、copy:拷贝远程节点上所有MapTask的中间数据,拷贝每个Map任务的一个对应分区。如图所示,该Reduce任务只拷贝每个Map任务输出数据的0号分区;
2、sort(group):针对来自所有Map任务的数据,按照key对key/value进行排序,在排序过程中同时完成聚集操作,形成很多新的键值对<key, value list>;
3、reduce()函数:依次读取<key, value list>调用用户自定义的reduce()函数,并将最终结果保存到HDFS上。
如何提交应用程序-以wordcount为例
Q:如何判断文件在本地还是HDFS?
A:HDFS的文件在每个节点上都可以看到。
几个常见的HDFS操作命令(考)

logs:用户节点名、节点名、当前角色名 决定了一个日志文件。
hadoop fs -mkdir -p --所创建的目录如果父目录不存在就创建该父目录
*.txt:表示全部txt文件.
- 首先要启动HDFS集群和Yarn集群
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-dfs.sh - 进入$HADOOP_HOME目录,创建要上传的可执行文件( vi input1.txt、 vi mapper.py vi reducer.py)
- HDFS上创建输入路径(test/input ),上传数据
hdfs dfs -mkdir /test
hdfs dfs -mkdir /test/input
hdfs dfs -copyFromLocal input1.txt /test/input - 执行程序
进入$HADOOP_HOME目录,执行以下命令:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar
wordcount
/test/input
/test/output - 查看计算结果
- 查看结果目录
hdfs dfs -ls /test/output - 查看最终结果
hdfs dfs -cat /test/output/part-r-00000
- 查看结果目录
- 在Yarn中查看程序信息
MapReduce编程模型(二)-认识三组Key和Value

Map任务将Block变成多个[K1, V1]形式,此处[K1, V1]为Map函数的输入参数,[K2,V2]为Map函数的输出参数。
Shuffle操作通过分组Group操作,会将key相同(此处比较K2的值)的[K2, V2]组合聚集到一起,形成[K2, {V2,…}],此处{…}为V2的集合。
Reduce任务以[K2, {V2,…}]为输入,对{V2,…}进行聚合操作形成V3。

[K1, V1] 分别对应[文件偏移量,一行文本字符串];[K2, V2]分别对应[单个单词,单词出现的次数];[K2, {V2,…}]对应着[单个单词,次数的集合(来自每个Map任务)]。
按照(Key,Value)的值域来比较,验证了该结论:
K1不等于K2,V1不等于V2;
K3等于K2,V3等于V2
作业
- 第10周: ppt答辩大作业准备情况、集群使用情况、工作情况。
- 期末:
-
欧空间的轨迹聚类
给一个轨迹,找出最近的5个车辆轨迹 -
3DR tree–>GPS轨迹
时间、经纬度、车牌号-->获得轨迹
-
- 组内自评、小组互评。一人讲ppt,一人打分(A/B/C/D/E)
杂七杂八
HDFS:
-
资源管理(全局统一的环境变化) :spark
集群中每一个节点都能看到相同的目录树和文件路径, 某一节点对目录树的修改(如增加或删除数据),任何其它节点都可以同步感知这个变化。 -
并行计算框架:yarm、flink、
-
百度:
爬虫、倒排索引、分词、 -
并行计算框架:
资源分配 任务调度 错误处理 -
资源分配的单位:
虚拟机(大)、docker:轻量级虚拟化技术(中)、进程、线程(小)、

















 1169
1169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









