







 本文深入探讨了CART(Classification And Regression Trees)决策树算法,包括其在分类和回归任务中的应用。CART算法使用基尼指数进行特征选择,建立二叉树模型,简化了ID3和C4.5算法中的复杂度。CART分类树通过基尼指数最小化选择最佳属性,而CART回归树则采用平方误差最小准则。此外,文章还介绍了CART树的剪枝算法,通过交叉验证选择最佳剪枝策略,以提高模型的泛化能力。
本文深入探讨了CART(Classification And Regression Trees)决策树算法,包括其在分类和回归任务中的应用。CART算法使用基尼指数进行特征选择,建立二叉树模型,简化了ID3和C4.5算法中的复杂度。CART分类树通过基尼指数最小化选择最佳属性,而CART回归树则采用平方误差最小准则。此外,文章还介绍了CART树的剪枝算法,通过交叉验证选择最佳剪枝策略,以提高模型的泛化能力。
文章目录
上一篇文章中,讲解了ID3决策树及C4.5决策树,但是特们仍有许多不足:比如模型是用较为复杂的熵来度量,使用了相对较为复杂的多叉树,只能处理分类不能处理回归等。对于这些问题, CART算法大部分做了改进。由于CART算法可以做回归,也可以做分类,我们分别加以介绍,先从CART分类树算法开始,重点比较和C4.5算法的不同点。接着介绍CART回归树算法,重点介绍和CART分类树的不同点。然后我们讨论CART树的建树算法和剪枝算法,最后总结决策树算法的优缺点。
一、CART树原理
CART 全称为 Classification And Regression Trees,即分类回归树。顾名思义,该算法既可以用于分类还可以用于回归。
克服了 ID3 算法只能处理离散型数据的缺点,CART 可以使用二元切分来处理连续型变量。二元切分法,即每次把数据集切分成两份,具体地处理方法是:如果特征值大于给定值就走左子树,否则就走右子树。对 CART 稍作修改就可以处理回归问题。先前我们使用香农熵来度量集合的无组织程度,如果选用其它方法来代替香农熵,就可以使用树构建算法来完成回归。
与ID3决策树及C4.5决策树一样,CART是决策树的一种,主要由特征选择,树的生成和剪枝三部分组成。它主要用来处理分类和回归问题,下面对分别对其进行介绍。
本部分将构建两种树,第一种是分类树;第二种是回归树。
二、CART分类树
2.1 特征选择
CART分类树使用基尼指数最小化准则来选择最佳属性。
ID3算法使用了信息增益来选择特征,信息增益大的优先选择。C4.5算法采用了信息增益比来选择特征,以减少信息增益容易选择特征值多的特征的问题。但是无论是ID3还是C4.5,都是基于信息论的熵模型的,这里面会涉及大量的对数运算。因此,我们希望有一种方法简化模型同时又不至于完全丢失熵模型的优点,这就是基尼系数。CART分类树算法使用基尼系数来代替信息增益比,基尼系数代表了模型的不纯度,基尼系数越小,则不纯度越低,特征越好。这和信息增益(比)是相反的。
在分类问题中,假设有K个类别,第k个类别的概率为 p k p_k pk, 则基尼系数的表达式为:
G i n i ( p ) = ∑ k = ∑ k = 1 K p k ( 1 − p k ) = 1 − ∑ k = 1 K p k 2 Gini(p)=∑k=\sum_{k=1}^{K}p_k(1−p_k)=1-\sum_{k=1}^{K}p^2_k Gini(p)=∑k=k=1∑Kpk(1−pk)=1−k=1∑Kpk2
如果是二类分类问题,计算就更加简单了,如果属于第一个样本输出的概率是p,则基尼系数的表达式为:
G i n i ( p ) = 2 p ( 1 − p ) Gini(p)=2p(1−p) Gini(p)=2p(1−p)
对于个给定的样本D,假设有K个类别, 第k个类别的数量为 C k C_k Ck,则样本D的基尼系数表达式为:
G i n i ( D ) = 1 − ∑ k = 1 K ( ∣ C k ∣ ∣ D ∣ ) 2 Gini(D)=1-\sum_{k=1}^{K}(\frac{|C_k|}{|D|})^2 Gini(D)=1−k=1∑K(∣D∣∣Ck∣)2
特别的,对于样本D,如果根据特征A的某个值a,把D分成D1和D2两部分,则在特征A的条件下,D的基尼系数表达式为:
G i n i ( D , A ) = ∣ D 1 ∣ ∣ D ∣ G i n i ( D 1 ) + ∣ D 2 ∣ ∣ D ∣ G i n i ( D 2 ) Gini(D,A)=\frac{|D_1|}{|D|}Gini(D_1)+\frac{|D_2|}{|D|}Gini(D_2) Gini(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
其中:
- Gini(D):表示集合D的不确定性。
- Gini(A,D):表示经过A=a分割后的集合D的不确定性。
对比基尼系数表达式和熵模型的表达式,二次运算要比对数简单很多,尤其是二类分类的计算,更加简单。但是简单归简单,和熵模型的度量方式比,基尼系数对应的误差有多大呢?对于二类分类,基尼系数和熵之半的曲线如下:
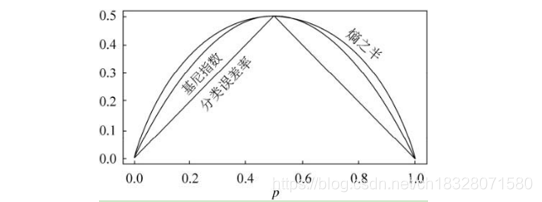
从上图可以看出,基尼系数和熵之半的曲线非常接近,仅仅在45度角附近误差稍大。因此,基尼系数可以做为熵模型的一个近似替代。而CART分类树算法就是使用的基尼系数来选择决策树的特征。同时,为了进一步简化,CART分类树算法每次仅仅对某个特征的值进行二分,而不是多分,这样CART分类树算法建立起来的是二叉树,而不是多叉树。这样一可以进一步简化基尼系数的计算,二可以建立一个更加优雅的二叉树模型。
2.2 建立流程
算法从根节点开始,用训练集递归的建立CART树。
- 1)对于当前节点的数据集为D,如果样本个数小于阈值或者没有特征,则返回决策子树,当前节点停止递归。
- 2)计算样本集D的基尼系数,如果基尼系数小于阈值,则返回决策树子树,当前节点停止递归。
- 3)计算当前节点现有的各个特征的各个特征值对数据集D的基尼系数。
- 4)在计算出来的各个特征的各个特征值对数据集D的基尼系数中,选择基尼系数最小的特征A和对应的特征值a。根据这个最优特征和最优特征值,把数据集划分成两部分D1和D2,同时建立当前节点的左右节点,做节点的数据集D为D1,右节点的数据集D为D2.
- 5)对左右的子节点递归的调用1-4步,生成决策树。
对于生成的决策树做预测的时候,假如测试集里的样本A落到了某个叶子节点,而节点里有多个训练样本。则对于A的类别预测采用的是这个叶子节点里概率最大的类别。
2.3 连续特征和离散特征的处理
1)、连续特征的处理
对于CART分类树连续值的处理问题,其思想和C4.5是相同的,都是将连续的特征离散化。唯一的区别在于在选择划分点时的度量方式不同,C4.5使用的是信息增益比,则CART分类树使用的是基尼系数。
具体的思路如下,比如m个样本的连续特征A有m个,从小到大排列为 a 1 , a 2 , . . . , a m a_1,a_2,...,a_m a1,a2,...,am,则CART算法取相邻两样本值的平均数,一共取得m-1个划分点,其中第i个划分点 T i T_i Ti表示为: T i = a i + a ( i + 1 ) 2 Ti=\frac{a_i+a_{(i+1)}}{2} Ti=2a
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









