




文章目录
前言
检索增强生成(RAG:Retrieval-Augmented Generation),LangChain官网上说:RAG是一种技术,可以通过将其与外部知识库结合来增强大语言模型。RAG 解决了模型的一个关键限制:模型依赖固定的训练数据集,这可能导致信息过时或不完整。当给定一个查询时,RAG 系统首先会在知识库中搜索相关信息。然后,系统将检索到的信息整合到模型的提示中。模型利用提供的上下文来生成对查询的响应。通过弥合大语言模型与动态、有针对性的信息检索之间的鸿沟,RAG 是一种构建更强大、更可靠的 AI 系统的强大技术。
一、基本概念
RAG包含两个主要组件:
- 检索器(
Retriever):从知识库中检索相关信息或文档。 - 生成器(
Generator):将检索到的信息传递给大模型生成回答。
二、业务流程
上面定义中说到,RAG依赖知识库来进行检索,所以检索前就需要先构建好知识库,于是业务实现中就有了知识构建和用户对话这两个部分,如下:
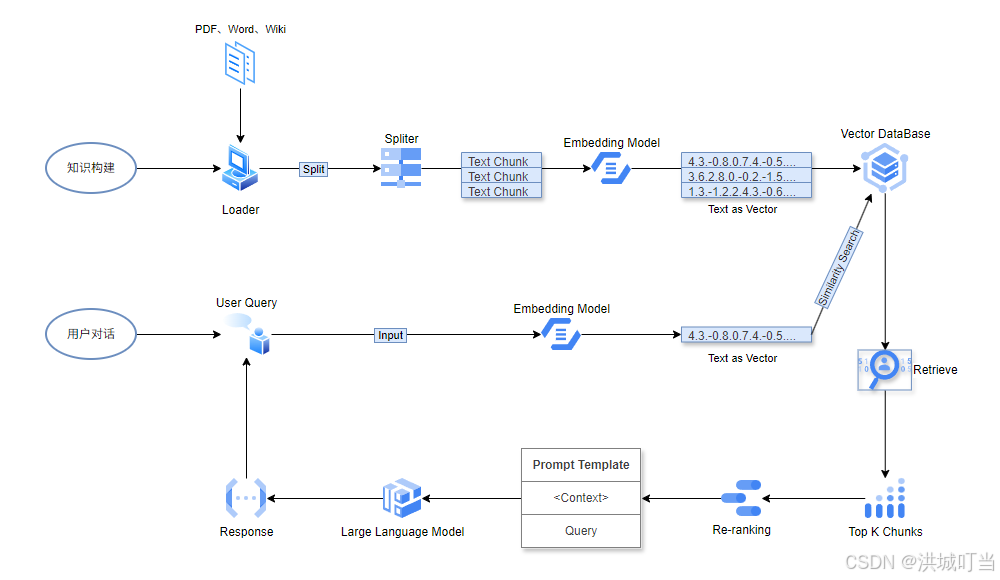
1、知识构建
知识库的构建需要用到文档加载器(Loader)、数据分割器(Spliter)、向量嵌入模型(Embedding)和向量数据库(Vector DataBase)这几个组件和服务。
- 文档加载器:
LangChain集成了丰富的文档加载器,包含对各种文件的读取支持。本文使用TextLoader加载本地文本文件来做测试说明,当然也可以使用WebBaseLoader来加载网页。在langchain安装目录的document_loaders目录中可以看到所有支持的的文档加载器。 - 数据分割器:常见的基于文本结构,自然地组织成段落、句子和单词等层次单元。利用这种内在结构来指导我们的分割策略,创建能够保持自然语言流畅性、保持分割内部语义连贯性并适应不同粒度文本的分割。
LangChain的RecursiveCharacterTextSplitter实现了这一概念。在langchain安装目录的text_splitter文件中定义了对数据分割器的集成支持。 - 向量嵌入模型:
LangChain中的向量嵌入模型接口定义在其安装目录的embeddings目录中,这里我们选用FastEmbedEmbeddings来做说明。 - 向量数据库:
LangChain中集成了众多的数据存储服务接口,定义在了其安装目录的vectorstores文件夹下。本文选用最简单的FAISS向量数据库来做测试。
2、用户对话
用户发起对话,输入查询问题,系统通过向量嵌入模型将查询问题生成向量,然后送往向量数据库服务做余弦相似度检索,通过Top-K指定召回的文档块(Chunk)数量。此外,还可以使用重排序模型(RankLLM)对检索结果进行重新排序(本文将不涉及)。LangChain中关于Rerank的支持接口定义在langchain_community安装目录下的document_compressors目录里面。
将检索返回的文档块组合成文本后放入到提示词模板(Prompt Template)中,作为上下文内容提供给大语言模型(LLM)。最后将由大语言模型将回答结果返回给用户。
三、实现步骤
1、安装开发依赖
1.1、安装LangChain包
官方说:LangChain 是一个用于开发由大型语言模型(LLMs)驱动的应用程序的框架。简单理解就是一个集成工具包,除了提供一些开源的工具组件外,还集成了一大批第三方大型语言模型及相关技术(如嵌入模型和向量存储),实现了标准接口。
langchain:主框架和标准组件。这是最常用的包,包含了核心的抽象、标准实现和常用工具。langchain-core:核心抽象和基础。包含了最基本的接口(如BaseChatModel,BaseRetriever)、核心概念(如Messages,Documents)和基础运行时(如Runnable协议)。其他包都构建于此之上。多数情况下,只需要直接安装langchain包。它会自动安装langchain-core作为依赖。langchain-community:第三方集成。包含了所有与第三方服务(如OpenAI,Anthropic,Pinecone,Chroma等)的集成代码。这些集成由社区维护,稳定性可能不如核心包。
使用Pip安装:
pip install --upgrade langchain langchain-community
1.2、安装其它依赖包
- 嵌入模型:我们使用
Qdrant FastEmbedding,LangChain中定义的FastEmbedEmbeddings,要使用这个类需要安装fastembed的Python包,如下:
pip install --upgrade fastembed
- 向量数据库:文中使用
FAISS向量数据库,同样的,需要安装faiss-cpu这个Python包,如下:
pip install --upgrade faiss-cpu
- 大模型依赖:文中大语言模型使用智谱AI,根据
LangChain文档说明,需要安装httpxhttpx-ssePyJWT这几个Python代码包,如下:
pip install --upgrade httpx httpx-sse PyJWT
2、构建数据知识库
2.1、文档数据加载
准备一个普通的文本文件,如:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2122
2122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









