







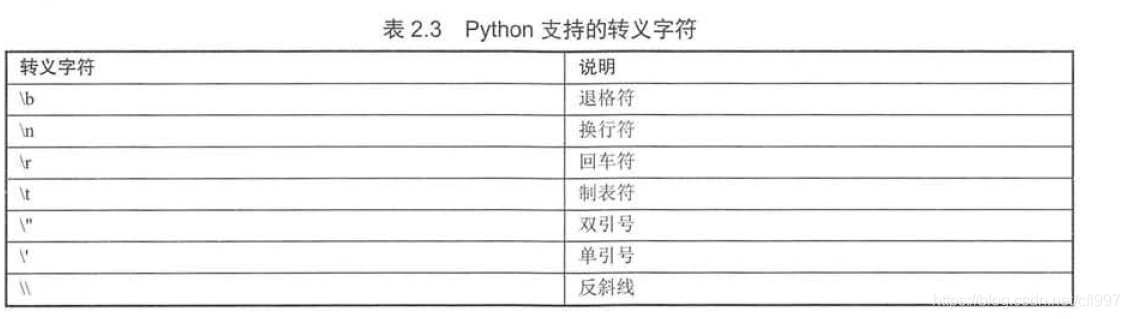
- 注释;单行注释和多行注释
- 弱类型语言
- 变量的特征
- 变量命名规则
- 关键字和内置函数
- 支持的各种数值类型
- 字符串入门
- 拼接字符串的方法
- repr 和字符串
- 使用input 和raw_input 获取用户输入
- 长字符串和原始字符串
- 字节串
- 宇符串格式化
- 字符串的相关方法
注释;单行注释和多行注释
单行用“#” ;多行用三个单引号或三个双引号。
弱类型语言
Python 是弱类型语言,弱类型语言有两个典型特征。
〉变量无须声明即可直接赋值: 对一个不存在的变量赋值就相当于定义了一个新变量。
〉变量的数据类型可以动态改变:同一个变量可以一会儿被赋值为整数值, 一会儿被赋值为
字符串。
a=5
print(a)即可
当然字符串也可
s='hello'
print(s)
name='cfl997'
age='20'
print("user:",name,"age:",age)变量命名规则
Python 语言的标识符必须以字母、下画线(_)开头,后面可以跟任意数目的字母、数字和下画线(_)。此处的字母并不局限于26 个英文字母,可以包含中文字符、日文字符等。
关键字和内置函数
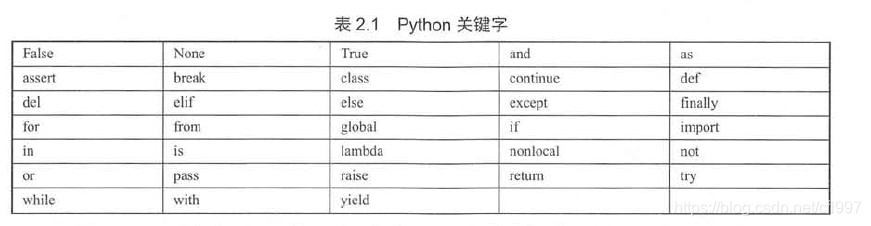
可以导入keyword模块显示所有关键字
>>> import keyword
>>> keyword.kwlist
支持的各种数值类型
在python中不用定义int,float,double。直接赋值。
整型:
也包括十进制;二进制0b或0B;八进制0o或0O;以及十六进制0x或0X;
python整型支持None值(空值)
a=None
浮点型:
科学计数:3.14e2(即3.14*10^2)#e或E都可
复数:
虚部用j或J表示
字符串入门
拼接字符串的方法
repr 和字符串
用一个例子来表示复数以及字符串的使用:
举个栗子:
import cmath
a1=3+0.2j
print(a1)
print(type(a1))
a2=4-0.1j
print(a2)
print(a2+a1)
a3=cmath.sqrt(-1)
print(a3)
s1="价格"
price=1.3
print(s1+repr(price))
print(s1+str(price+100))
输出结果:
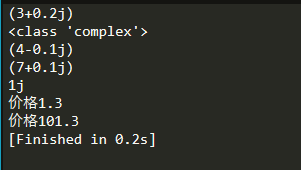
其中print(type(a1))是输出a1的类型;
“+”作为字符串的拼接运算符;
由于价格是数字,需要将数值转换成字符串;
可以用str()或repr();
注:str是python的内置类型。repr则只是一个函数。
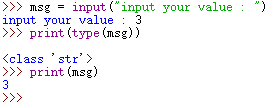
使用input 和raw_input 获取用户输入
用python3.X则直接使用input即可;
长字符串和原始字符串
用转义字符(\)对换行符进行转义;
原始字符串以“r”开头,原始字符串不会把'\'当成特殊字符;
可以直接写出路径;
s1=r'C:\python\code\20191106\2.4'
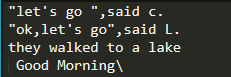
print(s1)s='''"let's go ",said c.
"ok,let's go",said L.
they walked to a lake'''
print(s)
s1=r' Good Morning''\\'
print (s1)
以下是python支持的转义字符
s2='name \t\tprice'
s3='Crazy\t\t108'
print(s2)
print(s3)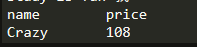
字节串(bytes)
- bytes 对象只负责以宇节(二进制格式)序列来记录数据,至于这些数据到底表示什么内容,完全由程序决定。
- 如果采用合适的字符集, 字符串可以转换成字节串;反过来,宇节串也可以恢复成对应的字符串。
- 调用bytes()函数将字符串按指定字符集转换成字节串,如果不指定字符集,默认使用UTF - 8 字符集。
- 调用字符串本身的encode()方法将字符串按指定宇符集转换成字节串,如果不指定字符集,默认使用UTF- 8 字符集。
创建一个空的types
一个空的types值
指定字符是types的值
b1=bytes()
b2=b''
b3=b'hello'
print(b1)
print(b2)
print(b3)
print(b3[0])
print(b3[2:4])
b4=bytes('hello 我',encoding='utf-8')
print(b4)
b5="study is fun 我".encode('utf-8')
print(b5)
st=b5.decode('utf-8')
print(st)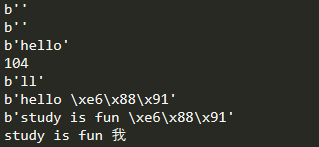
宇符串格式化
Python 提供了“%”对各种类型的数据进行格式化输出,例如
price=108
print("the book's price is %s "%price)
user="Cao"
age=20
print("%s is a %s years old "%(user,age))
字符串的相关方法
- 字符串格式化:%
- 序列相关方法,在[]中
- 计算字符串长度:len
- in 运算符判断是否包含某个子串
- str大小写:title、lower、upper
- 删除空白:strip、lstrip、rstrip
- 删除指定字符
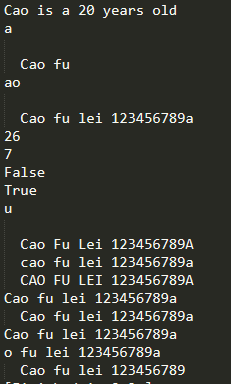
user="Cao"
age=20
print("%s is a %s years old "%(user,age))
#序列相关方法用[]中使用索引。负数为倒数
string=' Cao fu lei 123456789a '
print(string[3])
print(string[-1])
print(string[0:9])
print(string[3:5])
print(string[-3:-1])
print(string[0:])
#计算长度
print(len(string))
print(len('123454a'))
#in用来判断是否包含某个子串
print('very' in string)
print('9' in string)
#最大的字符以及最小的字符
print(max(string))
print(min(string))
#将每个单词搜字母改为大写
print(string.title())
#将整个字符串小写
print(string.lower())
#将整个字符串大写
print(string.upper())
#删除空白
#删除左边空白
print(string.lstrip())
#删除右边空白
print(string.rstrip())
#删除左右空白
print(string.strip())
#删除字符串前后指定字符
print(string.lstrip('Cfa '))#空格也需要删,才有效果
print(string.rstrip('Cfa '))
查找替换分割
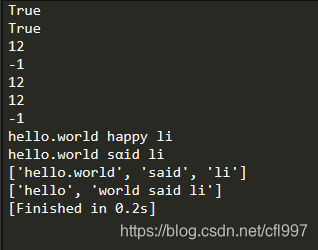
s='hello.world said li'
#判断以指定子串开头
print(s.startswith('hello'))
#判断以指定子尾开头
print(s.endswith('li'))
#判断查找所在位置
print(s.find('said'))
#没有则输出-1
print(s.find('happy'))
#查找位置,没有报错
print(s.index('said'))
#print(s.index('happy'))
#从第几个位置查找
print(s.find('said',9))
print(s.find('said',13))
#将said替换成happy
print(s.replace('said','happy'))
#指定的翻译映射表进行字符替换
table={97:945}
print(s.translate(table))
#分割成多个短语
print(s.split())
print(s.split('.'))



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











