




“欧米伽未来研究所”关注科技未来发展趋势,研究人类向欧米伽点演化过程中面临的重大机遇与挑战。将不定期推荐和发布世界范围重要科技研究进展。(关于欧米伽点)
9 月 12 日,OpenAI 正式公开一系列全新 AI 大模型,旨在专门解决难题。这是一个重大突破,新模型可以实现复杂推理,一个通用模型解决比此前的科学、代码和数学模型能做到的更难的问题。本报告主要来自Open AI 公司发布的研究报告汇总。主要包括四个部分,分别是:
1.OpenAI o1 是如何通过思维链实现推理
2.OpenAI o1前沿风险评估报告
3.关于OpenAI o1-preview
4.关于OpenAI o1-mini
对于OpenAI o1 是如何通过思维链实现推理和取得的成果,OpenAI 提到,
‘’我们正在推出 OpenAI o1,一种通过强化学习训练的大型语言模型,能够执行复杂推理任务。o1 在回答之前会进行深思熟虑——它可以在回复用户前产生一条长的内部思维链。
OpenAI o1 在编程竞赛问题(Codeforces)中排名第 89 百分位,在美国数学奥林匹克预选赛(AIME)中位列美国前 500 名学生之中,并且在物理、生物和化学问题的基准测试(GPQA)上超越了人类博士水平的准确性。虽然要使这个新模型像当前模型一样易于使用还需要进一步努力,但我们已发布该模型的早期版本 OpenAI o1-preview,供 ChatGPT 和部分受信任的 API 用户立即使用。
我们的大规模强化学习算法通过高度数据高效的训练过程教会模型如何利用其思维链进行有效思考。我们发现,o1 的性能在接受更多强化学习(训练计算时间)和更多思考时间(测试计算时间)后会持续提升。这种方法的扩展性与 LLM 预训练的扩展性有显著不同,我们正在继续研究其中的差异。
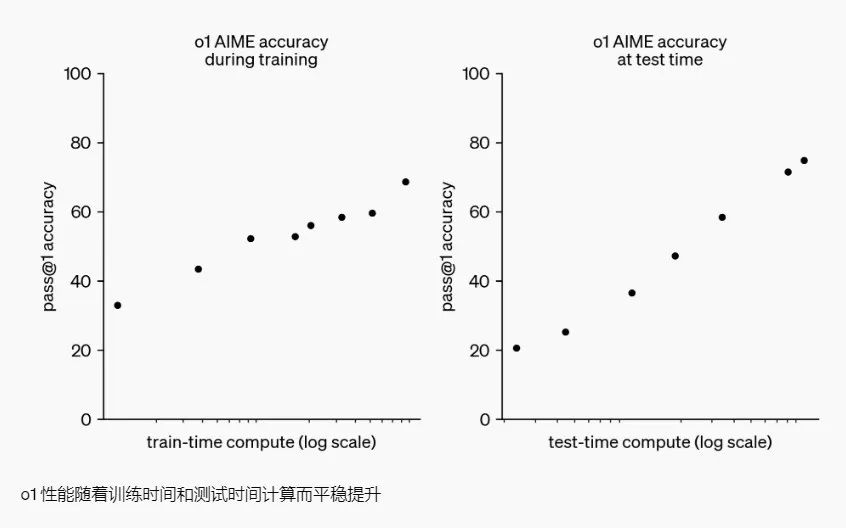
在许多重推理的基准测试中,o1 的表现可以与人类专家媲美。最近的前沿模型在 MATH 和 GSM8K 上表现如此出色,以至于这些基准测试已经无法有效区分不同模型。我们评估了 o1 在 AIME(美国数学奥林匹克预选赛)上的数学表现,该考试专为挑战美国最优秀的高中数学学生而设计。在 2024 年的 AIME 考试中,GPT-4o 平均仅解决了 12%(1.8/15)的问题,而 o1 单次样本的平均成绩为 74%(11.1/15),通过 64 个样本达成共识后成绩为 83%(12.5/15),通过用学习得来的评分函数重新排序 1000 个样本后得分为 93%(13.9/15)。13.9 分的成绩使其跻身全美前 500 名学生之列,并超过了参加美国数学奥林匹克竞赛(USA Mathematical Olympiad)的分数线。
我们还在 GPQA-diamond 上评估了 o1,这是一个困难的智力基准,测试的是化学、物理和生物学方面的专业知识。为了将模型与人类进行比较,我们招募了拥有博士学位的专家来回答 GPQA-diamond 的问题。结果发现,o1 超过了这些人类专家的表现,成为第一个在该基准测试上超越人类的模型。这些结果并不意味着 o1 在所有方面都比博士更有能力——只是在某些博士被期望解决的问题上,模型表现更为出色。在其他几个机器学习基准测试上,o1 也优于现有的最先进模型。开启视觉感知功能后,o1 在 MMMU 上得分为 78.2%,成为第一个能够与人类专家竞争的模型。它还在 57 个 MMLU 子类别中的 54 个上超过了 GPT-4o。
思维链 类似于人类在回答一个困难问题前可能会进行长时间思考,o1 在尝试解决问题时使用思维链。通过强化学习,o1 学会了打磨自己的思维链,并优化其使用的策略。它学会了识别和纠正自己的错误,学会将复杂的步骤拆解为更简单的步骤,学会在当前方法无效时尝试不同的方法。这个过程极大地提升了模型的推理能力。
对于OpenAI o1系统的前沿风险评估,OpenAI 提到,在将新模型部署到 ChatGPT 或 API 中之前,我们会彻底评估新模型是否存在潜在风险,并建立适当的保护措施。我们将发布 OpenAI o1系统卡和准备框架记分卡,以对 o1 进行严格的安全评估,包括我们为应对当前的安全挑战和前沿风险所做的工作。
在我们为过去的模型制定的安全评估和缓解措施的基础上,我们更加注重 o1 的高级推理能力。我们使用公开和内部评估来衡量诸如不允许的内容、人口公平性、幻觉倾向和危险能力等风险。基于这些评估,我们在模型和系统层面实施了保护措施,例如黑名单和安全分类器,以有效缓解这些风险。
我们的研究结果表明,o1 的高级推理能力提高了安全性,因为它可以根据具体情况推理我们的安全规则并更有效地应用它们,从而使模型更能抵御有害内容的生成。在我们的准备框架下,o1 的总体风险评级为“中等”,部署安全,因为它不会启用现有资源无法实现的任何功能,在网络安全和模型自主性方面的风险等级为“低”,在 CBRN 和说服方面的风险等级为“中等”。
OpenAI 的安全咨询小组、安全与保障委员会和 OpenAI 董事会审查了适用于 o1 的安全与保障协议以及深入的准备情况评估,最终批准发布 o1。
o1 模型系列经过大规模强化学习训练,使用思路链进行推理。这些先进的推理能力为提高我们模型的安全性和稳健性提供了新的途径。特别是,我们的模型可以在响应潜在不安全提示时根据上下文推理我们的安全政策。这导致在某些风险基准上表现出最佳性能,例如产生非法建议、选择刻板反应和屈服于已知越狱。训练模型在回答之前融入思路链有可能释放出巨大的好处,同时也会增加因智力提高而产生的潜在风险。我们的结果强调了建立强大的对齐方法、广泛压力测试其有效性以及维护细致的风险管理协议的必要性。本报告概述了针对 OpenAI o1-preview 和 OpenAI o1-mini 模型开展的安全工作,包括安全评估、外部红队和准备框架评估。
阅读报告中文版全文,请访问欧米伽研究所的“未来知识库”
未来知识库是“欧米伽未来研究所”建立的在线知识库平台,收藏的资料范围包括人工智能、脑科学、互联网、超级智能,数智大脑、能源、军事、经济、人类风险等等领域的前沿进展与未来趋势。目前拥有超过8000篇重要资料。每周更新不少于100篇世界范围最新研究资料。欢迎扫描二维码或点击本文左下角“阅读原文”进入。



















 412
412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









