



Dify与本地私有化大模型(如Ollama、DeepSeek、Llama等)集成的全流程指南,涵盖部署、配置及企业级优化方案,结合最新实践整理:
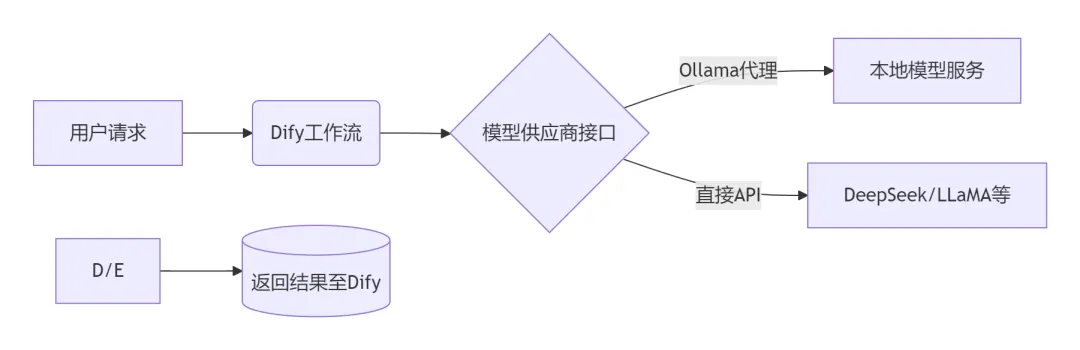
一、集成原理与架构
核心机制:
Dify通过模型供应商接口对接本地模型服务,支持两种模式:
Ollama代理(推荐):标准化管理本地模型,提供统一API端点。
直接API调用:兼容OpenAI格式的模型服务(如vLLM、LocalAI)。
数据流架构:
二、Ollama代理模式(推荐)
步骤1:部署Ollama服务
# 拉取Ollama镜像
docker pull ollama/ollama:latest
# 启动服务(暴露0.0.0.0并指定端口)
docker run -d -p 11434:11434 -e OLLAMA_HOST=0.0.0.0 ollama/ollama
# 下载模型(以DeepSeek-R1为例)
ollama run deepseek-r1:7b
关键配置:
Linux需开放防火墙:sudo ufw allow 11434
跨主机访问时,OLLAMA_HOST需设为服务器IP。
步骤2:Dify中配置Ollama供应商
登录Dify控制台 → 设置 → 模型供应商 → Ollama
填写参数:
- 模型名称:deepseek-r1:7b(与Ollama中一致)
- 基础URL:http://<服务器IP>:11434(Docker部署填host.docker.internal:11434)
- 模型类型:对话(LLM Chat)
- 上下文长度:4096(按模型实际能力设置)。
三、直接API模式(适用于自定义模型)
场景:集成DeepSeek-32B
部署模型API服务(以vLLM为例):
# 启动DeepSeek API服务
docker run -d -p 8000:8000 \
-v /path/to/model:/model \
--gpus all \
deepseek-runtime:latest \
--model deepseek-32b --api-key YOUR_KEY
Dify配置:
- API端点:http://host.docker.internal:8000/v1(跨容器通信)
- 模型名称映射:deepseek-32b
- 认证方式:API Key(若启用)。
- 选择 模型供应商 → 自定义模型
- 填写参数
四、企业级优化配置
1. 性能调优
- GPU资源隔离:在docker-compose.yml中限制容器资源:
services:
api:
deploy:
resources:
limits:
cpus:'4'
memory:16G
devices:
-driver:nvidia
count:1# 独占1块GPU
- 并发优化:修改.env文件:
API_CONCURRENCY=20 # 提升并发处理能力
WORKER_TIMEOUT=300 # 长任务超时延长
2. 安全加固
- HTTPS加密:通过Nginx配置SSL反向代理:
server {
listen 443 ssl;
ssl_certificate /etc/nginx/certs/dify.crt;
ssl_certificate_key /etc/nginx/certs/dify.key;
location / {
proxy_pass http://dify-api:3000;
}
}
- 权限控制:对接企业LDAP/AD认证,限制模型访问权限。
3. 知识库增强
-
替换Embedding模型:
1、部署bge-m3文本嵌入服务:
ollama run bge-m3
2、在Dify知识库设置 → Embedding模型 → 选择bge-m3。
- 分段优化:设置最大长度=512 tokens,重叠长度=64 tokens,提升检索准确性。
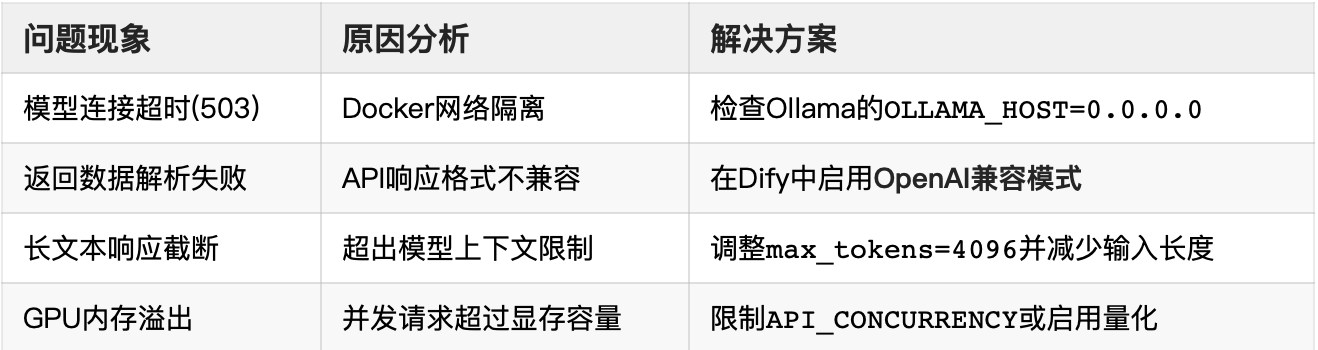
五、故障排查手册
六、最佳实践案例
某金融机构智能客服系统:
-
架构:Dify + DeepSeek-32B + BGE-M3
-
关键配置:
- 工作流中插入人工审核节点拦截高风险回答
- 知识库分段策略:语义分割+关键词增强
- 请求缓存:Redis复用70%相似查询结果
-
成效:响应速度<2秒,问答准确率提升至92%。
💡 技术选型建议:
- 轻量级场景:选Ollama代理(部署简单)
- 高性能需求:用vLLM直接API(支持批处理与量化)
- 企业合规:务必启用HTTPS+LDAP认证
学习交流群

推荐阅读:

















 1991
1991

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









