




一、现象级爆红:两天登顶,开源社区的“新神”诞生
7月12日,月之暗面(Moonshot AI)开源万亿参数大模型 Kimi K2,短短48小时内:
- 使用量碾压 Grok 4:在OpenRouter平台token消耗量超越马斯克的xAI,登顶全球API调用榜;
- 开发者狂热测试:GitHub相关项目激增200%,Hugging Face下载量破10万次;
- 社区评价:“唯一在编码和Agent任务上超越Claude 4的开源模型”“中文创意写作吊打R1”。
现象背后:中国大模型首次在代码生成、工具调用、智能体任务三大核心能力上同时达到全球顶尖水平。
▲ Kimi K2发布两天即超越Grok 4的token消耗量
二、技术解析:DeepSeek V3 的“进化体”,训练成本直降80%
1. 架构设计:稀疏专家机制(MoE)的极致优化
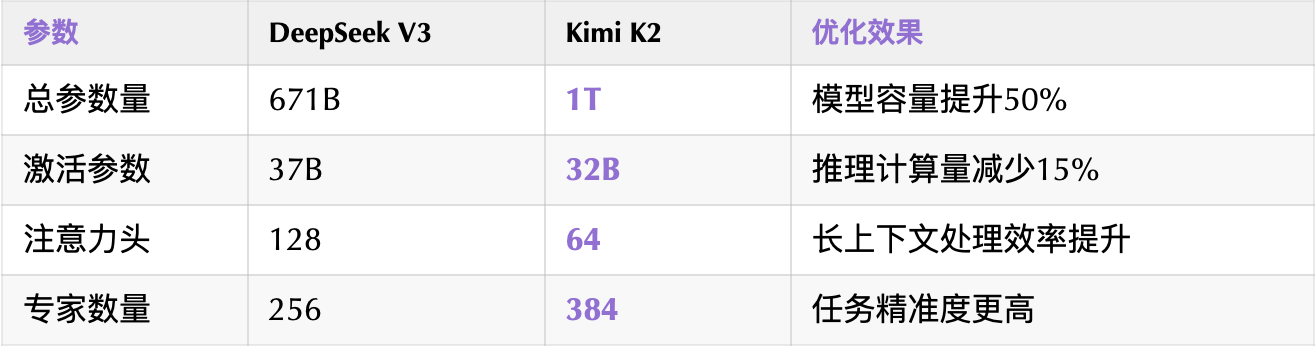
创新点:
- MuonClip优化器:通过 qk-clip 技术抑制注意力权重爆炸,实现15.5万亿token预训练“零崩溃”;
- 动态路由机制:按任务激活专家模块(如数学问题→数学专家),避免资源浪费。
2. 训练效率革命:Token利用率提升300%
- 数据瓶颈突破:在高质量语料稀缺背景下,MuonClip优化器将Token利用效率提升3倍,同等数据量产生更多智能;
- 自研数据合成:自动生成数千种工具调用场景,让模型在“自我博弈”中学习复杂任务。
三、价格核弹:同等能力,成本仅为Claude 4的20%
API定价对比(每百万tokens):
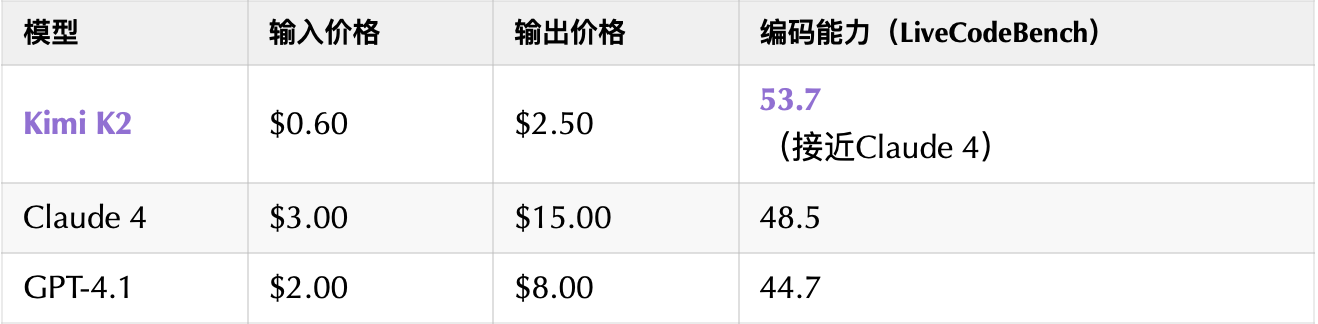
开发者实测:
用Kimi K2驱动Claude Code,功能平替率达85%,全天编码仅需几元成本;
数据分析任务:处理13万行薪资数据→生成交互式网页报告,总成本不到$0.1。
四、实战封神:开发者亲测“能干活”的AI
场景1:全栈代码生成与调试
任务:将Flask项目迁移至Rust(含前后端+数据库)
过程:
# Kimi K2自动完成步骤
1. 解析Flask路由逻辑 → 抽象接口规范
2. 生成actix-web框架代码 + Cargo.toml依赖
3. 自动修复编译错误(如askama模板宏引用问题)
结果:零人工干预完成跨语言迁移,代码可直接部署。
场景2:多工具协同数据分析
指令:
“分析远程办公对薪资的影响,输出统计图表和网页报告。”
Kimi K2自主流程:
graph LR
A[读取CSV] --> B[清洗空值]
B --> C[计算薪资均值/城市分布]
C --> D[生成箱线图/散点图]
D --> E[用HTML+JS构建交互网页]
输出效果:带回归模型解读的专业报告,支持图表交互。
▲ 完全由Kimi K2生成的薪资数据分析网页
五、行业冲击:中国大模型的“技术民主化”宣言
打破算力垄断:
- 万亿参数模型在非英伟达硬件流畅运行,动态路由策略降低对高端芯片依赖;
- 开源协议友好:允许商用,企业可私有化部署规避数据安全风险。
颠覆AI交互范式:
- 用户输入需求 → AI直接生成可交互应用(如网页/PPT),而非文本对话;
- 从 Chat-First(对话优先)→Artifact-First(交付物优先):
- 代表案例:前端组件库自主开发,无需引用外部库。
开源社区的胜利:
- 复现标准化:任何开发者可通过Hugging Face + 标准Prompt复现官方效果,杜绝“工程粉饰”;
- 生态整合:已接入LangChain、CrewAI等框架,企业可快速构建自动化系统。
结语:不是“中国版Claude”,而是下一代AI的开拓者
Kimi K2的爆发印证了:
“模型能力才是硬通货” —— 放弃短期流量,专注技术突破的Moonshot,用开源实力重夺话语权。
其意义远超单一模型竞争:
- 技术层面:为万亿参数训练提供可复现路径(MuonClip + 高稀疏MoE); 产业层面:证明开源可控+成本优势可打破国际巨头垄断;
- 生态层面:推动AI开发从“调API”走向“造智能体”的新时代。
行动指南:
- 即刻体验:https://huggingface.co/moonshot-ai/kimi-k2-base
- API接入:通过vLLM部署,兼容OpenAI格式
- 深度研究:https://moonshotai.github.io/Kimi-K2/
当开发者用20%成本获得85%的Claude 4能力时,“全球最强AI”的称号正悄然易主。


















 2334
2334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









