




就在最近,字节跳动再次在 AI 编程领域出手——火山引擎正式发布 豆包编程模型 Doubao-Seed-Code,并针对企业用户上线了 TRAE CN 企业版公测。
这次,豆包不仅仅是一个“智能助手”,而是真正让 AI 参与到项目开发的每一步:从写代码、调试到多模块协作,AI 都能直接上手。
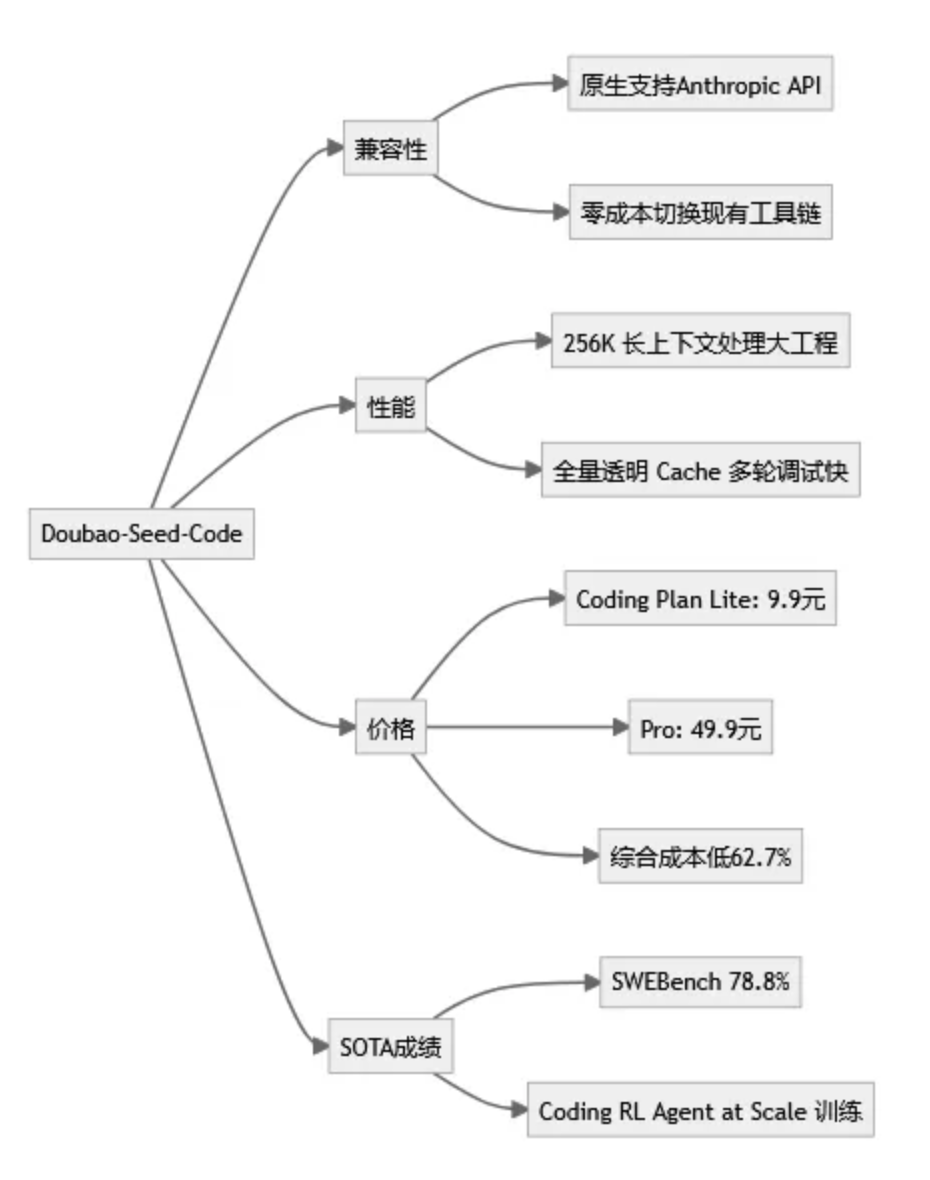
1. 兼容性满分:零成本上手
Doubao-Seed-Code 原生支持 Anthropic API,对于已经使用 Claude Code 的开发者来说,几乎 不需要改动现有工具链、接口或 IDE。 换句话说,以前换模型可能需要重新配置整个开发环境,现在直接切换就行,团队零成本上手。
对于企业来说,这意味着迁移成本低、开发效率不受影响——真正实现了“无痛平替”。
2. 性能提升明显:处理大型项目无压力
- 256K 长上下文:AI 可以理解更长的代码逻辑,处理多模块、多依赖项目不再吃力。
- 全量透明 Cache:在多轮调试中重复计算大幅减少,响应速度更快。
简单说,豆包不仅聪明,还跑得稳——复杂项目、跨模块调试都能让 AI 顺畅参与,让团队开发效率提升明显。
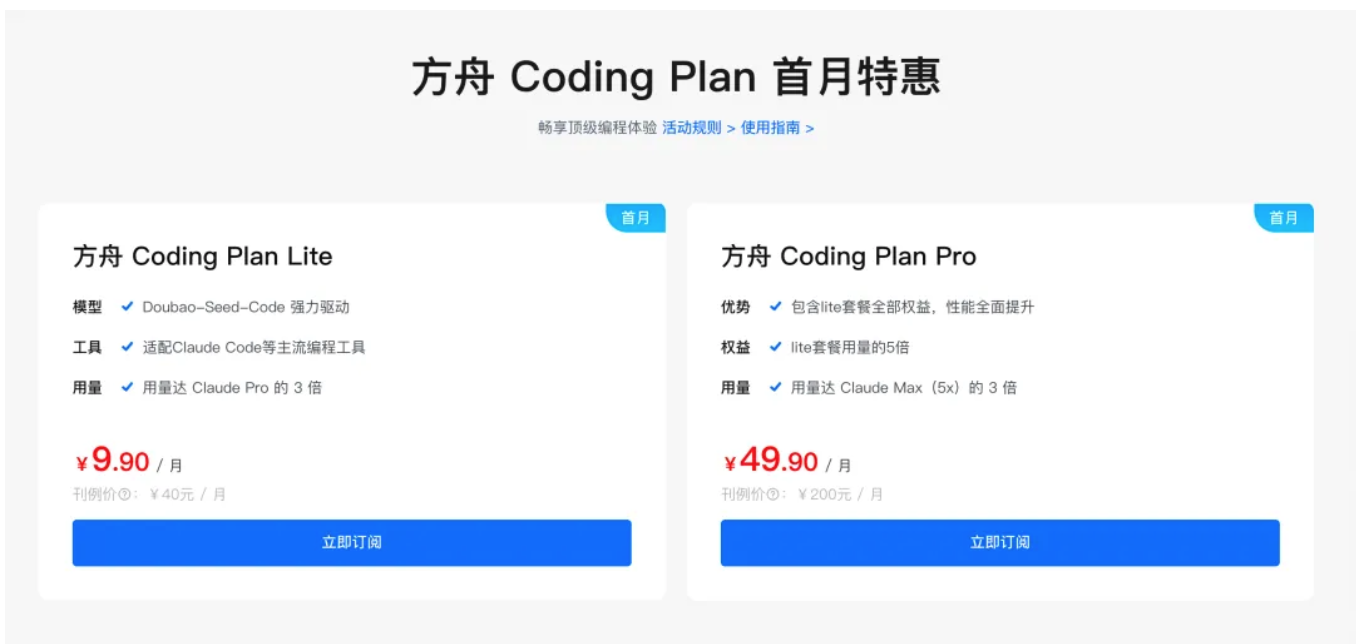
3. 价格下探:真正普惠开发者
豆包的定价也非常“贴心”:
- 输入输出单价全线下降,综合成本比市场平均低 **62.7%**。
- Coding Plan:Lite 版本首月最低 9.9 元,Pro 版本仅 49.9 元。
字节这次是真正把 “普惠开发者” 做到了极致,无论是个人开发者还是小型团队,都能轻松尝试 AI 编程。
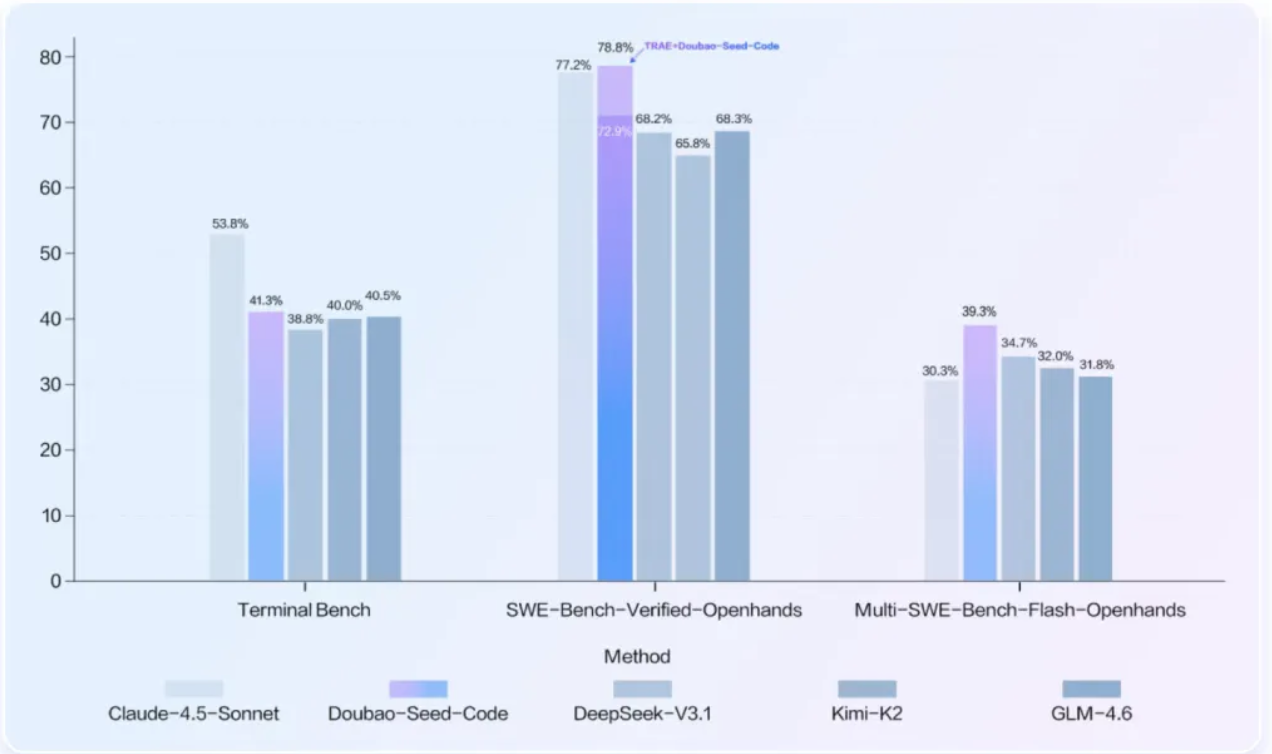
4. SOTA 成绩:AI 写真实工程不是口号
在 SWEBench Verified 榜单上,Doubao-Seed-Code 与 TRAE CN 企业版结合后的成绩 **78.8%**,直接登顶 SOTA。
背后支撑是火山引擎自研的 Coding RL Agent at Scale 系统:
- 万级并发沙盒
- 千卡 GPU 并行训练
- 用真实工程数据训练 AI
这意味着,豆包不是靠小样本或者模拟数据吹牛,而是真正从 工程实践中学会写代码、解决问题。
5. 字节的节奏:团队、激励、布局
字节对 AI 的加码非常明显:
- 团队持续扩招,特别是 SEED 和豆包团队
- 组织架构调整,资源倾斜 AI 项目
- 额外期权激励,确保团队长期动力
经典的字节节奏再次上演:投入、布局、激励——让 AI 编程的“落地”更有保障。
6. 豆包特性图示
7. AI 写项目时代已来
- 零成本兼容现有工具链
- 长上下文 + Cache,处理复杂项目无压力
- 价格低,普惠开发者
- SOTA 成绩,工程训练落地
豆包编程模型,正在为 AI 参与真实项目开发 定义新的标杆。

















 1721
1721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









