



 本文详细介绍了批量归一化在深度学习模型中的应用,包括在全连接层和卷积层的位置,以及预测时的处理。此外,还讨论了深度学习中的优化问题,如局部最小值、鞍点和梯度消失,并提及了残差网络和稠密连接网络(DenseNet)的设计策略。
本文详细介绍了批量归一化在深度学习模型中的应用,包括在全连接层和卷积层的位置,以及预测时的处理。此外,还讨论了深度学习中的优化问题,如局部最小值、鞍点和梯度消失,并提及了残差网络和稠密连接网络(DenseNet)的设计策略。
1、 批量归一化(BatchNormalization)
对输入的标准化(浅层模型)
处理后的任意一个特征在数据集中所有样本上的均值为0、标准差为1。
标准化处理输入数据使各个特征的分布相近
批量归一化(深度模型)
利用小批量上的均值和标准差,不断调整神经网络中间输出,从而使整个神经网络在各层的中间输出的数值更稳定。
1.对全连接层做批量归一化位置:
全连接层中的仿射变换和激活函数之间。
全连接:

批量归一化:

这⾥ϵ > 0是个很小的常数,保证分母大于0

2.对卷积层做批量归⼀化
位置:卷积计算之后、应⽤激活函数之前。
如果卷积计算输出多个通道,我们需要对这些通道的输出分别做批量归一化,且每个通道都拥有独立的拉伸和偏移参数。 计算:对单通道,batchsize=m,卷积计算输出=pxq 对该通道中m×p×q个元素同时做批量归一化,使用相同的均值和方差。
3.预测时的批量归⼀化
训练:以batch为单位,对每个batch计算均值和方差。
预测:用移动平均估算整个训练数据集的样本均值和方差。
残差网络(ResNet)
深度学习的问题:深度CNN网络达到一定深度后再一味地增加层数并不能带来进一步地分类性能提高,反而会招致网络收敛变得更慢,准确率也变得更差
残差块(Residual Block)
恒等映射:
左边:f(x)=x
右边:f(x)-x=0 (易于捕捉恒等映射的细微波动)
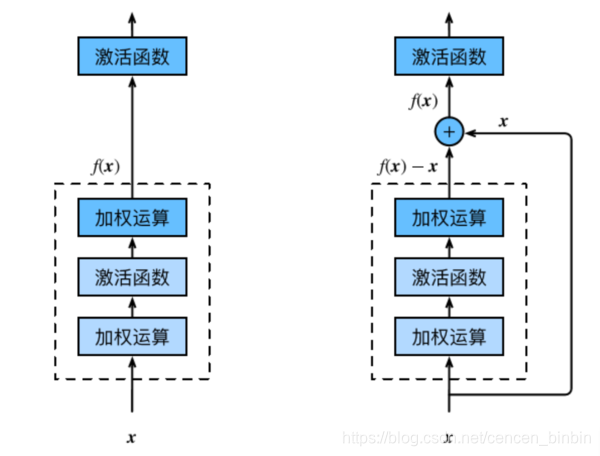
在残差块中,输⼊可通过跨层的数据线路更快 地向前传播。
稠密连接网络(DenseNet)
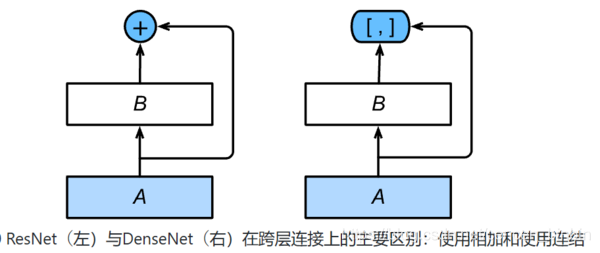
主要构建模块:¶
稠密块(dense block): 定义了输入和输出是如何连结的。
过渡层(transition layer):用来控制通道数,使之不过大。
过渡层1×11×1 卷积层:来减小通道数
步幅为2的平均池化层:减半高和宽
在稠密块中,假设由3个输出通道数为8的卷积层组成,稠密块的输入通道数是3,那么稠密块的输出通道数是()
输出通道数=输入通道数+卷积层个数*卷积输出通道数
2、优化与深度学习
优化与估计
尽管优化方法可以最小化深度学习中的损失函数值,但本质上优化方法达到的目标与深度学习的目标并不相同。
优化方法目标:训练集损失函数值
深度学习目标:测试集损失函数值(泛化性)
优化在深度学习中的挑战
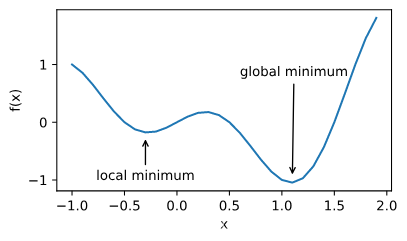
1、局部最小值
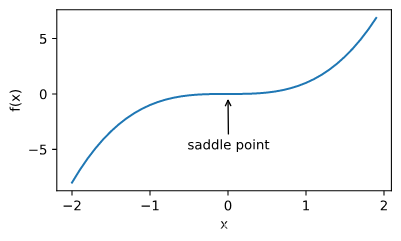
2、鞍点
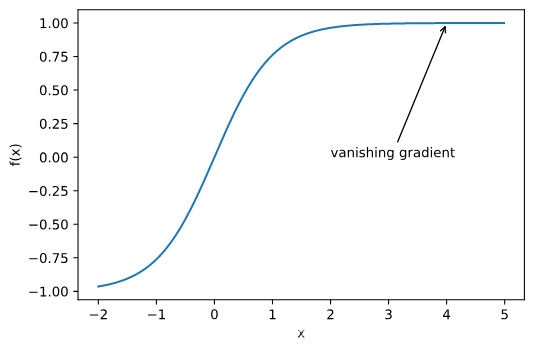
3、梯度消失
局部最小值
f(x) = x*cosπx
鞍点
梯度消失
凸性 (Convexity)
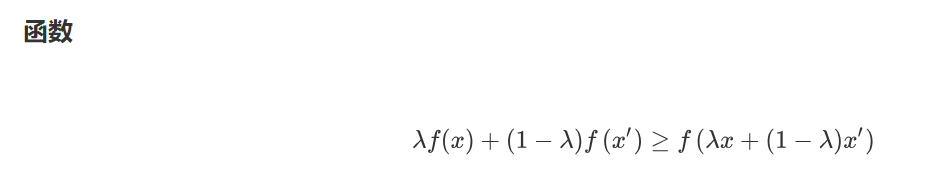
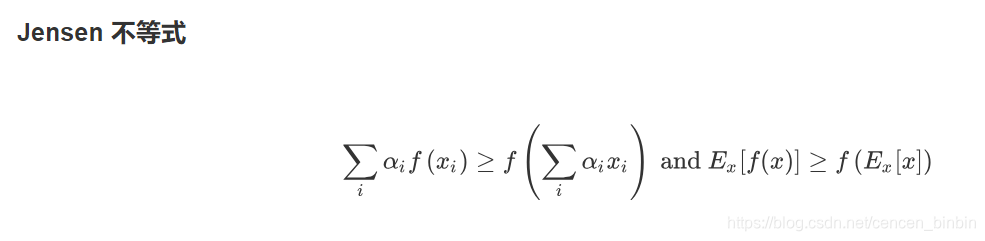
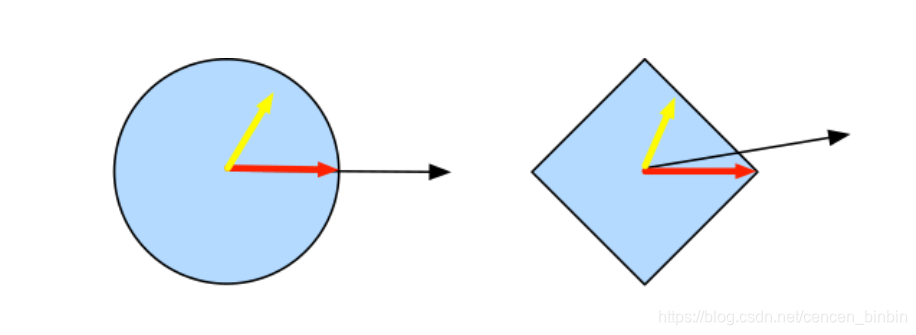
性质
无局部极小值
与凸集的关系
二阶条件

凸函数与二阶导数



















 922
922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









