






 本文探讨了数据透视表在数据分析中的高级应用,通过实际案例展示了如何利用数据透视表进行多维度数据分析,包括处理泰坦尼克号乘客数据和美国人的生日数据。文章详细介绍了数据透视表的语法和参数,以及如何通过数据透视表发现数据集中的有趣特征。
本文探讨了数据透视表在数据分析中的高级应用,通过实际案例展示了如何利用数据透视表进行多维度数据分析,包括处理泰坦尼克号乘客数据和美国人的生日数据。文章详细介绍了数据透视表的语法和参数,以及如何通过数据透视表发现数据集中的有趣特征。
3.10 数据透视表
我们已经介绍过 GroupBy 抽象类是如何探索数据集内部的关联性的了。数据透视表(pivot table)是一种类似的操作方法,常见于 Excel 与类似的表格应用中。数据透视表将每一列数据作为输入,输出将数据不断细分成多个维度累计信息的二维数据表。人们有时容易弄混数据透视表与 GroupBy,但我觉得数据透视表更像是一种多维的 GroupBy 累计操作。也就是说,虽然你也可以分割 - 应用 - 组合,但是分割与组合不是发生在一维索引上,而是在二维网格上(行列同时分组)。
3.10.1 演示数据透视表
这一节的示例将采用泰坦尼克号的乘客信息数据库来演示,可以在 Seaborn 程序库(详情请参见 4.16 节)获取:
import numpy as np
import pandas as pd
import seaborn as sns
titanic = sns.load_dataset('titanic')
titanic.head()
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False |
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 4 | 0 | 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True |
这份数据包含了惨遭厄运的每位乘客的大量信息,包括性别(gender)、年龄(age)、船舱等级(class)和船票价格(fare paid)等。
3.10.2 手工制作数据透视表
在研究这些数据之前,先将它们按照性别、最终生还状态或其他组合属性进行分组。如果你看过前面的章节,你可能会用 GroupBy 来实现,例如这样统计不同性别乘客的生还率:
titanic.groupby('sex')[['survived']].mean()
| survived | |
|---|---|
| sex | |
| female | 0.742038 |
| male | 0.188908 |
这组数据会立刻给我们一个直观感受:总体来说,有四分之三的女性被救,但只有五分之一的男性被救!
这组数据很有用,但是我们可能还想进一步探索,同时观察不同性别与船舱等级的生还情况。根据 GroupBy 的操作流程,我们也许能够实现想要的结果:将船舱等级('class')与性别('sex')分组,然后选择生还状态('survived')列,应用均值('mean')累计函数,再将各组结果组合,最后通过行索引转列索引操作将最里层的行索引转换成列索引,形成二维数组。代码如下所示:
titanic.groupby(['sex', 'class'])['survived'].aggregate('mean').unstack()
| class | First | Second | Third |
|---|---|---|---|
| sex | |||
| female | 0.968085 | 0.921053 | 0.500000 |
| male | 0.368852 | 0.157407 | 0.135447 |
虽然这样就可以更清晰地观察乘客性别、船舱等级对其是否生还的影响,但是代码看上去有点复杂。尽管这个管道命令的每一步都是前面介绍过的,但是要理解这个长长的语句可不是那么容易的事。由于二维的 GroupBy 应用场景非常普遍,因此 Pandas 提供了一个快捷方式 pivot_table 来快速解决多维的累计分析任务。
3.10.3 数据透视表语法
用 DataFrame 的 pivot_table 实现的效果等同于上一节的管道命令的代码:
titanic.pivot_table('survived', index='sex', columns='class')
| class | First | Second | Third |
|---|---|---|---|
| sex | |||
| female | 0.968085 | 0.921053 | 0.500000 |
| male | 0.368852 | 0.157407 | 0.135447 |
与 GroupBy 方法相比,这行代码可读性更强,而且取得的结果也一样。可能与你对 20 世纪初的那场灾难的猜想一致,生还率最高的是船舱等级高的女性。一等舱的女性乘客基本全部生还(露丝自然得救),而三等舱男性乘客的生还率仅为十分之一(杰克为爱牺牲)。
多级数据透视表
与 GroupBy 类似,数据透视表中的分组也可以通过各种参数指定多个等级。例如,我们可能想把年龄('age')也加进去作为第三个维度,这就可以通过 pd.cut 函数将年龄进行分段:
age = pd.cut(titanic['age'], [0, 18, 80])
titanic.pivot_table('survived', ['sex', age], 'class')
| class | First | Second | Third | |
|---|---|---|---|---|
| sex | age | |||
| female | (0, 18] | 0.909091 | 1.000000 | 0.511628 |
| (18, 80] | 0.972973 | 0.900000 | 0.423729 | |
| male | (0, 18] | 0.800000 | 0.600000 | 0.215686 |
| (18, 80] | 0.375000 | 0.071429 | 0.133663 |
对某一列也可以使用同样的策略——让我们用 pd.qcut 将船票价格按照计数项等分为两份,加入数据透视表看看:
fare = pd.qcut(titanic['fare'], 2)
titanic.pivot_table('survived', ['sex', age], [fare, 'class'])
| fare | (-0.001, 14.454] | (14.454, 512.329] | |||||
|---|---|---|---|---|---|---|---|
| class | First | Second | Third | First | Second | Third | |
| sex | age | ||||||
| female | (0, 18] | NaN | 1.000000 | 0.714286 | 0.909091 | 1.000000 | 0.318182 |
| (18, 80] | NaN | 0.880000 | 0.444444 | 0.972973 | 0.914286 | 0.391304 | |
| male | (0, 18] | NaN | 0.000000 | 0.260870 | 0.800000 | 0.818182 | 0.178571 |
| (18, 80] | 0.0 | 0.098039 | 0.125000 | 0.391304 | 0.030303 | 0.192308 | |
结果是一个带层级索引(详情请参见 3.6 节)的四维累计数据表,通过网格显示不同数值之间的相关性。
其他数据透视表选项
DataFrame 的 pivot_table 方法的完整签名如下所示:
# Pandas 0.18版的函数签名
DataFrame.pivot_table(data, values=None, index=None, columns=None,
aggfunc='mean', fill_value=None, margins=False,
dropna=True, margins_name='All')
我们已经介绍过前面三个参数了,现在来看看其他参数。
fill_value 和 dropna 这两个参数用于处理缺失值,用法很简单,我们将在后面的示例中演示其用法。
aggfunc 参数用于设置累计函数类型,默认值是均值(mean)。与 GroupBy 的用法一样,累计函数可以用一些常见的字符串('sum'、'mean'、'count'、'min'、'max' 等)表示,也可以用标准的累计函数(np.sum()、min()、sum() 等)表示。另外,还可以通过字典为不同的列指定不同的累计函数:
titanic.pivot_table(index='sex', columns='class',
aggfunc={'survived':sum, 'fare':'mean'})
| fare | survived | |||||
|---|---|---|---|---|---|---|
| class | First | Second | Third | First | Second | Third |
| sex | ||||||
| female | 106.125798 | 21.970121 | 16.118810 | 91 | 70 | 72 |
| male | 67.226127 | 19.741782 | 12.661633 | 45 | 17 | 47 |
需要注意的是,这里忽略了一个参数 values。当我们为 aggfunc 指定映射关系的时候,待透视的数值就已经确定了。 当需要计算每一组的总数时,可以通过 margins 参数来设置:
titanic.pivot_table('survived', index='sex', columns='class', margins=True)
| class | First | Second | Third | All |
|---|---|---|---|---|
| sex | ||||
| female | 0.968085 | 0.921053 | 0.500000 | 0.742038 |
| male | 0.368852 | 0.157407 | 0.135447 | 0.188908 |
| All | 0.629630 | 0.472826 | 0.242363 | 0.383838 |
这样就可以自动获取不同性别下船舱等级与生还率的相关信息、不同船舱等级下性别与生还率的相关信息,以及全部乘客的生还率为 38%。margin 的标签可以通过 margins_name 参数进行自定义,默认值是 "All"。
3.10.4 案例:美国人的生日
再来看一个有趣的例子——由美国疾病防治中心(Centers for Disease Control,CDC)提供的公开生日数据,这些数据可以从 https://raw.githubusercontent.com/jakevdp/data-CDCbirths/master/births.csv 下载。
births = pd.read_csv('births.csv')
只简单浏览一下,就会发现这些数据比较简单,只包含了不同出生日期(年月日)与性别的出生人数:
births.head()
| year | month | day | gender | births | |
|---|---|---|---|---|---|
| 0 | 1969 | 1 | 1.0 | F | 4046 |
| 1 | 1969 | 1 | 1.0 | M | 4440 |
| 2 | 1969 | 1 | 2.0 | F | 4454 |
| 3 | 1969 | 1 | 2.0 | M | 4548 |
| 4 | 1969 | 1 | 3.0 | F | 4548 |
可以用一个数据透视表来探索这份数据。先增加一列表示不同年代,看看各年代的男女出生比例:
births['decade'] = 10 * (births['year'] // 10)
births.pivot_table('births', index='decade', columns='gender', aggfunc='sum')
| gender | F | M |
|---|---|---|
| decade | ||
| 1960 | 1753634 | 1846572 |
| 1970 | 16263075 | 17121550 |
| 1980 | 18310351 | 19243452 |
| 1990 | 19479454 | 20420553 |
| 2000 | 18229309 | 19106428 |
我们马上就会发现,每个年代的男性出生率都比女性出生率高。如果希望更直观地体现这种趋势,可以用 Pandas 内置的画图功能将每一年的出生人数画出来(如图所示,详情请参见第 4 章中用 Matplotlib 画图的内容):
%matplotlib inline
import matplotlib.pyplot as plt
sns.set() # use Seaborn styles
births.pivot_table('births', index='year', columns='gender', aggfunc='sum').plot()
plt.ylabel('total births per year');
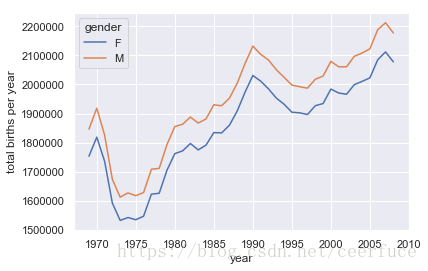
借助一个简单的数据透视表和 plot() 方法,我们马上就可以发现不同性别出生率的趋势。通过肉眼观察,得知过去 50 年间的男性出生率比女性出生率高 5%。
深入探索
虽然使用数据透视表并不是必须的,但是通过 Pandas 的这个工具可以展现一些有趣的特征。我们必须对数据做一点儿清理工作,消除由于输错了日期而造成的异常点(如 6 月 31 号)或者是缺失值(如 1999 年 6 月)。消除这些异常的简便方法就是直接删除异常值,可以通过更稳定的 sigma 消除法(sigma-clipping,按照正态分布标准差划定范围,SciPy 中默认是四个标准差)操作来实现:
quartiles = np.percentile(births['births'], [25, 50, 75]) mu = quartiles[1] sig = 0.74 * (quartiles[2] - quartiles[0])
最后一行是样本均值的稳定性估计(robust estimate),其中 0.74 是指标准正态分布的分位数间距。在 query() 方法(详情请参见 3.13 节)中用这个范围就可以将有效的生日数据筛选出来了:
births = births.query('(births > @mu - 5 * @sig) & (births < @mu + 5 * @sig)')
然后,将 day 列设置为整数。这列数据在筛选之前是字符串,因为数据集中有的列含有缺失值 'null':
births['day'] = births['day'].astype(int)
现在就可以将年月日组合起来创建一个日期索引了(详情请参见 3.12 节),这样就可以快速计算每一行是星期几:
# 从年月日创建一个日期索引
births.index = pd.to_datetime(10000 * births.year +
100 * births.month +
births.day, format='%Y%m%d')
births['dayofweek'] = births.index.dayofweek
用这个索引可以画出不同年代不同星期的日均出生数据(如图所示):
import matplotlib.pyplot as plt
import matplotlib as mpl
births.pivot_table('births', index='dayofweek',
columns='decade', aggfunc='mean').plot()
plt.gca().set_xticklabels(['Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat', 'Sun'])
plt.ylabel('mean births by day');
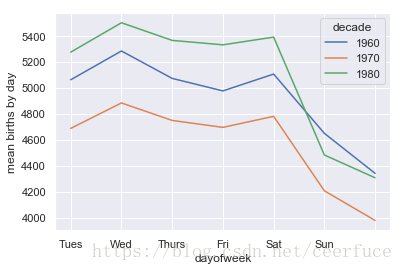
由图可知,周末的出生人数比工作日要低很多。另外,因为 CDC 只提供了 1989 年之前的数据,所以没有 20 世纪 90 年代和 21 世纪的数据。
另一个有趣的图表是画出各个年份平均每天的出生人数,可以按照月和日两个维度分别对数据进行分组:
births_by_date = births.pivot_table('births',
[births.index.month, births.index.day])
births_by_date.head()
| births | ||
|---|---|---|
| 1 | 1 | 4009.225 |
| 2 | 4247.400 | |
| 3 | 4500.900 | |
| 4 | 4571.350 | |
| 5 | 4603.625 |
这是一个包含月和日的多级索引。为了让数据可以用图形表示,我们可以虚构一个年份,与月和日组合成新索引(注意日期为 2 月 29 日时,索引年份需要用闰年,例如 2012):
births_by_date.index = [pd.datetime(2012, month, day)
for (month, day) in births_by_date.index]
births_by_date.head()
| births | |
|---|---|
| 2012-01-01 | 4009.225 |
| 2012-01-02 | 4247.400 |
| 2012-01-03 | 4500.900 |
| 2012-01-04 | 4571.350 |
| 2012-01-05 | 4603.625 |
如果只关心月和日的话,这就是一个可以反映一年中平均每天出生人数的时间序列。可以用 plot 方法将数据画成图(如图 3-4 所示),从图中可以看到一些有趣的趋势:
# Plot the results fig, ax = plt.subplots(figsize=(12, 4)) births_by_date.plot(ax=ax);
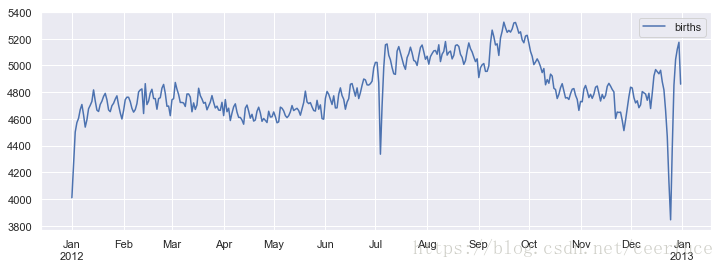
从图中可以明显看出,在美国节假日的时候,出生人数急速下降(例如美国独立日、劳动节、感恩节、圣诞节以及新年)。这种现象可能是由于医院放假导致的接生减少(自己在家生),而非某种自然生育的心理学效应。在 4.11.1 节会再次使用这张图,那时将用 Matplotlib 的画图工具为这张图增加标注。
通过这个简单的案例,你会发现许多前面介绍过的 Python 和 Pandas 工具都可以相互结合,并用于从大量数据集中获取信息。我们将在后面的章节中介绍如何用这些工具创建更复杂的应用。

















 2325
2325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









