




集成学习方法
集成学习(Emsemble Learning)是结合几个模型的元算法(meta-algorithm),在机器学习中的集成学习可以在一定程度上提高预测精度。常用方法有Bagging,boosting,stacking,这些集成学习方法与具体验证集划分联系紧密。这三种方法以及他们的效果分别是:
Bagging:减少 variance
boosting: 减少 bias
stacking:增强预测效果
1.bagging
bagging的最基本的思想是通过分别训练几个不同分类器,最后对测试的样本,每个分类器对其进行投票。在机器学习上这种策略叫model averaging。
model averaging 之所以有效,是因为并非所有的分类器都会产生相同的误差,只要有不同的分类器产生的误差不同就会对减小泛化误差非常有效。
对于bagging方法,允许采用相同的分类器,相同的训练算法,相同的目标函数。但是在数据集方面,新数据集与原始数据集的大小是相等的。每个数据集都是通过在原始数据集中随机选择一个样本进行替换而得到的。意味着,每个新数据集中会存在重复的样本。
在数据集建好之后,用相同的学习算法分别作用于每个数据集就得到了几个分类器。
2.boosting
相比下boosting比较复杂,但也很巧妙。
Bagging的思想比较简单,它是均匀概率分布,有放回的,每个bag或者说predictor是平行的。
但boosting的每一次抽样的样本分布都是不一样的,每个predictor是有顺序的。
boosting创建了一系列predictor,或者说是learner。前面的learner用简单的模型去适配数据,然后分析错误。然后会给予错误预测的数据更高权重,然后用后面的learner去修复。boosting通过把一些列的weak learners串起来,组成一个strong learners。
比喻一下,今天考试我这道题做错了,我把它记在错题本里,下次考试前,我就单独翻开错题本单独做一遍。如果下次考试做对了,就从错题本里删除,否则,在错题本里把这道题再做一次。这样每次下去,你的考试成绩就很可能提高。Boosting就是这样的原理。
3.Stacking
stacking的算法如上图。其实和和bagging不同的是,stacking通常是不同的模型。
第一步,有T个不同模型,根据数据,各自独立训练。每个模型输出结果为 [公式] ,其中t= 1,2,3…T
第二步,根据每个模型预测,创建新的『训练集』,训练集的数据(X)是预测结果,Y是实际结果。
第三步,再训练一个classifier,这里叫meta-classifier,来从各个预测中再生成最后预测。
和bagging有点相似,不一样的是:
bagging每个classifier其实是同一种模型
bagging每个bag用部分数据训练,stacking每个classifier都用了全部训练数据
深度学习中的集成学习
由于深度学习模型一般需要较长的训练周期,如果硬件设备不允许建议选取留出法,如果需要追求精度可以使用交叉验证的方法。
假设构建了10折交叉验证,训练得到10个CNN模型。那么在10个CNN模型可以使用如下方式进行集成:
对预测的结果的概率值进行平均,然后解码为具体字符;
对预测的字符进行投票,得到最终字符。
此外在深度学习中本身还有一些集成学习思路的做法:
1.Dropout
Dropout可以作为训练深度神经网络的一种技巧。在每个训练批次中,通过随机让一部分的节点停止工作。同时在预测的过程中让所有的节点都其作用。在bagging中,所有的分类器都是独立的,而在dropout中,所有的模型都是共享参数的。在bagging中,所有的分类器都是在特定的数据集下训练至收敛,而在dropout中没有明确的模型训练过程。网络都是在一步中训练一次(输入一个样本,随机训练一个子网络)
我们可以把dropout类比成将许多大的神经网络进行集成的一种bagging方法。
但是每一个神经网络的训练是非常耗时和占用很多内存的,训练很多的神经网络进行集合分类就显得太不实际了。但是,dropout可以训练所有子网络的集合,这些子网络通过去除整个网络中的一些神经元来获得。
如何移除一个神经元呢,我们通过仿射和非线性变换,试神经元的输出乘以0。
如下图,左边是我们常见的 full connect layer, 右边是使用了 dropout 之后的效果。其操作方法是,首先设定一个 dropout ratio \(\sigma\), \(\sigma\) 是超参数,范围设置为 \(\left (0,1\right)\), 表示在 Forward 阶段需要随机断开的连接的比例。每次 Forward 的时候都要随机的断开该比例的连接,只更新剩下的 weight. 最后,在 test/predict 的时候,使用全部的连接,不过,这些 weights 全部都需要乘上 \(1-\sigma\). 不过,在具体的实现中略有不同。
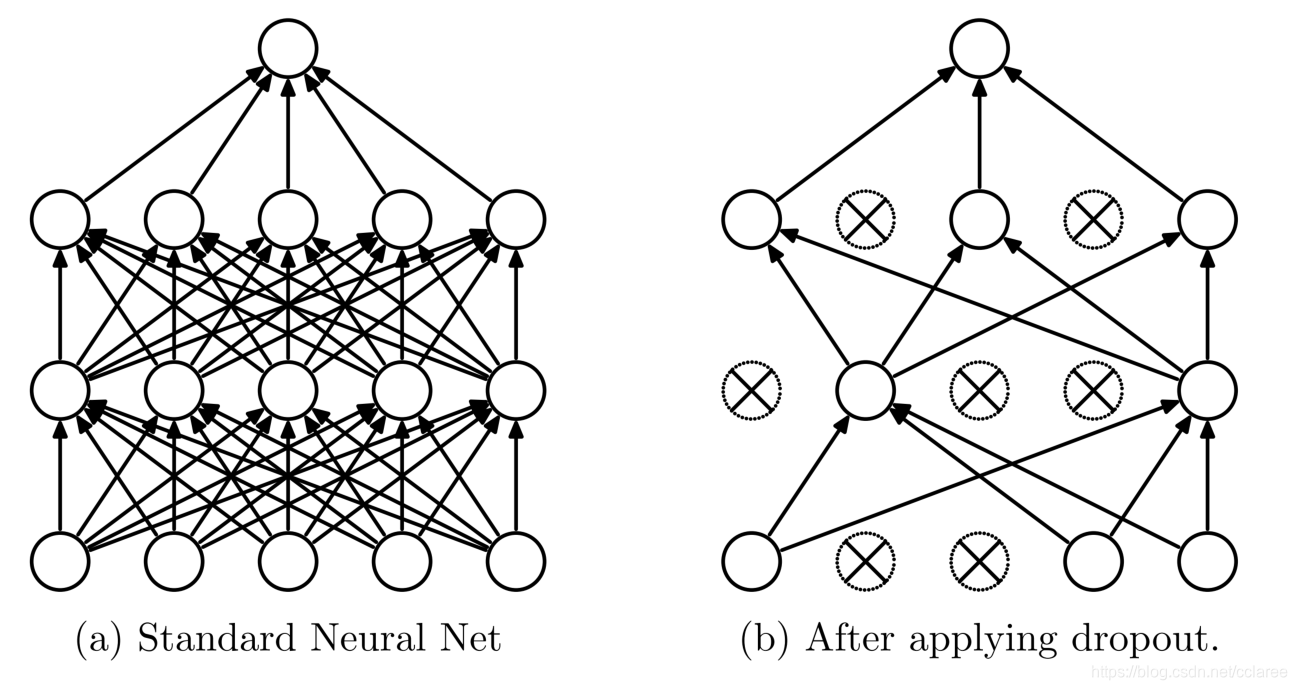
每次我们加载一个样本到minibatch,然后随机的采样一个不同的二进制掩膜作用在所有的输出,输入,隐藏节点上。每个节点的掩膜都是独立采样的。采样一个掩膜值为1的概率是固定的超参数。
在 CNN 中,Pooling 层具有一定的防止 overfitting 的作用,但是,CNN 的结构一般是多个 conv factory 之后需要使用 full connect 来做分类等任务,由于在 full connect layer 中参数密度比较高,非常容易 overfitting, 而 Dropout 可以用来解决这里的 overfitting 问题。Dropout 除了具有防止 overfitting 的作用之外,还有 model ensemble 的作用.我们考虑,假设 σ=0.5, 如果 Forward 的次数足够多 (例如无穷次), 每次都有一半的连接被咔嚓掉,在整个训练过程中,被咔嚓掉的连接的组合是 2n, 那么,留下的连接的组合种类也是 2n, 所以,这就相当于我们训练了 2n 个模型,然后 ensemble 起来.
dropout 最佳实践
1.使用 20-50 % 的 dropout,建议输入 20%。太低,影响可以忽略;太高,可能欠拟合。
2.在输入层和隐藏层上使用 dropout。这已被证明可以提高深度学习的性能。
3.使用伴有衰减的较大的学习速率,以及较大的动量。
4.限制权重!较大的学习速率会导致梯度爆炸。通过对网络权值施加约束(如大小为 5 的最大范数正则化)可以改善结果。
5.使用更大的网络。在较大的网络上使用 dropout 可能会获得更好的性能,从而使模型有更多的机会学习独立的表征。
无dropout 和加入的dropout对比实验代码
import torch
from torch.autograd import Variable
import matplotlib.pyplot as plt
torch.manual_seed(1)
lr = 0.1
N_SAMPLES = 20
N_HIDDEN = 300
# 训练数据
x = torch.unsqueeze(torch.linspace(-1, 1, N_SAMPLES), 1)
y = x + 0.3*torch.normal(torch.zeros(N_SAMPLES, 1), torch.ones(N_SAMPLES, 1))
x, y = Variable(x), Variable(y)
# 测试数据
test_x = torch.unsqueeze(torch.linspace(-1, 1, N_SAMPLES), 1)
test_y = test_x + 0.3*torch.normal(torch.zeros(N_SAMPLES, 1), torch.ones(N_SAMPLES, 1))
test_x, test_y = Variable(test_x, volatile=True), Variable(test_y, volatile=True)
# 展示一下数据分布
plt.scatter(x.data.numpy(), y.data.numpy(), c='magenta', s=50, alpha=0.5, label='train set')
plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='cyan', s=50, alpha=0.5, label='test set')
plt.legend(loc='upper left')
plt.ylim((-2.5, 2.5))
plt.show()
net_overfitting = torch.nn.Sequential(
torch.nn.Linear(1, N_HIDDEN),
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN, N_HIDDEN),
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN, 1),
)
net_dropped = torch.nn.Sequential(
torch.nn.Linear(1, N_HIDDEN),
torch.nn.Dropout(0.5), # drop out 0.5
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN, N_HIDDEN),
torch.nn.Dropout(0.5), # drop out 0.5
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN, 1),
)
print(net_overfitting) # 会过拟合的网络结构
"""
Sequential (
(0): Linear (1 -> 300)
(1): ReLU ()
(2): Linear (300 -> 300)
(3): ReLU ()
(4): Linear (300 -> 1)
)
"""
print(net_dropped) # 使用了Dropout的网络结构
"""
Sequential (
(0): Linear (1 -> 300)
(1): Dropout (p = 0.5)
(2): ReLU ()
(3): Linear (300 -> 300)
(4): Dropout (p = 0.5)
(5): ReLU ()
(6): Linear (300 -> 1)
)
"""
optimizer_ofit = torch.optim.Adam(net_overfitting.parameters(), lr=lr)
optimizer_drop = torch.optim.Adam(net_dropped.parameters(), lr=lr)
loss_func = torch.nn.MSELoss()
plt.ion() # hold住图
for t in range(500):
pred_ofit = net_overfitting(x)
pred_drop = net_dropped(x)
loss_ofit = loss_func(pred_ofit, y)
loss_drop = loss_func(pred_drop, y)
optimizer_ofit.zero_grad()
optimizer_drop.zero_grad()
loss_ofit.backward()
loss_drop.backward()
optimizer_ofit.step()
optimizer_drop.step()
if t % 10 == 0:
# 切换到测试形态
net_overfitting.eval()
net_dropped.eval()
# 画一下
plt.cla()
test_pred_ofit = net_overfitting(test_x)
test_pred_drop = net_dropped(test_x)
plt.scatter(x.data.numpy(), y.data.numpy(), c='magenta', s=50, alpha=0.3, label='train set')
plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='cyan', s=50, alpha=0.3, label='test set')
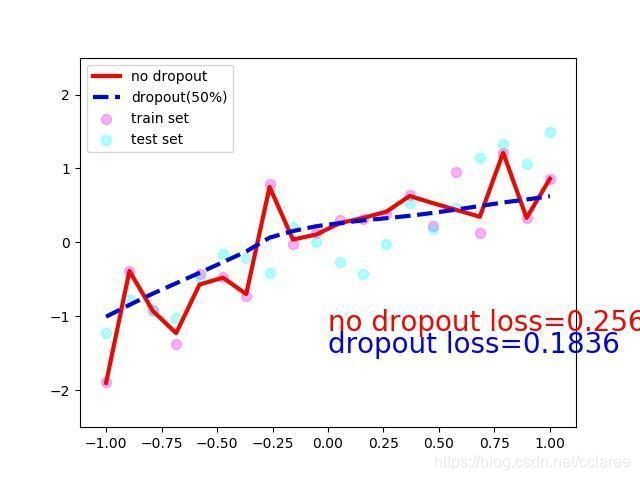
plt.plot(test_x.data.numpy(), test_pred_ofit.data.numpy(), 'r-', lw=3, label='no dropout')
plt.plot(test_x.data.numpy(), test_pred_drop.data.numpy(), 'b--', lw=3, label='dropout(50%)')
plt.text(0, -1.2, 'no dropout loss=%.4f' % loss_func(test_pred_ofit, test_y).data[0], fontdict={'size': 20, 'color': 'red'})
plt.text(0, -1.5, 'dropout loss=%.4f' % loss_func(test_pred_drop, test_y).data[0], fontdict={'size': 20, 'color': 'blue'})
plt.legend(loc='upper left'); plt.ylim((-2.5, 2.5));plt.pause(0.1)
# 切换回训练形态
net_overfitting.train()
net_dropped.train()
plt.ioff()
plt.show()
本实验中加入Dropout后的网络结构如下:
# 定义模型
class SVHN_Model1(nn.Module):
def __init__(self):
super(SVHN_Model1, self).__init__()
# CNN提取特征模块
self.cnn = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=(3, 3), stride=(2, 2)),
nn.ReLU(),
nn.Dropout(0.25),
nn.MaxPool2d(2),
nn.Conv2d(16, 32, kernel_size=(3, 3), stride=(2, 2)),
nn.ReLU(),
nn.Dropout(0.25),
nn.MaxPool2d(2),
)
#
self.fc1 = nn.Linear(32*3*7, 11)
self.fc2 = nn.Linear(32*3*7, 11)
self.fc3 = nn.Linear(32*3*7, 11)
self.fc4 = nn.Linear(32*3*7, 11)
self.fc5 = nn.Linear(32*3*7, 11)
self.fc6 = nn.Linear(32*3*7, 11)
def forward(self, img):
feat = self.cnn(img)
feat = feat.view(feat.shape[0], -1)
c1 = self.fc1(feat)
c2 = self.fc2(feat)
c3 = self.fc3(feat)
c4 = self.fc4(feat)
c5 = self.fc5(feat)
c6 = self.fc6(feat)
return c1, c2, c3, c4, c5, c6
2.TTA
测试集数据扩增(Test Time Augmentation,简称TTA)也是常用的集成学习技巧,数据扩增不仅可以在训练时候用,而且可以同样在预测时候进行数据扩增,对同一个样本预测三次,然后对三次结果进行平均。
def predict(test_loader, model, tta=10):
model.eval()
test_pred_tta = None
# TTA 次数
for _ in range(tta):
test_pred = []
with torch.no_grad():
for i, (input, target) in enumerate(test_loader):
c0, c1, c2, c3, c4, c5 = model(data[0])
output = np.concatenate([c0.data.numpy(), c1.data.numpy(),
c2.data.numpy(), c3.data.numpy(),
c4.data.numpy(), c5.data.numpy()], axis=1)
test_pred.append(output)
test_pred = np.vstack(test_pred)
if test_pred_tta is None:
test_pred_tta = test_pred
else:
test_pred_tta += test_pred
return test_pred_tta
3. Snapshot
假设我们训练了10个CNN则可以将多个模型的预测结果进行平均。但是假如只训练了一个CNN模型,如何做模型集成呢?
在论文Snapshot Ensembles中,作者提出使用cyclical learning rate进行训练模型,并保存精度比较好的一些checkopint,最后将多个checkpoint进行模型集成。
由于在cyclical learning rate中学习率的变化有周期性变大和减少的行为,因此CNN模型很有可能在跳出局部最优进入另一个局部最优。在Snapshot论文中作者通过使用表明,此种方法可以在一定程度上提高模型精度,但需要更长的训练时间。
集成学习只能在一定程度上提高精度,并需要耗费较大的训练时间,因此建议先使用提高单个模型的精度,再考虑集成学习过程;
具体的集成学习方法需要与验证集划分方法结合,Dropout和TTA在所有场景有可以起作用。
参考文献:
https://zhuanlan.zhihu.com/p/41809927
https://github.com/datawhalechina/team-learning/blob/master/
https://blog.youkuaiyun.com/m0_37477175/article/details/77145459
http://shuokay.com/2016/06/14/dropout/
https://cloud.tencent.com/developer/article/1087399


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









