




 本文介绍了损失函数的概念及其在机器学习中的应用,包括经验风险、期望风险和结构风险的区别与联系。解释了如何通过最小化结构风险来避免过拟合问题。
本文介绍了损失函数的概念及其在机器学习中的应用,包括经验风险、期望风险和结构风险的区别与联系。解释了如何通过最小化结构风险来避免过拟合问题。
首先引入损失函数的概念:损失函数就一个具体的样本而言,模型预测的值与真实值之间的差距。对于一个样本(xi,yi)其中yi为真实值,而f(xi)为我们的预测值。使用损失函数L(f(xi),yi)来表示真实值和预测值之间的差距。两者差距越小越好,最理想的情况是预测值刚好等于真实值。
常见的损失函数如下:

通过损失函数我们可以得知对于单个样本点的预测能力,对于训练样本集中所有数据的预测可以通过累加得到,这就是经验风险:
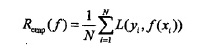
经验风险越小则说明对于训练集数据的拟合程度越好,由于未知样本的数量不知,无法采取平均值的方式求得。这里假设X,Y服从联合分布P(X,Y),期望风险可表示为:
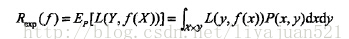
但是由于联合分布函数P(X,Y)是很难求得的。所以期望风险是不容易得到的。
但是如果采用经验风险来代替期望风险,有可能出现过度拟合的问题,即决策函数对于训练集几乎全部拟合,但是对于测试集拟合效果过差,这里又引入结构风险:
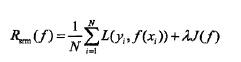
经验风险越小,模型决策函数越复杂,包含参数越多,拟合效果越好,但是到一定程度又容易出现过度拟合的问题,这里引入正则化项,其中λ是参数,J(f)表示模型复杂度,通过降低模型复杂度来防止过拟合的出现,即λJ(f)的值最小化,因为经验风险目的是求的最小化,正则化目的也是求取最小化,因此这里将两者相加来求取最小化,即可得结构风险。
经验风险是局部概念,针对训练样本的损失函数,可以求得。
期望风险是全局概念,针对未知测试样本的损失函数,求不得。
结构风险是两者的折中处理,是经验风险和正则化的加和。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









