 Informer与SharedInformer对比
Informer与SharedInformer对比





 本文详细比较了Kubernetes中informer与SharedInformer的工作流程,重点解析两者在事件处理上的不同:informer直接处理事件,而SharedInformer则先缓存再处理。通过代码示例展示了如何使用SharedInformer监听节点变化。
本文详细比较了Kubernetes中informer与SharedInformer的工作流程,重点解析两者在事件处理上的不同:informer直接处理事件,而SharedInformer则先缓存再处理。通过代码示例展示了如何使用SharedInformer监听节点变化。
我们已经介绍过informer和SharedInformer。那么他们相关的处理流程上有什么不同,下面我们通过流程图来介绍:
informer的处理流程
informer的处理流程,我们以client-go的example/workqueue/main.go的代码为例: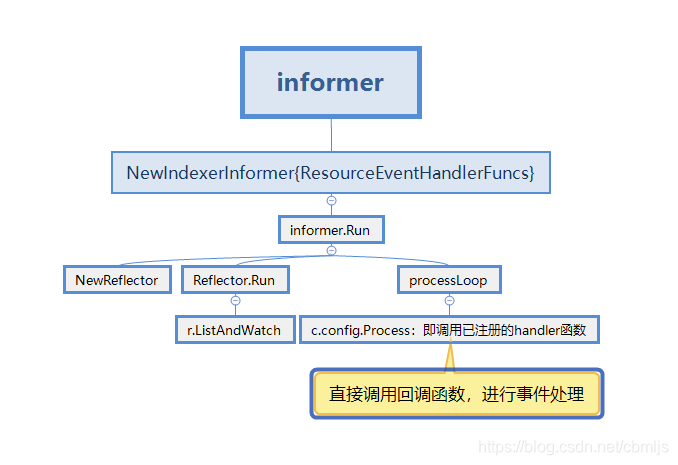
SharedInformer的处理流程
SharedInformer的处理流程,这里自己写了一份代码:
package client_example
import (
"flag"
"fmt"
"log"
"path/filepath"
corev1 "k8s.io/api/core/v1"
"k8s.io/apimachinery/pkg/labels"
"k8s.io/apimachinery/pkg/util/runtime"
"k8s.io/client-go/informers"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/tools/cache"
"k8s.io/client-go/tools/clientcmd"
"k8s.io/client-go/util/homedir"
)
func main() {
var kubeconfig *string
if home := homedir.HomeDir(); home != "" {
kubeconfig = flag.String("kubeconfig", filepath.Join(home, ".kube", "config"), "(optional) absolute path to the kubeconfig file")
} else {
kubeconfig = flag.String("kubeconfig", "", "absolute path to the kubeconfig file")
}
flag.Parse()
config, err := clientcmd.BuildConfigFromFlags("", *kubeconfig)
if err != nil {
panic(err)
}
// 初始化 client
clientset, err := kubernetes.NewForConfig(config)
if err != nil {
log.Panic(err.Error())
}
stopper := make(chan struct{})
defer close(stopper)
// 初始化 informer
factory := informers.NewSharedInformerFactory(clientset, 0) //工厂实例
nodeInformer := factory.Core().V1().Nodes() // 工厂类型
informer := nodeInformer.Informer() // 工厂方法生成informer
defer runtime.HandleCrash()
// 启动 informer,list & watch
go factory.Start(stopper)
// 从 apiserver 同步资源,即 list
if !cache.WaitForCacheSync(stopper, informer.HasSynced) {
runtime.HandleError(fmt.Errorf("Timed out waiting for caches to sync"))
return
}
// 使用自定义 handler
informer.AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: onAdd,
UpdateFunc: func(interface{}, interface{}) { fmt.Println("update not implemented") }, // 此处省略 workqueue 的使用
DeleteFunc: func(interface{}) { fmt.Println("delete not implemented") },
})
// 创建 lister
nodeLister := nodeInformer.Lister()
// 从 lister 中获取所有 items
nodeList, err := nodeLister.List(labels.Everything())
if err != nil {
fmt.Println(err)
}
fmt.Println("nodelist:", nodeList)
<-stopper
}
func onAdd(obj interface{}) {
node := obj.(*corev1.Node)
fmt.Println("add a node:", node.Name)
}
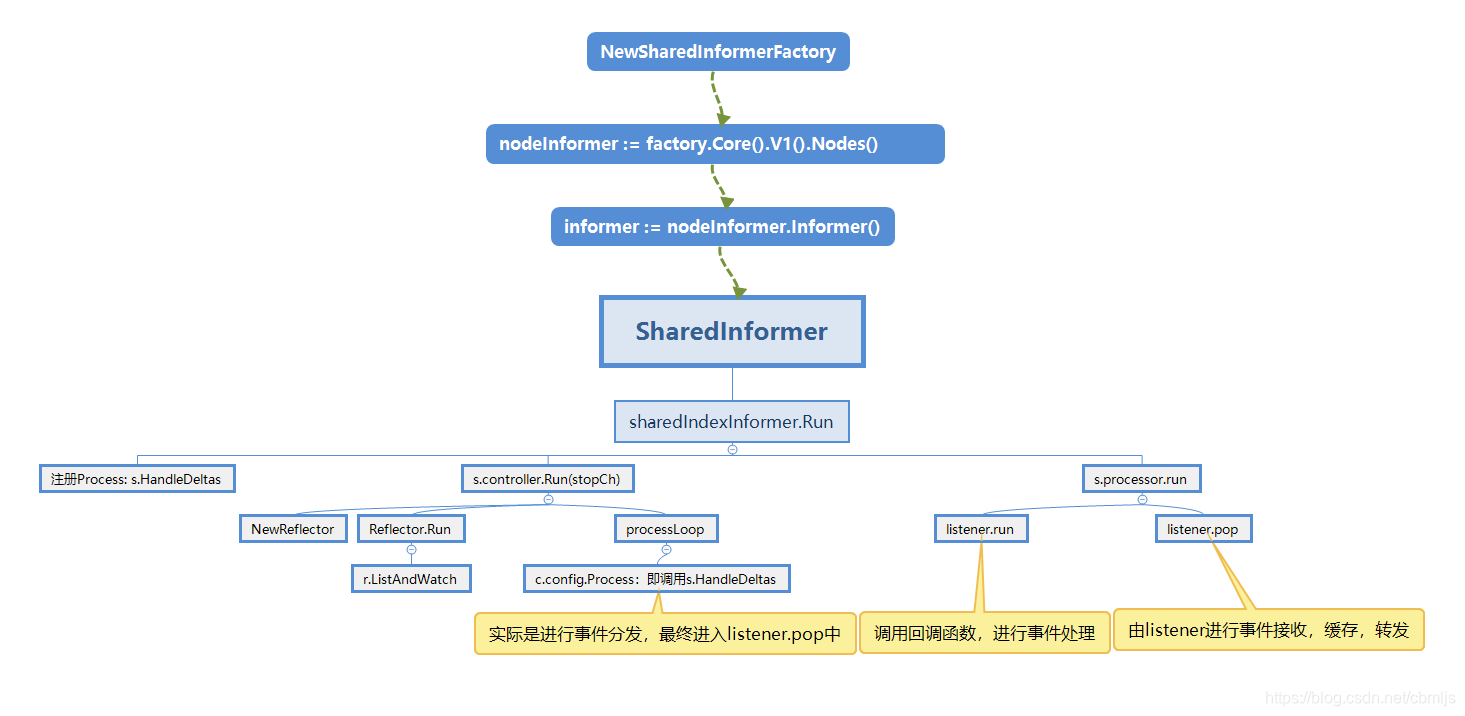
总结
从上面两者的流程图,我们可以看到最大的区别是,在事件触发回调函数时是否直接调用回调函数处理事件。informer是直接处理,SharedInformer是对事件进行接收、缓存,转发之后在进行处理。

















 1193
1193




 到【灌水乐园】发言
到【灌水乐园】发言







