




 本文通过《Python数据分析与挖掘实战》一书,介绍如何利用Python对航空公司客户进行分类,识别高价值客户。文章详细阐述了数据处理、模型建立及应用,包括客户基本信息、乘机和积分信息分析,采用KMeans聚类方法,结合RFM模型优化,旨在制定精准营销策略,提升客户满意度和企业利润。
本文通过《Python数据分析与挖掘实战》一书,介绍如何利用Python对航空公司客户进行分类,识别高价值客户。文章详细阐述了数据处理、模型建立及应用,包括客户基本信息、乘机和积分信息分析,采用KMeans聚类方法,结合RFM模型优化,旨在制定精准营销策略,提升客户满意度和企业利润。
这个专栏用来记录我在学习和实践《Python数据分析与挖掘实战》一书时的一些知识点总结和代码实现。
文章目录
背景和目标
通过客户分类,区分无价值客户、高价值客户,从而针对不同人群制定优化的个性化服务方案,采取不同的营销策略,将有限营销资源集中于高价值客户,实现企业利润的最大化目标。
准确的客户分类结果是企业优化营销资源的重要依据,客户分类越来越成为客户关系管理中急需解决的问题之一。
主要分为以下几个步骤:
1)借助航空公司客户数据,对客户进行分类
2)对不同的客户类别进行特征分析,比较不同类客户的客户价值
3)对不同价值的客户类别提供个性化服务,指定相应的营销策略
数据
客户基本信息
| 属性名称 | 属性说明 |
|---|---|
| MEMBER_NO | 会员卡号 |
| FFP_DATE | 入会时间 |
| FIRST_FLIGHT_DATE | 第一次飞行日期 |
| GENDER | 性别 |
| FFP_TIER | 会员卡级别 |
| WORK_CITY | 工作地城市 |
| WORK_PROVINCE | 工作地所在省份 |
| WORK_COUNTRY | 工作地所在国家 |
| AGE | 年龄 |
乘机信息
| 属性名称 | 属性说明 |
|---|---|
| FLIGHT_COUNT | 观测窗口内的飞行次数 |
| LOAD_TIME | 观测窗口的结束时间 |
| LAST_TO_END | 最后一次乘机时间至观测窗口结束时长 |
| AVG_DISCOUNT | 平均折扣率 |
| SUM_YR | 观测窗口的票价收入 |
| SEG_KM_SUM | 观测窗口的总飞行公里数 |
| LAST_FLIGHT_DATE | 末次飞行日期 |
| AVG_INTERVAL | 平均乘机时间间隔 |
| MAX_INTERVAL | 最大乘机时间间隔 |
积分信息
| 属性名称 | 属性说明 |
|---|---|
| EXCHANGE_COUNT | 积分兑换次数 |
| EP_SUM | 总精英积分 |
| PROMOPTIVE_SUM | 促销积分 |
| PARTNER_SUM | 合作伙伴积分 |
| POINTS_SUM | 总累计积分 |
| POINT_NOTFLIGHT | 非乘机的积分变动次数 |
| BP_SUM | 总基本积分 |
脚本
data_explore.py
#-*- coding: utf-8 -*-
# 对数据进行基本的探索
# 返回缺失值个数以及最大最小值
import pandas as pd
datafile = '../data/air_data.csv' # 航空原始数据,第一行为属性标签
resultfile = '../tmp/explore.xls' # 数据探索结果表
# 读取原始数据,指定UTF-8编码(需要用文本编辑器将数据装换为UTF-8编码)
data = pd.read_csv(datafile, encoding='utf-8')
# 包括对数据的基本描述,percentiles参数是指定计算多少的分位数表(如1/4分位数、中位数等);T是转置,转置后更方便查阅
explore = data.describe(percentiles=[], include='all').T
# print(explore)
# describe()函数自动计算非空值数,需要手动计算空值数
explore['null'] = len(data) - explore['count']
explore = explore[['null', 'max', 'min']]
explore.columns = [u'空值数', u'最大值', u'最小值'] # 表头重命名
'''这里只选取部分探索结果。
describe()函数自动计算的字段有count(非空值数)、unique(唯一值数)、top(频数最高者)、freq(最高频数)、mean(平均值)、std(方差)、min(最小值)、50%(中位数)、max(最大值)'''
explore.to_excel(resultfile) # 导出结果
data_clean.py
#-*- coding: utf-8 -*-
# 数据清洗,过滤掉不符合规则的数据
import pandas as pd
datafile = '../data/air_data.csv' # 航空原始数据,第一行为属性标签
cleanedfile = '../tmp/data_cleaned.csv' # 数据清洗后保存的文件
cleanedfile2 = '../tmp/data_cleaned.xls'
# 读取原始数据,指定UTF-8编码(需要用文本编辑器将数据装换为UTF-8编码)
data = pd.read_csv(datafile, encoding='utf-8')
# NOTE: * instead of &
data = data[data['SUM_YR_1'].notnull() & data['SUM_YR_2'].notnull()
] # 票价非空值才保留
# 只保留票价非零的,或者平均折扣率与总飞行公里数同时为0的记录。
index1 = data['SUM_YR_1'] != 0
index2 = data['SUM_YR_2'] != 0
index3 = (data['SEG_KM_SUM'] == 0) & (data['avg_discount'] == 0) # 该规则是“与”
data = data[index1 | index2 | index3] # 该规则是“或”
# to_csv
data.to_csv(cleanedfile, encoding='utf-8') # 导出结果
data.to_excel(cleanedfile2)
print('END')
zscore_data.py
#-*- coding: utf-8 -*-
# 标准差标准化
import pandas as pd
datafile = '../data/zscoredata.xls' # 需要进行标准化的数据文件;
zscoredfile = '../tmp/zscoreddata.xls' # 标准差化后的数据存储路径文件;
# 标准化处理
data = pd.read_excel(datafile)
# 简洁的语句实现了标准化变换,类似地可以实现任何想要的变换。
data = (data - data.mean(axis=0)) / (data.std(axis=0))
data.columns = ['Z' + i for i in data.columns] # 表头重命名。
data.to_excel(zscoredfile, index=False) # 数据写入
print('END')
KMeans_cluster.py
# -*- coding: utf-8 -*-
# K-Means聚类算法
import pandas as pd
from sklearn.cluster import KMeans # 导入K均值聚类算法
inputfile = '../tmp/zscoreddata.xls' # 待聚类的数据文件
k = 5 # 需要进行的聚类类别数,需结合业务的理解和分析来确定客户的类别数量
# 读取数据并进行聚类分析
data = pd.read_excel(inputfile) # 读取数据
# 调用k-means算法,进行聚类分析
# TODO: error here
# n_jobs是并行数,一般等于CPU数较好 , window下多进程 跑失败
kmodel = KMeans(n_clusters=k, n_jobs=1)
kmodel.fit(data) # 训练模型
from cluster_plot import print_cluster_result, plot_cluster
print_cluster_result(data, kmodel)
plot_cluster(data, kmodel)
print('END')
cluster_plot.py
# -*- coding: utf-8 -*-
# 画出特征雷达图,代码接KMeans_cluster.py
def print_cluster_result(data, kmodel):
import pandas as pd
# 简单打印结果
r1 = pd.Series(kmodel.labels_).value_counts() # 统计各个类别的数目
r2 = pd.DataFrame(kmodel.cluster_centers_) # 找出聚类中心
r = pd.concat([r2, r1], axis=1) # 横向连接(0是纵向),得到聚类中心对应的类别下的数目
r.columns = list(data.columns) + [u'类别数目'] # 重命名表头
print(r)
# print(kmodel.cluster_centers_) # 查看聚类中心
# print('labels_=', kmodel.labels_) # 查看各样本对应的类别
def plot_cluster(data, kmodel):
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
# plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
labels = data.columns # 标签
k = 5 # 数据个数
plot_data = kmodel.cluster_centers_
color = ['b', 'g', 'r', 'c', 'y'] # 指定颜色
angles = np.linspace(0, 2 * np.pi, k, endpoint=False)
plot_data = np.concatenate((plot_data, plot_data[:, [0]]), axis=1) # 闭合
angles = np.concatenate((angles, [angles[0]])) # 闭合
fig = plt.figure()
ax = fig.add_subplot(111, polar=True) # polar参数!!
for i in range(len(plot_data)):
ax.plot(angles, plot_data[i], 'o-', color=color[i],
label=u'客户群' + str(i), linewidth=2) # 画线
ax.set_rgrids(np.arange(0.01, 3.5, 0.5),
np.arange(-1, 2.5, 0.5), fontproperties="SimHei")
ax.set_thetagrids(angles * 180 / np.pi, labels, fontproperties="SimHei")
plt.legend(loc=4)
plt.show()
分析方法和过程
方法
识别客户价值应用最广泛的模型是通过RFM的3个指标
消费时间间隔 Recency
消费频率 Frequency
消费金额 Monetary
本例中做一些优化。
- 用
客户一定时间内积累的飞行里程M、一定时间内乘坐仓位的平均折扣系数C--> 代替消费金额M
(注意:平均折扣系数,是折扣系数的平均值) - 在模型中增加
客户关系长度L
因此本例中 ,建模指标如下:
客户关系长度L
消费时间间隔 Recency
消费频率 Frequency
飞行里程M
平均折扣系数C
针对航空公司的LRFMC模型,如果采用传统的RFM模型分析的属性分箱方法(按照属性的平均值进行划分,大于的表示↑,小于的表示↓),虽然也能识别高价值客户,但是细分的客户群太多,提高了针对性营销的成本。
因此,这个案例里面采用聚类的方法识别客户价值,用LRFMC5个指标进行K-Means聚类,识别出最有价值的客户。
流程
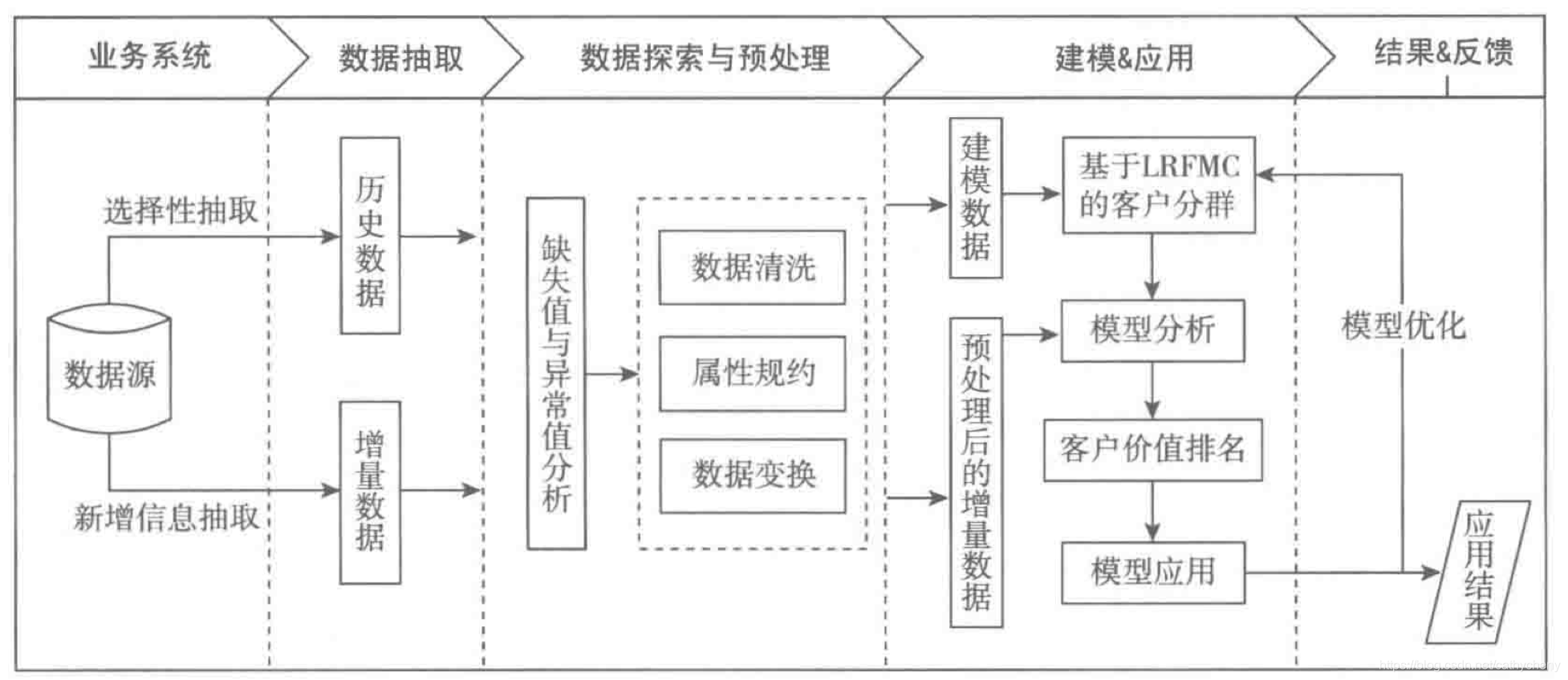
模型解释
模型应用
根据对各个客户群进行特征分析,采取下面一些营销手段和策略,为航空公司的价值客户群管理提供参考。
- 会员的升级与保级
航空公司的会员分为白金卡会员、金卡会员、银卡会员、普通卡会员,其中非普通卡会员可以统称为航空公司的精英会员。(虽然各航空公司有自己的特点和规定,但是规则大同小异。)
成为精英会员一般都是要求在一定时间内(如一年)积累一定的飞行里程或航段,达到这种要求后就会在有效期内(通常为两年)成为精英会员,并享受高级别的服务。
有效期快结束时,根据相关评价方法确定客户是否有资格继续作为精英会员,然后对该客户进行相应的升级或降级。
但是会存在:有客户没有意识到或者根本不了解会员升级或保级的时间与要求,经常在评价期过后才发现自己其实差一点就可以实现升级或保级,却错过了机会,使之前的里程积累白白损失。同时,这种认知还可能导致客户的不满,干脆放弃在本公司的消费。
因此,航空公司可以在对会员升级或保级进行评价的时间点之前,对那些接近但尚未达到要求的较高消费客户进行适当提醒甚至采取一些促销活动,刺激他们通过消费达到相应标准。这样既可以获得收益,同时也提高了客户满意度,增加了公司的精英会员。
- 首次兑换
航空公司常旅客计划中最能够吸引客户的就是可以通过消费积累的里程来兑换免票或免费升舱等。每个公司都有一个首次兑换标准,也就是当客户的里程或航段积累到一定程度时才可以实现第一次兑换,这个标准会高于正常的里程兑换标准。但是很多公司的里程积累随着时间会进行一定的削减(例如有的公司会在年末对该年积累的里程进行折半处理)。这样会导致很多不了解情况的会员白白损失自己好不容易积累的里程,甚至总是难以实现首次兑换。同样会引起客户的不满或流失。
可以采取的措施是从数据库中提取出接近但尚未达到首次兑换标准的会员,对他们进行提醒或促销,使他们通过消费达到标准。一单实现了首次兑换,客户在本公司进行再次消费兑换就比在其他公司进行兑换要容易许多,在一定程度上等于提高了转移的成本。
另外,在一些特殊的时间点(如里程折半的时间点)之前可以给客户一些提醒,这样可以增加客户的满意度。
- 交叉销售
通过发型联名卡等非航空企业的合作,使客户在其他企业的消费过程中获得本公司的积分,增强于公司的联系,提高他们的忠诚度。例如,可以查看重要客户在非航空类合作伙伴处的里程积累情况,找出他们习惯的里程积累方式(是否经常在合作伙伴处消费、更喜欢消费哪些类型合作伙伴的产品),对他们进行相应促销。
客户识别和发展期为客户关系打下基石,但这两个时期带来的客户关系是短暂的、不稳定的,企业要获取长期的利润,必须具有稳定的、高质量的客户。保持客户对于企业来说是至关重要的,不仅因为争取一个新客户的成本远远高于维持老客户的成本,更重要的是客户流失会造成公司收益的直接损失。
因此,在这一时期,航空公司应该努力维持客户关系,使之处于较高的水准,最大化生命周期内公司与客户的互动价值,并使这样的高水平尽可能延长。对于这一阶段的客户,主要应该通过提供优质的服务产品和提高服务水平来提高客户的满意度。
如果高质量客户的占比较少,航空公司应该优先将资源投放到他们身上,对他们进行差异化管理和一对一营销,提高这类客户的忠诚度与满意度,尽可能延长这类客户的高水平消费。
拓展
上面的例子只有针对客户价值进行分析,对客户流失并没有提出具体的分析。
针对客户流失分析可以从以下方面来考虑:
1)定义
老客户的定义:将飞行次数大于6次的客户定义为老客户已流失客户的定义:第二年飞行次数与第一年飞行次数比例少于50%的客户准流失客户的定义:第二年飞行次数与第一年飞行次数比例在[50%, 90%)的客户未流失客户的定义:第二年飞行次数与第一年飞行次数比例大于90%的客户
2)选取客户信息中的关键属性 进行建模,运用模型预测未来客户的类别归属(未流失、准流失或已流失)
- 如(会员卡级别、客户类型(流失、准流失、未流失)、平均乘机时间间隔、平均折扣率、积分兑换次数、非乘机积分总和、单位里程票价和单位里程积分等,用80%的数据作为分类的训练样本,剩余的20%作为测试样本,构建客户流失模型。


















 438
438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









