 SmolVLA模型代码解析
SmolVLA模型代码解析





1.数据预处理
首先看modeling_smolvla.py中forward函数:
def forward(self, batch: dict[str, Tensor], noise=None, time=None) -> dict[str, Tensor]:
"""Do a full training forward pass to compute the loss"""
if self.config.adapt_to_pi_aloha:
batch[OBS_STATE] = self._pi_aloha_decode_state(batch[OBS_STATE])
batch[ACTION] = self._pi_aloha_encode_actions_inv(batch[ACTION])
batch = self.normalize_inputs(batch)
batch = self.normalize_targets(batch)
images, img_masks = self.prepare_images(batch)
state = self.prepare_state(batch)
lang_tokens, lang_masks = self.prepare_language(batch)
actions = self.prepare_action(batch)
actions_is_pad = batch.get("actions_id_pad")
# print(f"---batch action33----={batch[ACTION]} | {batch[ACTION].shape} | {actions}")
loss_dict = {}
losses = self.model.forward(images, img_masks, lang_tokens, lang_masks, state, actions, noise, time)
loss_dict["losses_after_forward"] = losses.clone()
if actions_is_pad is not None:
in_episode_bound = ~actions_is_pad
losses = losses * in_episode_bound.unsqueeze(-1)
loss_dict["losses_after_in_ep_bound"] = losses.clone()
# Remove padding
losses = losses[:, :, : self.config.max_action_dim]
loss_dict["losses_after_rm_padding"] = losses.clone()
# For backward pass
loss = losses.mean()
# For backward pass
loss_dict["loss"] = loss.item()
return loss, loss_dict(1)这个函数首先归一化处理,
batch = self.normalize_inputs(batch)
batch = self.normalize_targets(batch)
训练的时候先设置为inf
mean = torch.ones(shape, dtype=torch.float32) * torch.inf
std = torch.ones(shape, dtype=torch.float32) * torch.inf
然后通过采集数据集中state、action的均值和方差。分别是输入数据、输出数据、反归一化值
self.normalize_inputs = Normalize(...) # 输入归一化
self.normalize_targets = Normalize(...) # 训练目标归一化
self.unnormalize_outputs = Unnormalize(...) # 输出反归一化
注意这里:如果训练过程中加载模型,上面均值和方差参数会被模型中的统计参数覆盖掉。
2.图像数据预处理
images, img_masks = self.prepare_images(batch)
这段主要代码功能为:
1.像素值[0,1]->[-1,1]
2.图像resize至正方形224x224,图像长宽比不变,其他区域用黑色补充,标记为mask=1,若占位图像(摄像头缺失),则 创建全-1像素的占位图像 标记为mask=0,image为[16, 3, 512, 512](B,C,H,W),这里的batch_size为16,图像大小为3*512*512,图像img_mask为True,masks列表长度为2,img_masks为2,因为我这里两个相机。这里是训练时候的长度大小。
整个代码如下:
def prepare_images(self, batch):
"""Apply SmolVLA preprocessing to the images, like resizing to 224x224 and padding to keep aspect ratio, and
convert pixel range from [0.0, 1.0] to [-1.0, 1.0] as requested by SigLIP.
"""
images = []
img_masks = []
present_img_keys = [key for key in self.config.image_features if key in batch]
missing_img_keys = [key for key in self.config.image_features if key not in batch]
if len(present_img_keys) == 0:
raise ValueError(
f"All image features are missing from the batch. At least one expected. (batch: {batch.keys()}) (image_features:{self.config.image_features})"
)
# Preprocess image features present in the batch# 调整大小并填充(保持宽高比)
for key in present_img_keys:
img = batch[key][:, -1, :, :, :] if batch[key].ndim == 5 else batch[key]
if self.config.resize_imgs_with_padding is not None:
img = resize_with_pad(img, *self.config.resize_imgs_with_padding, pad_value=0)
# Normalize from range [0,1] to [-1,1] as expacted by siglip
img = img * 2.0 - 1.0
bsize = img.shape[0]
device = img.device
if f"{key}_padding_mask" in batch:
mask = batch[f"{key}_padding_mask"].bool()
else:
mask = torch.ones(bsize, dtype=torch.bool, device=device)
images.append(img)
img_masks.append(mask)
# Create image features not present in the batch
# as fully 0 padded images.
for num_empty_cameras in range(len(missing_img_keys)):
if num_empty_cameras >= self.config.empty_cameras:
break
img = torch.ones_like(img) * -1
mask = torch.zeros_like(mask)
images.append(img)
img_masks.append(mask)
return images, img_masks3.state数据预处理
state = self.prepare_state(batch)
这段代码主要将state的维数使用“0”从6维pad至32维,state:[16, 32]
def prepare_state(self, batch):
"""Pad state"""
state = batch[OBS_STATE][:, -1, :] if batch[OBS_STATE].ndim > 2 else batch[OBS_STATE]
state = pad_vector(state, self.config.max_state_dim)
return state4.language数据预处理
lang_tokens, lang_masks = self.prepare_language(batch)、
用HuggingFaceTB/SmolVLM2-500M-Video-Instruct对task分词,task文本长度pad至48,lang_tokens为文本的token ID序列,lang_masks为对应的attention mask,用于标识哪些是有效token。我这里输入lang_tokens为[16, 10],lang_masks全为true,
注意:这里的长度10是根据提示词长度变化的,我输入的提示词为10,可以用下面代码测试你的长度。
for i, task in enumerate(tasks[:3]): # 检查前3个
test_tokens = self.language_tokenizer.encode(task)
print(f"任务 {i} 的token长度: {len(test_tokens)}") def prepare_language(self, batch) -> tuple[Tensor, Tensor]:
"""Tokenize the text input"""
device = batch[OBS_STATE].device
tasks = batch["task"]
if len(tasks) == 1:
tasks = [tasks[0] for _ in range(batch[OBS_STATE].shape[0])]
tasks = [task if task.endswith("\n") else f"{task}\n" for task in tasks]
tokenized_prompt = self.language_tokenizer.__call__(
tasks,
padding=self.config.pad_language_to,
padding_side="right",
max_length=self.config.tokenizer_max_length,
return_tensors="pt",
)
lang_tokens = tokenized_prompt["input_ids"].to(device=device)
lang_masks = tokenized_prompt["attention_mask"].to(device=device, dtype=torch.bool)
return lang_tokens, lang_masks5.action数据预处理
actions = self.prepare_action(batch)
主要将action的维数扩充到32维,大小为(batch_size x sequence_length x features_dimension),大小为([16, 5, 32]
def prepare_action(self, batch):
"""Pad action"""
actions = pad_vector(batch[ACTION], self.config.max_action_dim)
return actions6.生成噪声
sample_noise(actions.shape, actions.device)
生成和actions size相同的高斯噪声
7.生成time
self.sample_time(actions.shape[0], actions.device)
time数值分布在[0.001,0.999]之间,控制噪声和action的混合比例,用于后续流匹配的训练
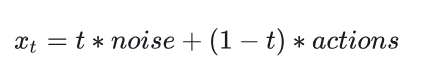
time接近1,输入接近噪音,反之接近原始actions
注意这里训练是由action到噪声
8.生成target
模型的主要思想为流匹配,模型拟合出噪声->动作(目前看来是动作->噪声反向拟合了)的运动趋势,即:
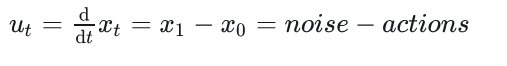
9.前缀嵌入
prefix_embs, prefix_pad_masks, prefix_att_masks = self.embed_prefix(
images, img_masks, lang_tokens, lang_masks, state=state
)
代码的流程是依次对输入图像、语言、机器状态进行分别做embedding,然后进行按列合并为一个前缀输入。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2910
2910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









