






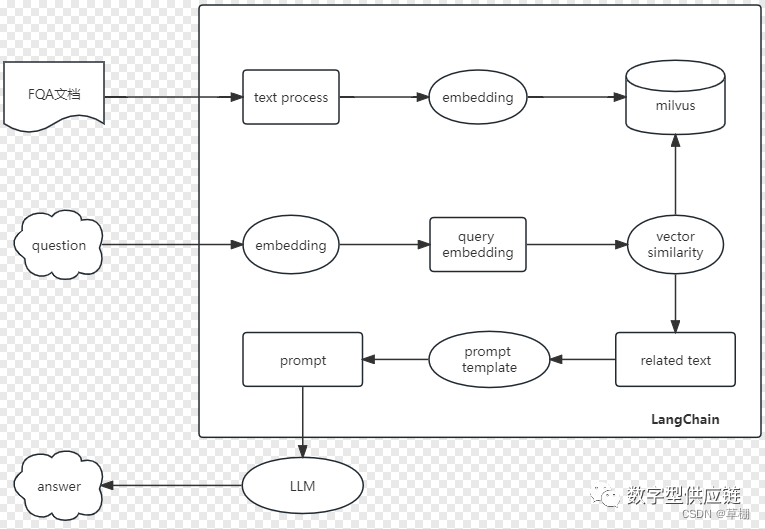
一.知识库架构图
本文基于langchain+milvus+llm对原先的知识库进行重新构建,整体的架构如下:
二.实现步骤
1.首先对已有的FAQ以及相应的规章制度文档进行梳理;
2.对重复的问题和答案进行合并;
3.使用embedding模型对问题和答案进行embedding;
4.将FAQ文档embeding后插入到向量数据库milvus中;
5.对用户输入的问题进行embedding;
6.对问题的embedding在向量数据库milvus中进行相似搜索相似距离小于0.2且前3的答案;
7.使用LLM对返回的结果进行总结;
8.输出LLM总结后的结果作为输出返回给用户;
三.实现结果
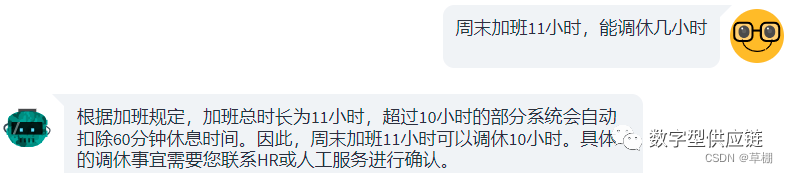
下面是使用m3e-base模型作为embedding模型,openai gpt3.5作为llm输出的结果:
原本的制度里面是:加班时长大于等于10小时,扣除60分钟的休息,加班时间在5-10小时,扣除30分钟的休息。
从结果可以看出llm能判别出11小时需要扣除60分钟的休息时间,且准确计算出调休10小时。
四.后续
后续我会对比llama,alpaca,chatglm等模型的效果;

















 1536
1536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









