





具有代表性的全局原型的小样本学习
引用:Liu Y, Shi D, Lin H. Few-shot learning with representative global prototype[J]. Neural Networks, 2024, 180: 106600.
论文地址:下载地址
Abstract
小样本学习通常面临低泛化性能的问题,因为它假设新类别和基础类别的数据分布是相似的,而模型仅在基础类别上进行训练。为了缓解上述问题,我们提出了一种基于代表性全局原型的小样本学习方法。具体来说,为了增强对新类别的泛化能力,我们提出了一种方法,通过选择代表性和非代表性的样本,分别优化代表性全局原型,从而联合训练基础类别和新类别。此外,我们还提出了一种方法,通过条件语义嵌入有机地结合基础类别的样本,利用原始数据生成新类别的样本,从而增强新类别的数据。结果表明,这种训练方法提高了模型描述新类别的能力,改善了小样本分类的性能。在两个流行的基准数据集上进行了大量实验,实验结果表明该方法显著提高了小样本学习任务的分类能力,并达到了当前最先进的性能。
1. Introduction
深度学习的优势依赖于大数据,在大数据的驱动下,机器可以有效地进行学习。然而,数据量不足会导致一些问题,如模型过拟合,这使得模型在训练数据之外的数据集上的拟合效果不佳,表现出较弱的泛化能力。因此,小样本学习(Few-shot Learning, FSL)已成为解决这一问题的关键技术。小样本学习是指每个类别使用少量标注数据进行训练,使得模型展现出更高的性能,这符合人类学习的规律。
元学习(Meta-learning)是大多数现有小样本学习方法的基础。在元学习中,训练被建模为一种测试任务,即基础类别和新类别都从 N-way K-shot 的少量样本中学习任务,之后从基础类别中通过适当的初始条件进行知识迁移。这些方法的核心是通过嵌入或优化策略来传递知识。然而,所有这些方法都有一个根本性的局限性:模型假设基础类别数据和新类别数据的分布是相似的,因此大多数仅使用基础类别数据进行学习,而这并不保证它们能够很好地泛化到新类别的数据上。
一种小样本学习方法利用知识的可迁移性,通过少量标记样本学习表征新类别样本的能力,而传统的机器学习和深度学习在训练开始时将所有类别的样本都输入模型中。一旦数据分布的一致性较低,转移的知识就无法有效地推广到新类别的数据上。因此,学习所有类别数据的全局表示可以缓解机器学习和深度学习中基础类别过拟合的问题。新类别数据在一开始就进行学习,度量新类别数据和全局表示增强了新类别样本的判别性。同时,Wang 等人提出的样本合成策略被用来增强新类别的样本,以缓解样本不平衡问题。然而,由于全局原型是直接使用所有样本进行优化的,因此它并不具有代表性。此外,样本生成方法实际上要求基础类别数据和新类别数据具有相似的分布,这并没有打破基本的限制。最后,生成过程并没有直接参与样本训练,也无法优化生成样本的质量。
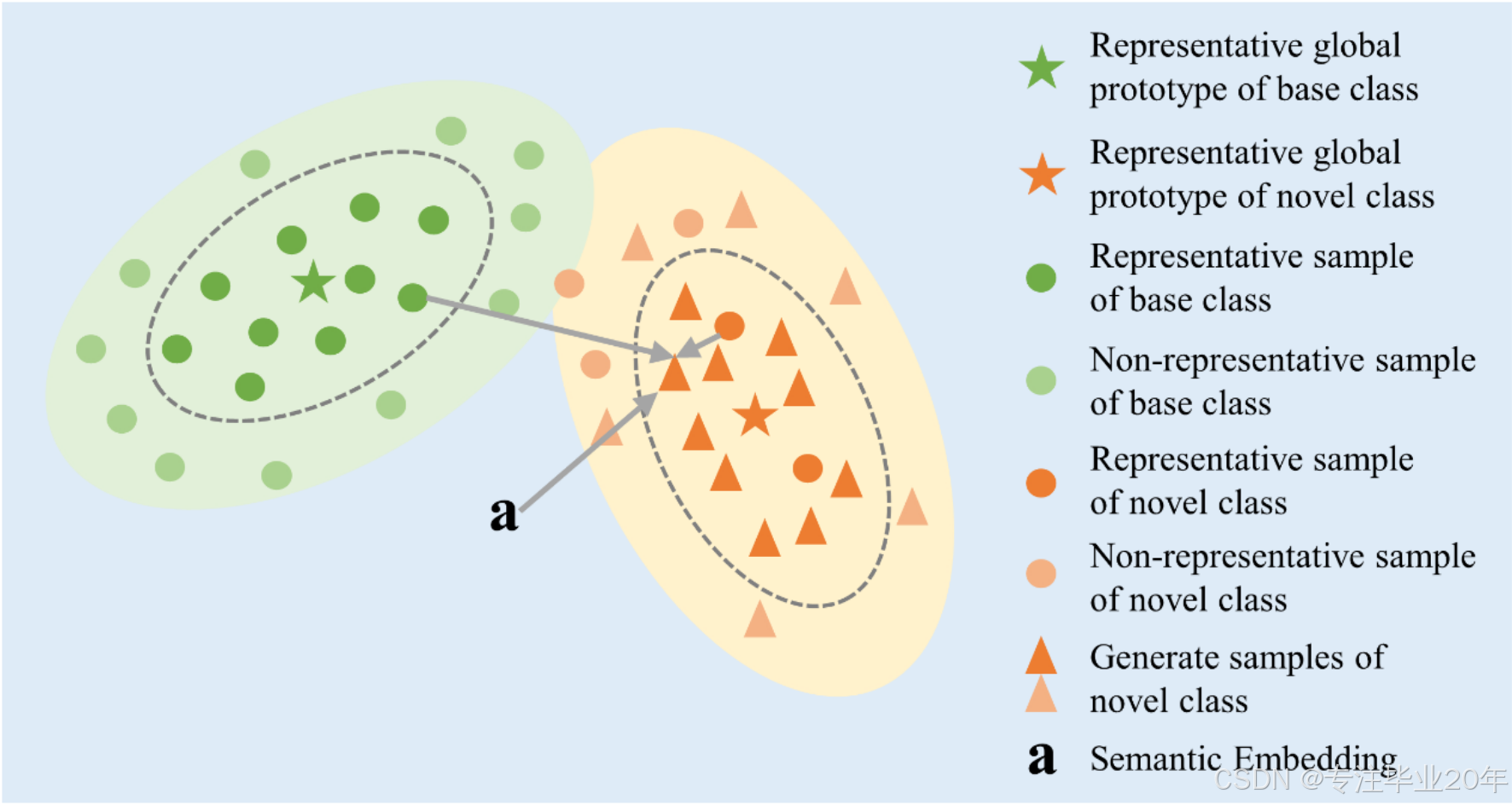
图 1:代表性全局原型的示意图。通过结合基础类的代表性样本、语义嵌入和新类样本,我们能够生成新的样本,这些样本随后用于训练代表性全局原型。
因此,我们提出了一种新的小样本学习方法,以解决小样本数据的泛化能力差和样本不平衡的问题,更好地描述新类别的数据。新类别和从基础类别中选取的代表性和非代表性数据一起输入网络,共同学习数据的表征能力,因此称为代表性全局原型。在我们看来,小样本学习模型不必满足新类别和基础类别数据分布相似的障碍,并且在训练时使用新类别数据会更适合识别新类别。 然而,尝试学习基础类别和新类别的全局原型需要克服新类别中稀疏数据的不平衡问题。为了解决基础类别和新类别数据分布之间的强相关性,我们提出了一种新的样本生成策略。具体来说,如同 Xu所述,使用 CVAE生成模型,基于语义嵌入选择更多代表性样本来为新类别生成更多代表性特征。在上述操作中,我们获得了与新类别强相关的增强数据,并将基础类别作为辅助信息。
我们的主要贡献总结如下: (1) 我们提出了一种新的小样本学习联合训练策略,通过代表性和非代表性样本打破了元学习的假设。 (2) 我们提出了一种样本合成方法来增强新类别的数据。 (3) 实验结果表明,我们的方法在 miniImageNet 和 tieredImageNet 数据集上展现了最先进的性能。
2. Related Work
2.1. Few-Shot Learning
少样本学习(Few-shot learning, FSL)在我们只有非常有限的训练样本时发挥作用。近年来,大多数深度学习方法依赖于元学习(meta-learning)或学习如何学习(learning-to-learn)策略,通过提供的数据集和元学习者在不同任务之间提取的元知识,来提升新任务的性能。具体来说,元学习者将从许多基础类别任务中学到的知识迁移,以帮助少样本学习完成新类别的训练任务。
目前,通过元学习实现的代表性少样本学习可以分为三类:基于微调的、基于度量的和基于优化的。(1)第一类方法旨在为训练新类别样本学习合适的初始化参数,从而更快更好地训练新分类器。第二类方法学习有效的度量,核心在于通过核函数学习有效的判别特征。具体来说,度量学习通过学习嵌入模块和度量模块计算两个样本之间的相似度。所有类别的样本通过嵌入模块被嵌入到向量空间中,然后基于度量模块给出相似度分数。第三类方法通过替换通用优化方法,为元学习场景适配优化器。然而,上述基于元学习的方法都有一个共同的限制:新类别的样本在训练阶段并未出现,因此模型容易在基础类别上发生过拟合。
2.2. Global Representation Learning
通过学习所有类别数据的全局表示,可以缓解模型过拟合问题。该方法旨在为新类别样本的分类学习全局表示。然而,并非所有标注样本都同样重要,非代表性的样本可能会影响全局表示的准确性。模型训练可以根据采样策略涉及不同的采样实例。大多数主流工作集中在影响决策边界的样本上,这在主动学习中更为常见,其中通过不同的不确定性度量选择影响分类的训练样本。与此不同,采样时对数据分布的代表性关注较少。在少样本学习(FSL)中,Xu 和 Le 提出了一种仅使用代表性样本来拟合全局表示的方法,但该方法忽略了数据的整体分布。因此,提出了一种代表性的全局表示方法。为了优化全局表示的代表性,生成了两个损失函数,分别使用代表性样本和非代表性样本。
2.3. Conditional Variational Autoencoder
过去,条件变分自编码器(Conditional VAE, CVAE)已被用于建模各种计算机视觉任务中的特征分布,包括图像分类、图像生成、图像恢复或视频处理。实际上,VAE模型是通过训练学习训练集的数据分布。如报告所述,VAE可以利用基础类别的数据固定参数生成新类别的数据。然而,问题在于,使用仅包含基础类别数据所学得的参数虽然适合基础类别生成更好的数据,但并不一定适合新类别数据。因此,提出了使用条件变分自编码器(CVAE)的方法,结合提取的基础类别数据的特征,并基于语义嵌入生成新类别数据的特征或图像。通过这种方式,可以利用通用语义嵌入作为基础类别与新类别之间的桥梁,更加准确地生成新类别的数据。然而,这些方法本质上仍然是在元学习的假设下进行的。因此,我们提出了一种新的样本生成策略,充分利用新类别和基础类别数据合成新数据。这种方法不依赖于基础类别数据训练的参数,同时也有助于新类别的分类。
3. Method
我们模型的关键思想是通过使用代表性样本和非代表性样本,联合学习基础类别和新类别的代表性全局原型。此外,我们还采用了一种新的样本生成策略,用于新类别,以克服样本不平衡问题。在本节中,我们将首先讨论这两个关键组件,然后回顾整个过程。
3.1. Problem Definition
在本节中,我们进行数据分配。共有 N N N 类样本,记作 Call = c 1 , c 2 , … , c N \text{Call} = { c_1, c_2, \dots, c_N } Call=c1,c2,…,cN。类别集 Call \text{Call} Call 由两个不相交的集合组成:一个是基础类别集 C base C_{\text{base}} Cbase,另一个是新类别集 C novel C_{\text{novel}} Cnovel。请注意,训练集 D train D_{\text{train}} Dtrain 中的类别来自 Call \text{Call} Call 但不属于 C base C_{\text{base}} Cbase。而测试集 D test D_{\text{test}} Dtest 的样本来自于 C novel C_{\text{novel}} Cnovel 中的类别。训练集和测试集的类别集合是互不重叠的,即 D train ∩ D test = ∅ D_{\text{train}} \cap D_{\text{test}} = \emptyset Dtrain∩Dtest=∅。在 D train D_{\text{train}} Dtrain 中,基础类别的样本有足够的标签,但新类别的样本非常有限,只有 n few n_{\text{few}} nfew( n few ≤ 5 n_{\text{few}} \leq 5 nfew≤5)个标注样本。从 D train D_{\text{train}} Dtrain 中采样 n s n_s ns 个代表性的基础类别样本和少量的新类别样本来形成一个支持集 S = ( x i , y i ) , i = 1 , … , n s × N S = { (x_i, y_i), i = 1, \dots, n_s \times N } S=(xi,yi),i=1,…,ns×N,而非代表性的样本则组成查询集 Q = ( x k , y k ) , k = 1 , … , n q × N Q = { (x_k, y_k), k = 1, \dots, n_q \times N } Q=(xk,yk),k=1,…,nq×N。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1354
1354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









