



Part.1
AI工程师都要会些什么?
大语言模型(Large Language Model,LLM)技术的兴起,正在深刻影响软件的形态,开发者的工作也从实现业务逻辑、构建独立应用,转向以LLM为底层引擎快速搭建智能应用的模式。
当下,传统软件也许都要基于AI重写一遍,而这对开发者提出了新的要求:开发者要从单一的代码编写者成为驾驭大模型能力的AI工程师。那么,要如何修炼自己的LLM开发技术栈呢?
首先是深入理解当前主流大模型的核心架构——Transformer模型,明晰自注意力机制如何捕捉文本语义、多头注意力如何并行处理信息,这是自定义大模型结构的基础。
接着要知晓LLM可能存在的不足之处,通过提示词工程、微调、检索增强生成(Retrieval-Augmented Generation,RAG)等技术工具解决知识过时问题。
此外,还要掌握框架工具的使用,例如LlamaIndex、LangChain等,学会编排大模型应用,比如构建“检索 + 生成”的问答系统。最后是构建智能体驱动LLM自主决策,部署LLM应用并监控其稳定运行。
针对这些知识,小白要学多久才能上手干活?只需读完《动手构建大模型》这本书即可。全书没有废话,讲完必要的理论,直接手把手给出实操案例,读者照着书做便能积累实战经验,在工作中边用边提升,稳步成长为LLM应用开发实战高手。

▼点击下方,即可购书
事不宜迟,这就动手开始学吧。
Part.2
零基础进阶大模型实战高手
本书为读者规划了一条循序渐进的学习路线,零基础也能轻松上手。书中内容分为三大篇:基础理论篇解读LLM的概念、核心架构及其不完美之处;核心技术篇详解提示词工程、RAG、LLM框架工具;高阶应用篇讲透高级RAG、Agent(智能体)、微调、LLM部署与优化。
为获得更好的学习体验,读者需要具备简单的Python编程知识,并在计算机上搭建一个版本高于3.8.1的Python编程环境,以使用Visual Studio Code工具。在学习过程中一定要积极动手实践,从而快速吸收所学知识。

我们现在正式踏上学习之旅。
基础理论篇
开篇用通俗的语言拆解LLM的组成结构,从Transformer架构的核心逻辑,到分词、嵌入、上下文窗口这些基础概念,梳理LLM的发展简史,并给出用GPT-3.5 API做翻译、通过小样本学习控制LLM输出的实战小项目。
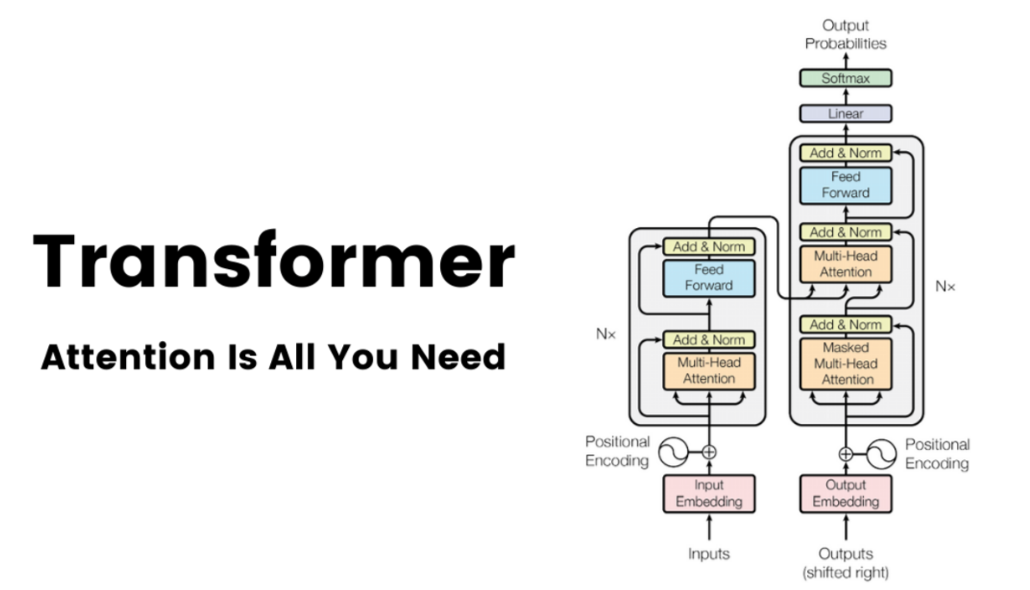
接着深入讲解Transformer架构,阐释“Attention Is All You Need”论文的核心内容,拆解编码器 - 解码器、仅解码器等设计选择,对比专有模型与开源模型,还列出了LLM在商业、医疗、教育等9大领域的应用场景。
最后解释了LLM产生幻觉(生成错误信息)、偏见等问题的根源,并给出应对之道:通过控制输出格式、调整解码方法减轻幻觉,用基准测试评估模型性能。
核心技术篇
打好基础之后,本篇就聚焦LLM应用核心技术,教大家如何与LLM对话,向其输入特定数据,建立知识库。
首先,讲透提示工程的核心技巧:
零样本提示:不提供示例,直接让模型完成任务。
上下文学习和小样本提示:给出一些示例,提示模型给出符合期望的回答。
思维链(CoT)提示:驱使LLM逐步思考,以提供推理能力。
角色提示:给模型设定身份,获得专业方向的精确回答。
然后,以RAG手段解决LLM知识过时、产生幻觉等问题,详解从头构建RAG管道,把文档转成嵌入向量、存进向量数据库、查询时让模型结合检索结果生成答案,从此大模型便能引用专属数据,生成准确内容。
接着,介绍LangChain和LlamaIndex两大框架的用法,用两个项目实战演示:构建新闻摘要器、使用LangChain构建 LLM驱动的应用。动手跟着做一遍,就能秒懂如何搭建LLM应用的骨架。
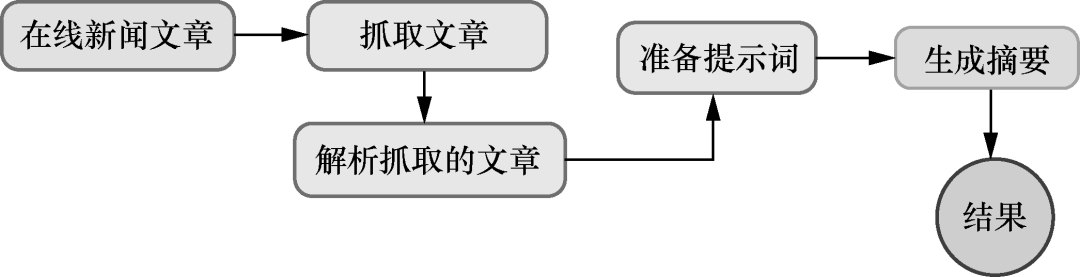
▲新闻文章摘要器的工作流程
将上述工具和框架综合运用,书中给出了贴近真实场景的项目开发实例:
用LangChain做知识图谱:从文本中提取关联关系,让LLM输出更加结构化。
搭建客服问答机器人:把专业领域知识投放给模型,用户提问时自动匹配答案,解放人工。
做YouTube视频摘要器:用Whisper转语音为文本,再让LLM生成摘要,多模态应用轻松实现。
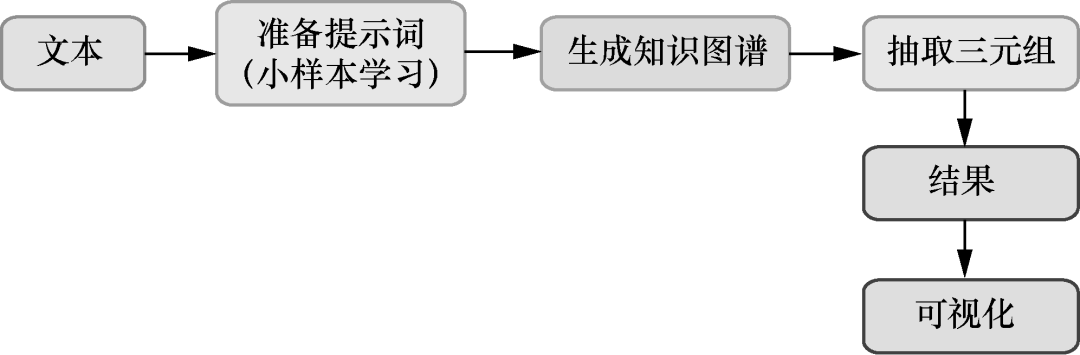
▲基于文本数据创建知识图谱的工作流程
这些项目都提供了Google Colab Notebook方式,“开箱即练”,可以直接在云端运行,不用本地配置复杂环境,方便学习并获得反馈。
高阶应用篇
能用工具干活了,接下来学习解决难题、优化性能、部署上线,覆盖企业级应用的全流程。
首先重点讲解基于LlamaIndex的高级RAG技术,包括嵌入模型与LLM微调、RAG监控与评估、混合检索与嵌入向量检索。LlamaIndex查询环节,涵盖查询构建、查询扩展、查询转换、重排序、递归检索以及从小到大的检索逻辑。
还介绍了RAG评估方法,教你如何衡量检索效果。这些都是企业评估LLM应用的标准流程,掌握后即可与专业工程师对齐。
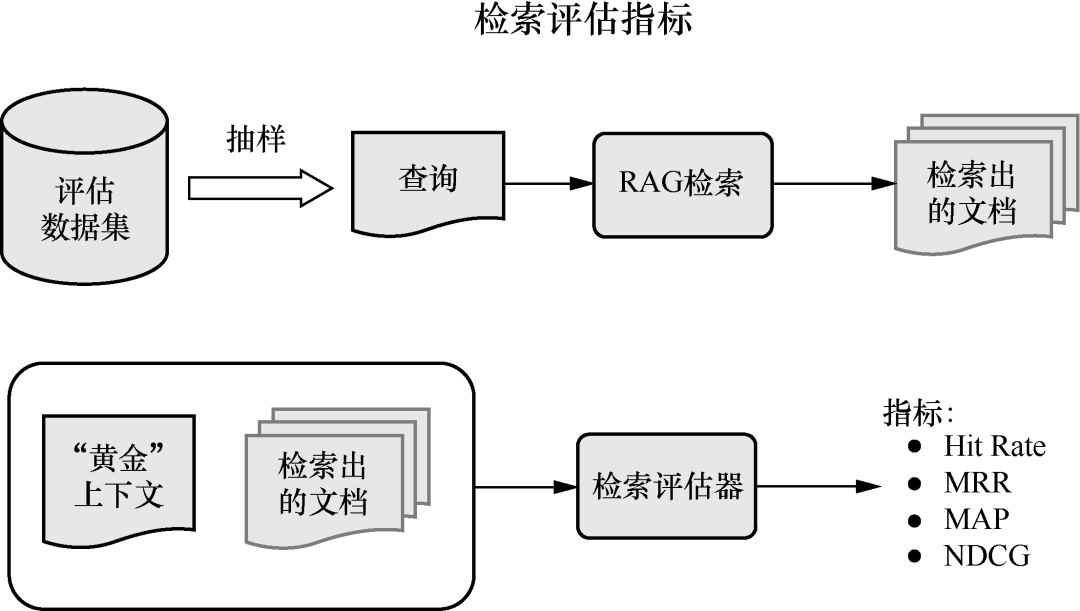
▲RAG系统中的检索评估指标
智能体是大模型的进阶形态,能自主调用工具、规划任务。书中给出多种智能体构建案例:用OpenAI Assistants做分析助手、用 LlamaIndex做数据库查询智能体,还讲解了AutoGPT、BabyAGI等经典智能体的原理。
如果API调用的通用模型满足不了需求,就需要使用微调技术,书中讲透了LoRA、RLHF等微调技术,并给出详细的行业案例,包括用医疗数据微调LLM、用金融数据做情感分析。
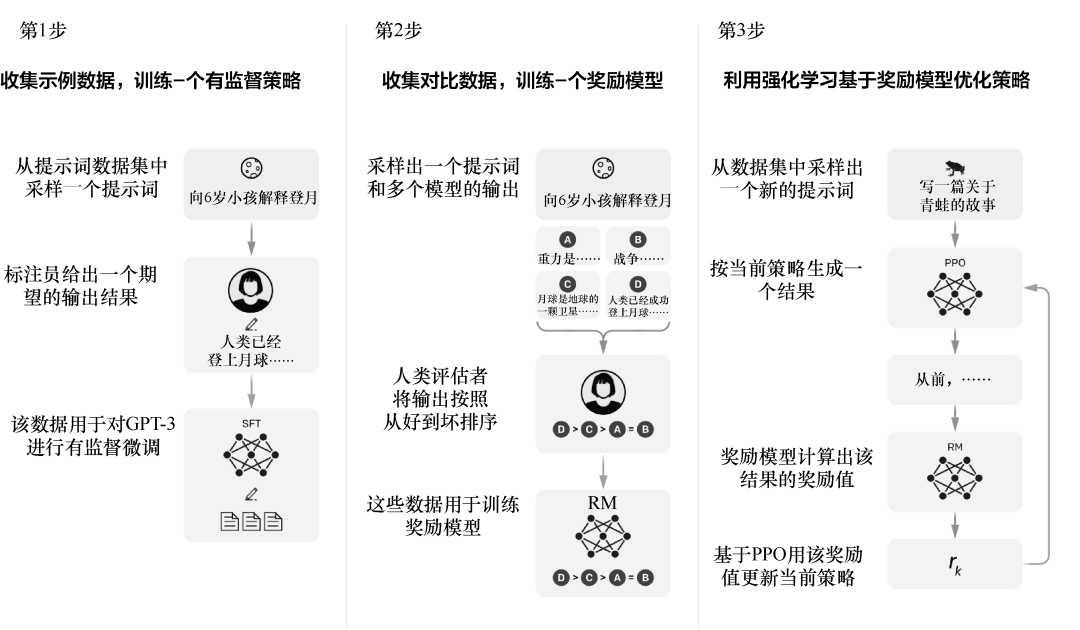
▲RLHF过程的可视化示意图
最后讲解模型部署上线步骤,部署优化环节涵盖使用模型量化、剪枝、蒸馏、投机解码,还演示了在谷歌云CPU上部署量化模型的具体过程。
至此,读者完成了AI工程师的能力闭环。
作者团队介绍
本书作者团队有着深厚的学术积淀、一线工程实战经验与教育传播能力。他们创作本书,旨在为读者打开LLM工程应用的大门,让更多人参与用AI技术改变世界的行动中。
路易斯 - 弗朗索瓦・布沙尔 蒙特利尔学习算法研究所医学人工智能博士,2020年起担任初创公司AI部门负责人,组建团队推进早期计算机视觉研发项目,开设个人YouTube频道分享AI知识,专注于AI现实应用落地。
路易・彼得斯 拥有帝国理工学院物理学专业背景,曾就职于摩根大通集团从事投资研究。他现任Towards AI首席执行官,密切关注AI带来的颠覆性社会影响和经济影响,持续推动AI在更多实际场景中落地的技术突破。
Towards AI 的使命是通过课程、博客、教程、新闻、图书和Discord社区,让AI技术触手可及。自2019年以来,已经帮助超过40万人了解AI知识。
Part.3
结语
对于技术人来说,要想尽快让LLM为业务赋能,就一定要动手真刀真枪地干起来。《动手构建大模型》提供了最直接的实操过程,不绕弯子,精准解决各类实际智能化应用需求。
本书最大特点是实战导向、项目驱动学习,代码完整可复用,案例丰富多元。每章均配套“小案例 + 大项目”,且项目贴合真实业务场景。
基础阶段:GPT-3.5 API翻译、小样本学习控制输出,助力新手快速上手;
核心阶段:新闻摘要器、客服问答机器人、YouTube视频摘要器,覆盖文本处理、多模态交互等高频需求;
高级阶段:医疗数据微调 LLM、谷歌云部署量化模型,直接对标企业级任务。
书中语言通俗易懂,方便零基础学习者快速入门,每章固定设置理论讲解、代码演示、项目实战模块,不同层次的读者可以快速定位自己的核心内容,切实掌握技术并应用落地。

▲精彩书摘
另外,本书学习体验优异,提供Google Colab Notebook,所有项目代码均适配云端环境,读者无须本地配置复杂依赖,复制链接即可运行,大幅降低实践门槛。
配套资源丰富,在towardsai.net/book提供代码仓库、requirements.txt依赖清单、研究论文链接,且代码定期更新以适配LLM生态变化,确保可复现性。

▲代码示例
无论是想从传统程序员转型AI工程师,还是需要落地大模型应用的企业工程师,又或者是高校相关专业的师生,都能在书中找到对应学习模块,从理论到实践全贯通。
吃透理论,熟练应用,《动手构建大模型》助你零基础进阶大模型实战高手!

















 477
477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









