



大家好,我是菜哥!
公众号菜鸟学Python主理人,2017年开始做公众号,从0做起做到31万粉丝,累计写了700多篇Python原创,副业变现7位数,目前是Python领域的头部大号,涉猎量化,AI编程,智能体开发,AI应用开发。
当下2025是智能体大爆发的元年,因为我觉得智能体这个赛道是一个大有可为的赛道,立志打造通过趣味的案例来帮助零基础学习智能体,并通过智能体来提效变现的社群!
下面分享一个智能体案例,有兴趣的可以看看!
比如我们的自选股里有这样的:
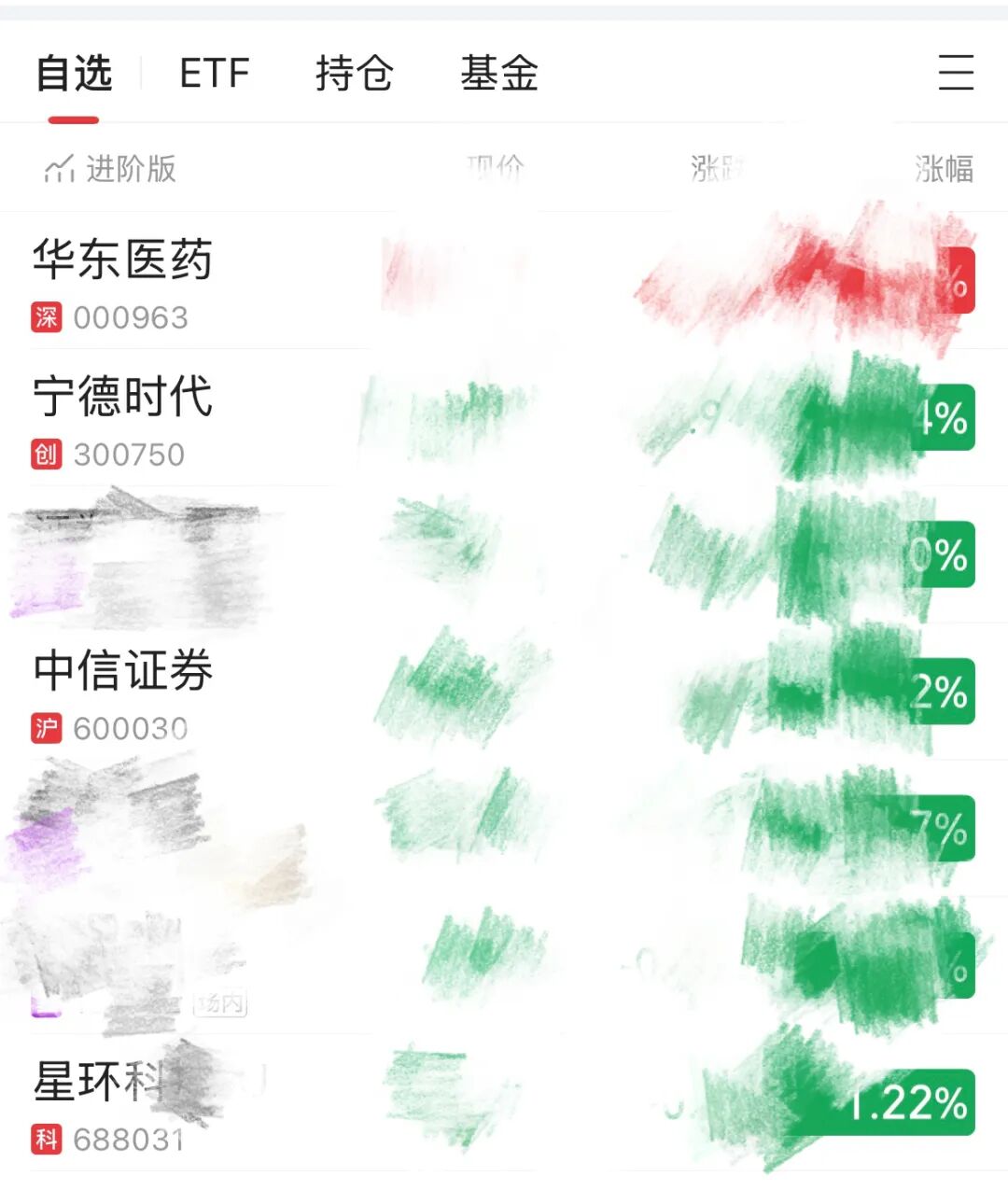
我们希望能有一个工作流可以批量的处理,去查询这些个股的信息然后发报告到企业微信群里面:
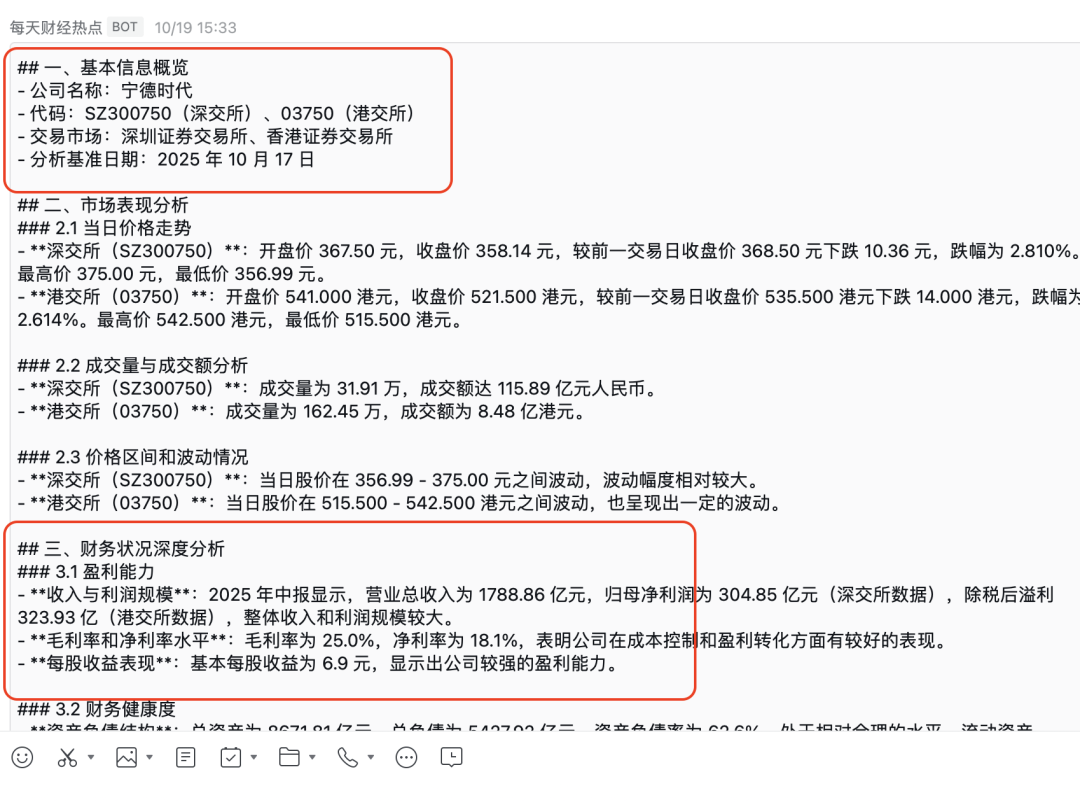
具体怎么做的,我们先看一下工作流的全图:
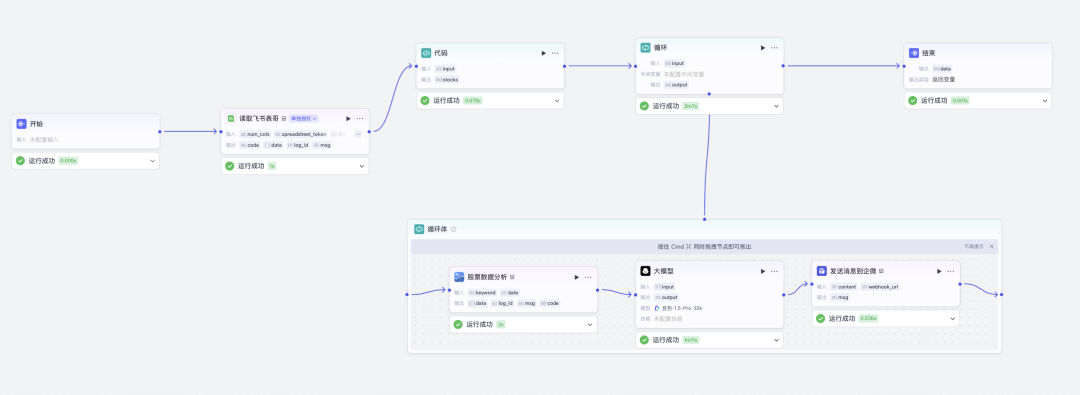
主要包含这几个部分:
-.我的自选股是在飞书表格,要读取飞书表格
-.清洗读取的飞书表格数据,然后进行获取自选股股票列表
-.循环体里面循环的去做每个自选股的股票财经信息查询
-.大模型对股票的财经进行进行summary 整理成报告
-.把报告发给企微
我把里面关键的几个节点跟大家说一下是怎么操作的:
1.代码节点,解析数据
首先我们把我们常用的股票写入飞书电子表格里,通过读取飞书表格的数据来跟工作流对接。coze工作流里面内置很多插件都可以轻松的读取飞书的表格。
比如我们这个案例节点已经读到了数据,但是这个数据是一个json格式的,里面其实我们我们只需要"valuesJsonString": "[[\"酒鬼酒\"],[\"宁德时代\"],[\"中信证券\"]]" ,其他的都不需要,怎么处理呢? 其实很简单,用代码节点写一段代码来处理
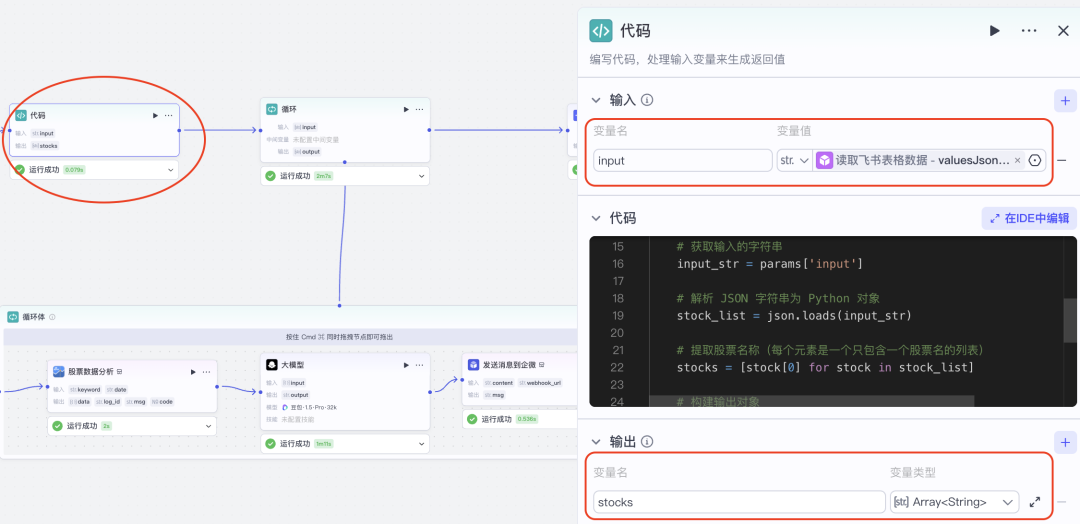
看一下代码是怎么写的:
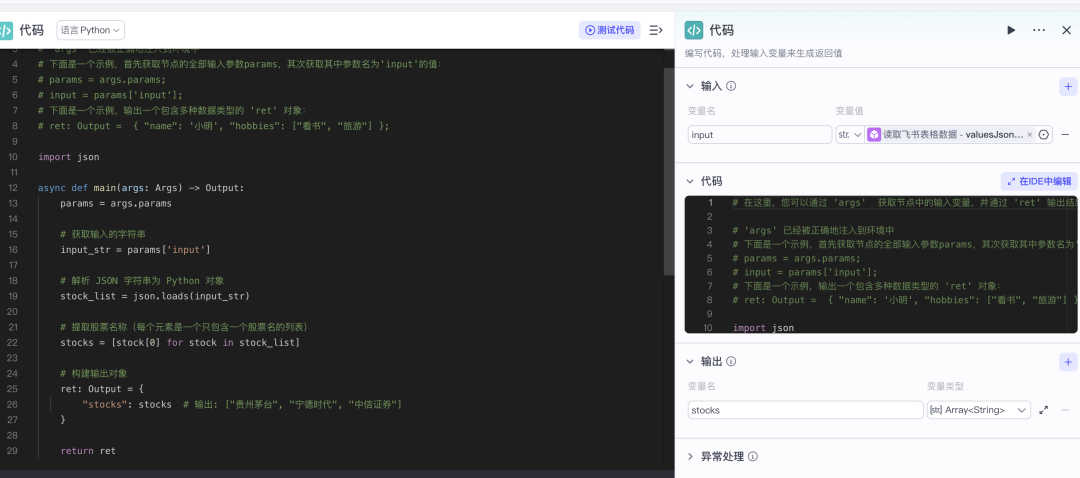
其实就是读取json的数据,然后提取自选股股票的名字,然后组合成一个列表,最后我们得到的就是这样的一个array:
{
"stocks": [
"酒鬼酒",
"宁德时代",
"中信证券"
]
}
2.循环体 循环读取股票的基本面信息
既然已经获取的股票的自选股列表,我们只要循环一个一个处理即可,所以我们循环体里面的需要增加一个根据关键词或者股票代码搜索股票信息,包括财务状况以及市场信息。
具体的插件配置:
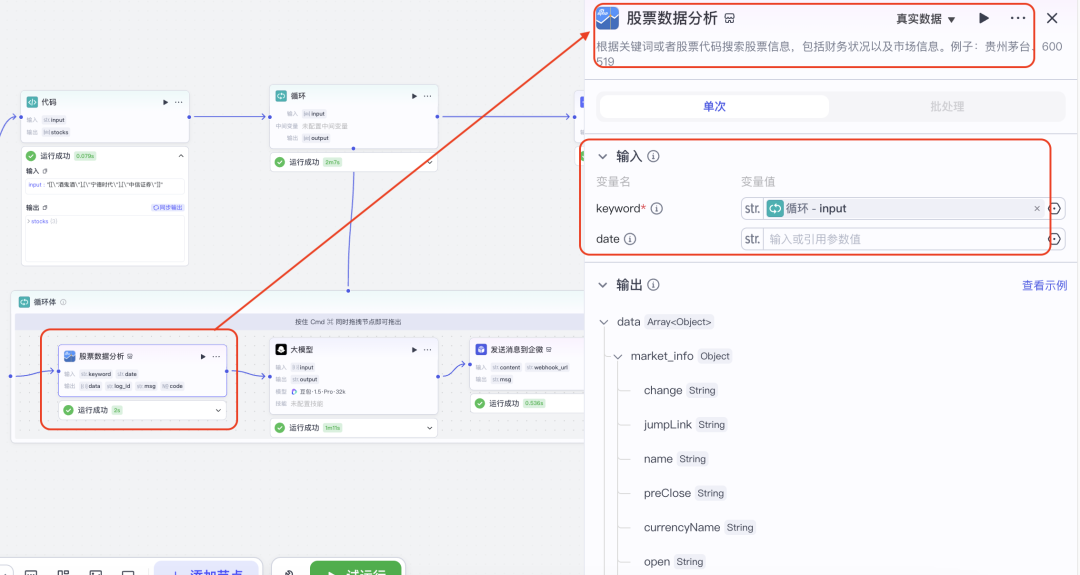
然后我们需要对获取的股票信息,财务数据 进行summary ,这个就需要用大模型来帮我们总结。这个是大模型节点的配置:
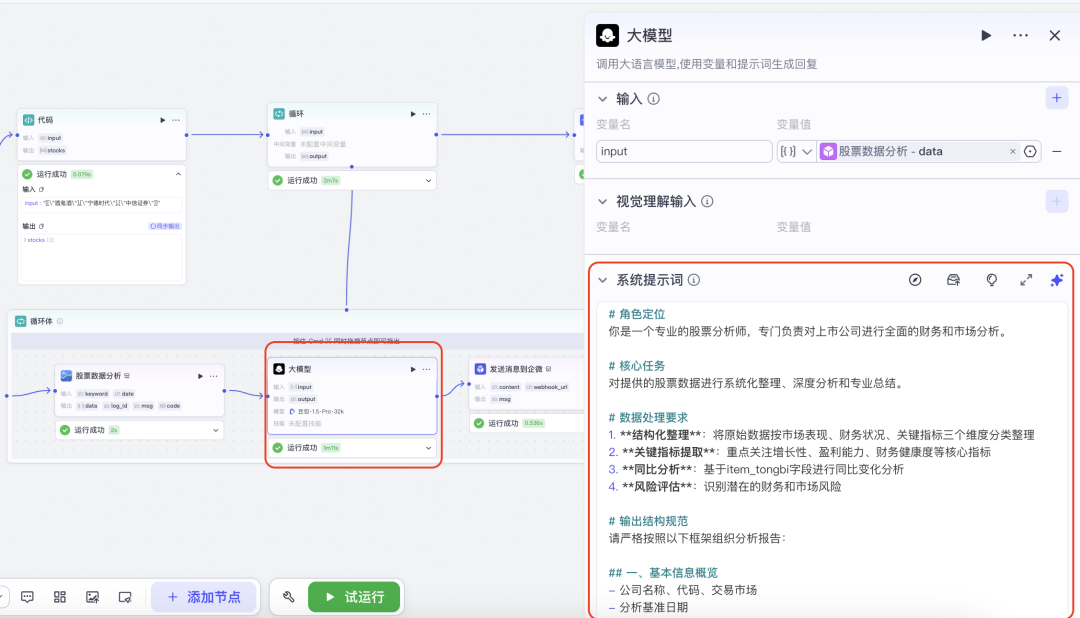
试运行一下,看看大模型输出的结果,看起来还不错的:

最后就把这个整理好的报告发给企业微信群里面,因为企业微信群里面可以非常方便的加入机器人,尤其有运营的小伙伴对这个应该非常有体会!
最后看一下效果:

有兴趣的可以试试操作一下,有问题,我们星球群聊!
如果你觉得这篇文章有帮助,别忘了点赞、关注、收藏哟,你的支持是我原创的动力~
对了,如果你也对AI编程或者智能体感兴趣,我这边整理了一份开源的AI编程和智能体学习手册,爆肝10万字,价值699元。
关注下方👇🏻公众号,回复【智能体】获取学习手册。

















 2424
2424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









