



当数据如星辰般浩瀚,当需求如浪潮般奔涌,人类对智能的探索从未停歇。一个划时代的AI引擎破茧而生——**DeepSeek**
据中国基金报报道,某招聘平台显示,杭州深度求索人工智能(AI)基础技术研究有限公司(即DeepSeek),发布了多个岗位的招聘信息。
在DeepSeek挂出的职位中,大部分岗位的起薪在3万元以上,其中年薪最高可达154万元。猎聘网数据显示,掌握深度强化学习、多模态融合等DeepSeek核心技术人才,薪资涨幅同比超120%。
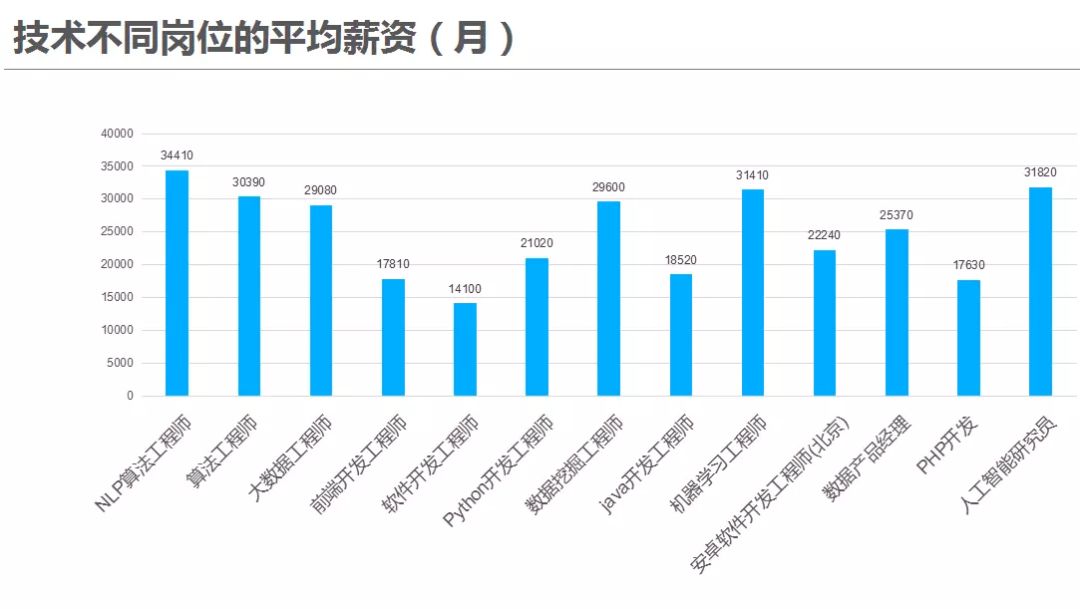
它不仅是技术的颠覆者,更是一场席卷全球的“高薪革命”与“职业机遇风暴”,技术人纷纷想转行、跳槽到前景光明又高薪的算法岗位。(深度学习/算法工程师的薪资在各个技术岗位中显然是最高的,更多技术岗位平均薪资详请见下图)
其他企业为留住和吸引人才,也都相应提高薪资待遇,有的岗位薪资甚至比往年提高70%!字节跳动73.5万年薪聘用应届生,阿里达摩院开出超过200万年薪。
2025年将是AI人才分水岭——要么成为DeepSeek技术红利的收割者,要么被时代无情淘汰!
高薪,是AI领域缺人的事实依据,但是找不到工作的大有人在,也是事实。
问题就在,申请算法岗的人很多,但实际能够胜任的很少。求职者所具备的能力根本无法匹配一线企业核心AI岗位的需求。

为帮助大家解决以上问题,真正成长为具备面试国内一线算法岗位的能力要求的算法人才。
联合现象级AI名企和大厂,共同打造了全行业第一个【深度算法培养计划训练】,并且邀请了前字节、百度算法等一线大厂在职专家为大家提供算法最前沿强化训练。
我们敢对你做出承诺:加入课程,拿不到Offer全额退款,年薪不满25W全额退款。
扫码添加课程顾问
备注:课程咨询

距离上岸,也许只差这一次助攻


课程核心内容


为了学生能够学习到真正在企业拿来即用的技术,讲师全部都是企业一线在职的实战派,有技术管理经验,负责过企业大型核心项目。
课程从算法角度出发,对各个模型进行全面细致的讲解,并结合15大企业级项目,带你熟悉算法工程师在工作中会接触到的数据打包、网络训练、测试等问题,一步步带大家了解和完成真真正正会在企业里面用到的实战案例,尽快进入AI学习领域。
NLP大模型实战项目
项目一:文本分类汽车质量投诉分类
项目二:文本分类用户评论分类
项目三:文本生成英中短句翻译
项目四:文本生成新闻摘要生成
项目五:知识图谱相关任务
项目六:序列标注相关任务
项目七:工业推荐系统
项目八:语言模型相关任务(最新)
项目九:文本生成nano-gpt模型(最新)
项目十:大模型智能图书借阅系统(最新)
项目十一:大模型PEFT微调(最新)
CV实战项目
项目一:图片分类
项目二:人脸对齐
项目三:人脸属性分析
项目四:人脸检测
项目五:行人属性检测
项目六:行人车俩检测
项目七:图融合优化及网络轻量化(边缘端设备)实现
项目八:深度学习神经网络写藏头诗
项目九:医疗影像(CT)分割
项目十:人体运动姿态跟踪与识别
项目十一:AIGC以文生图(最新)
以上项目是一套通用的解决方案,可以从中整理出面向不同业务的相似实现,适合大型互联网、自动驾驶、工业缺陷检测、智能问答、推荐系统、医疗、农业等等不同的应用场景,在整个授课过程中,老师更加注重是业务与思想的传播,让你轻松应对工作中的问题并且有举一反三的能力。
由于知识点涵盖内容较多,就不在这里赘述,如果想进一步了解,定制属于自己的提升计划。
扫码添加课程顾问
备注:课程咨询

1v1定制学习计划
往期效果


本培养计划上一期的学员就业情况部分展示,目前80%同学已经拿到AI、算法相关Offer,有应届生,也有其他领域的转型人员,统计已就业同学平均薪资超过30万。
往期部分同学现状:为保护学员个人隐私,隐去学员姓名,头像。
如果想了解更多就业信息可以扫码添加课程顾问获取详情。
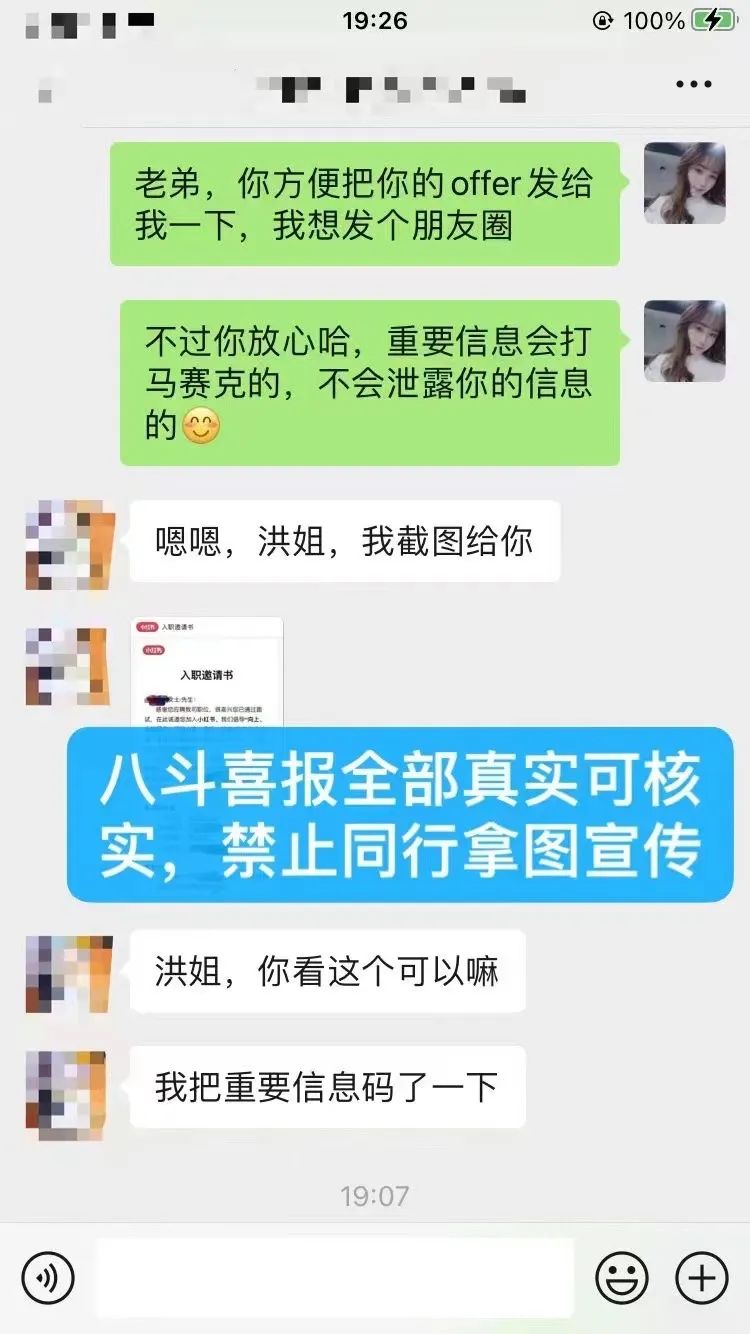
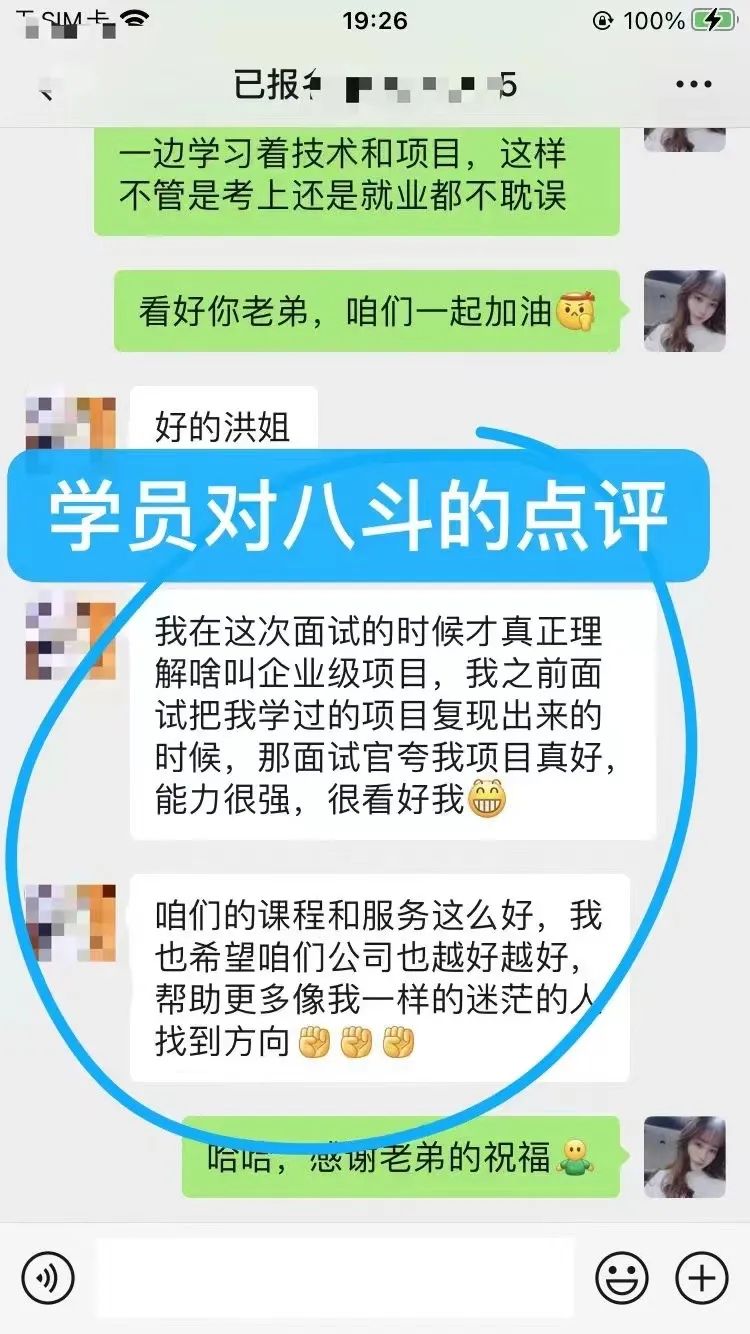
1、2024年6月继续接喜报啦,又一位学员转型成功进入小红书做算法工程师。这位童鞋也是通过朋友推荐加我微信的,当时他被裁员2个月了没找到工作索性选择了自我提升,慢下来沉淀自己反而收获出奇的大。现在进入AI领域啦,涨薪翻倍,信心十足。
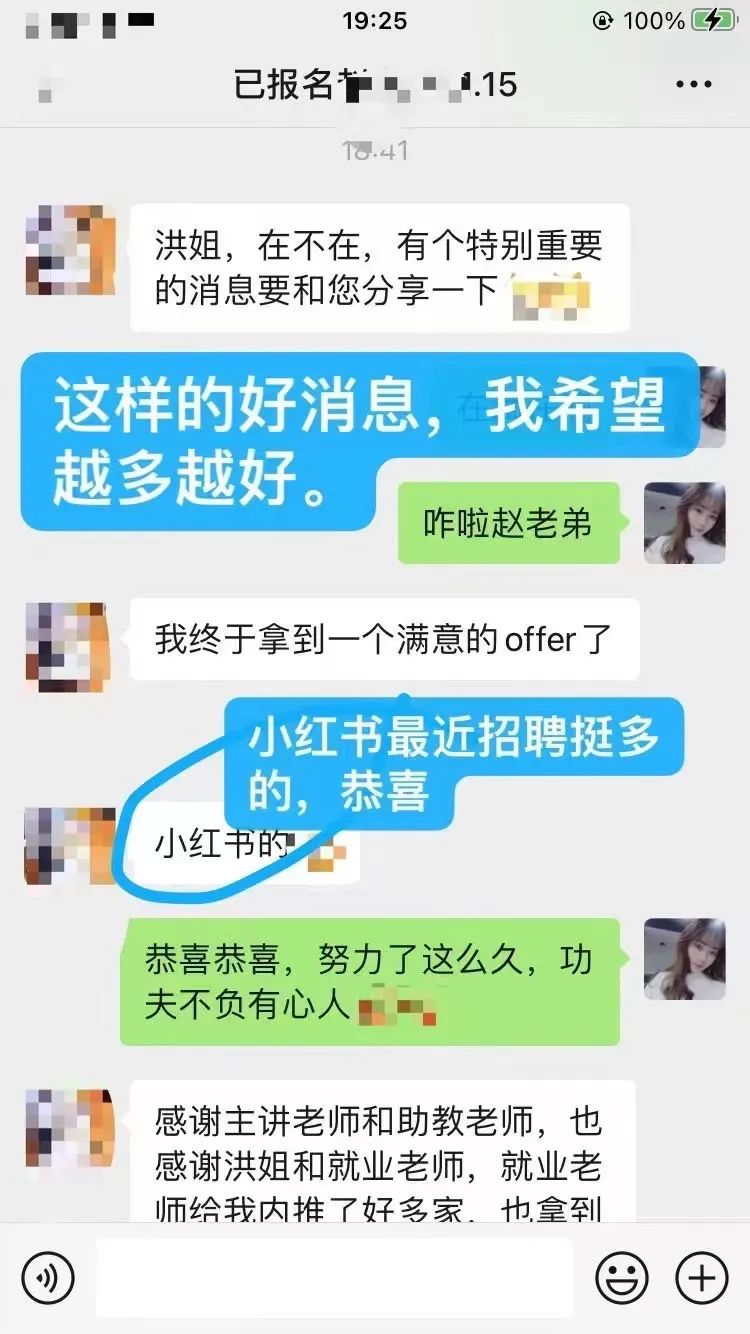
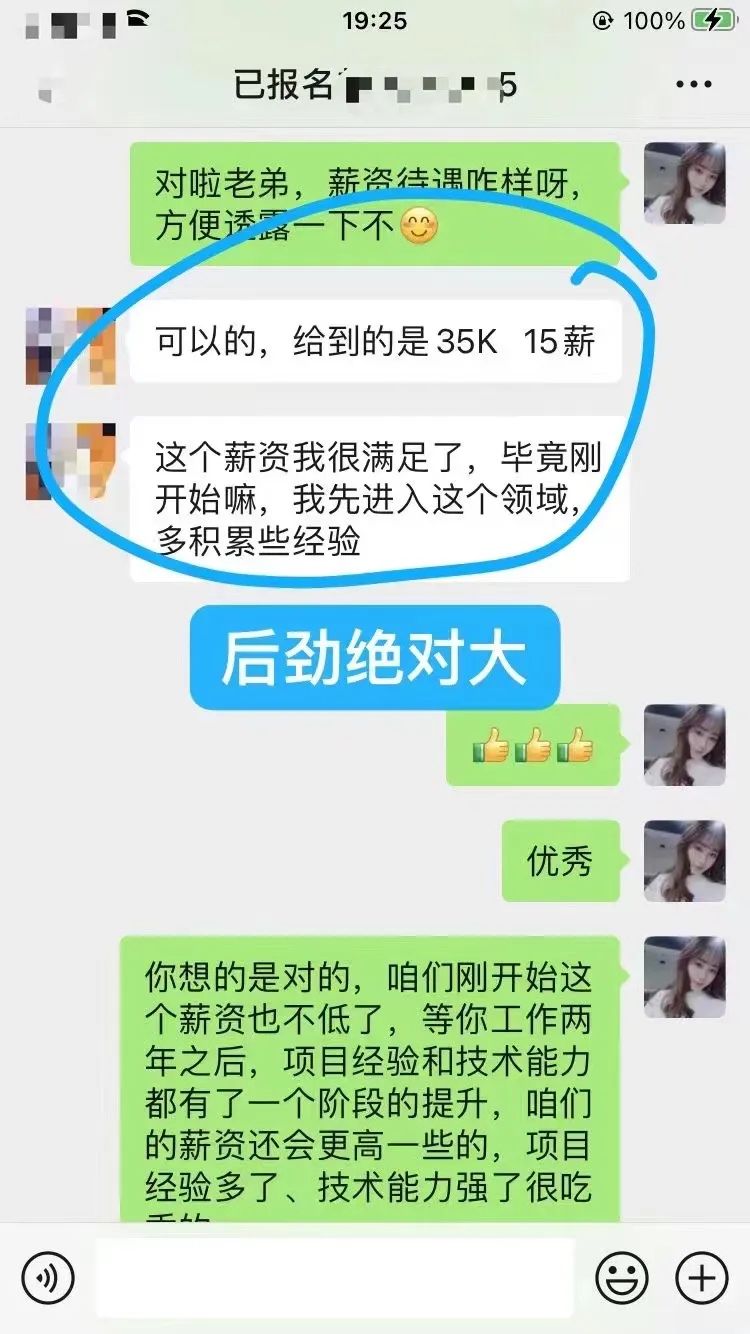
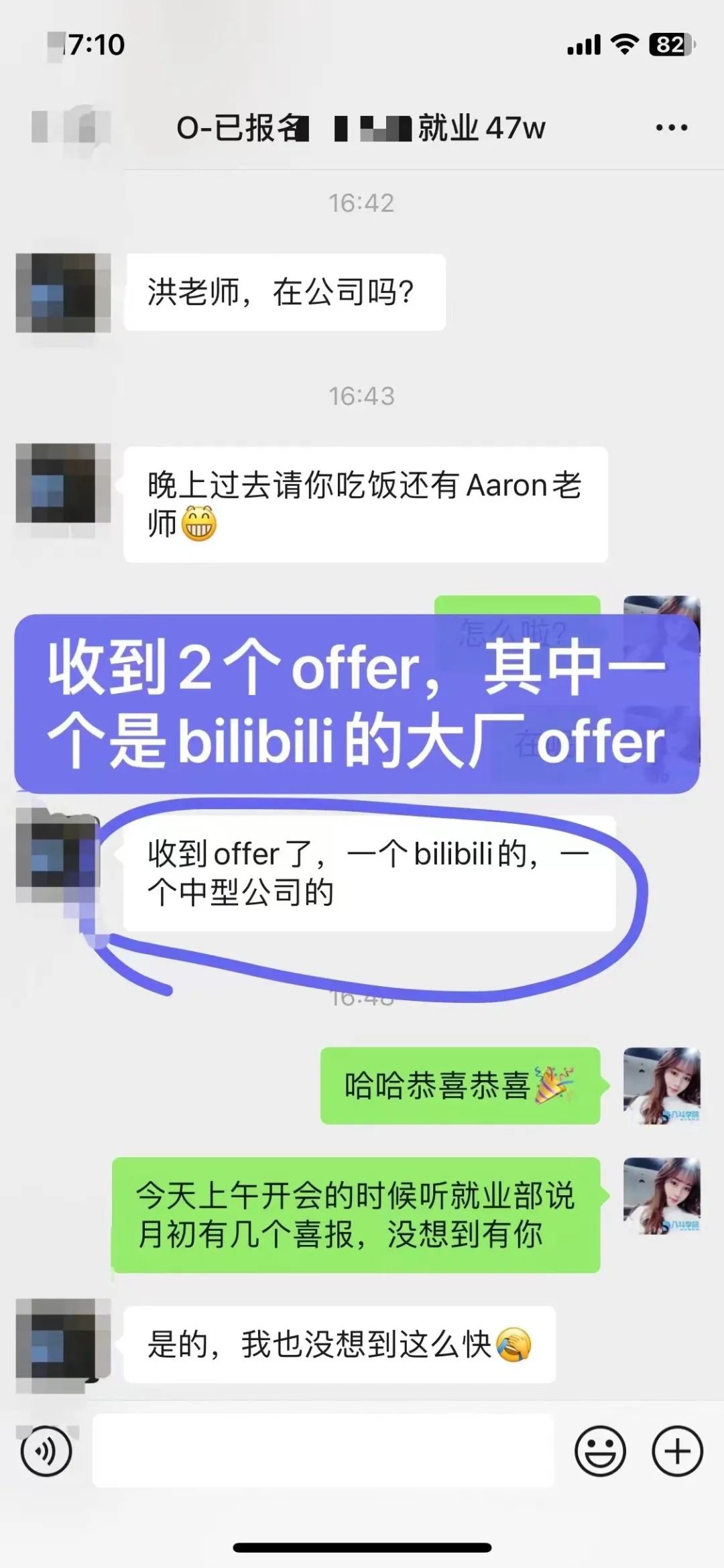
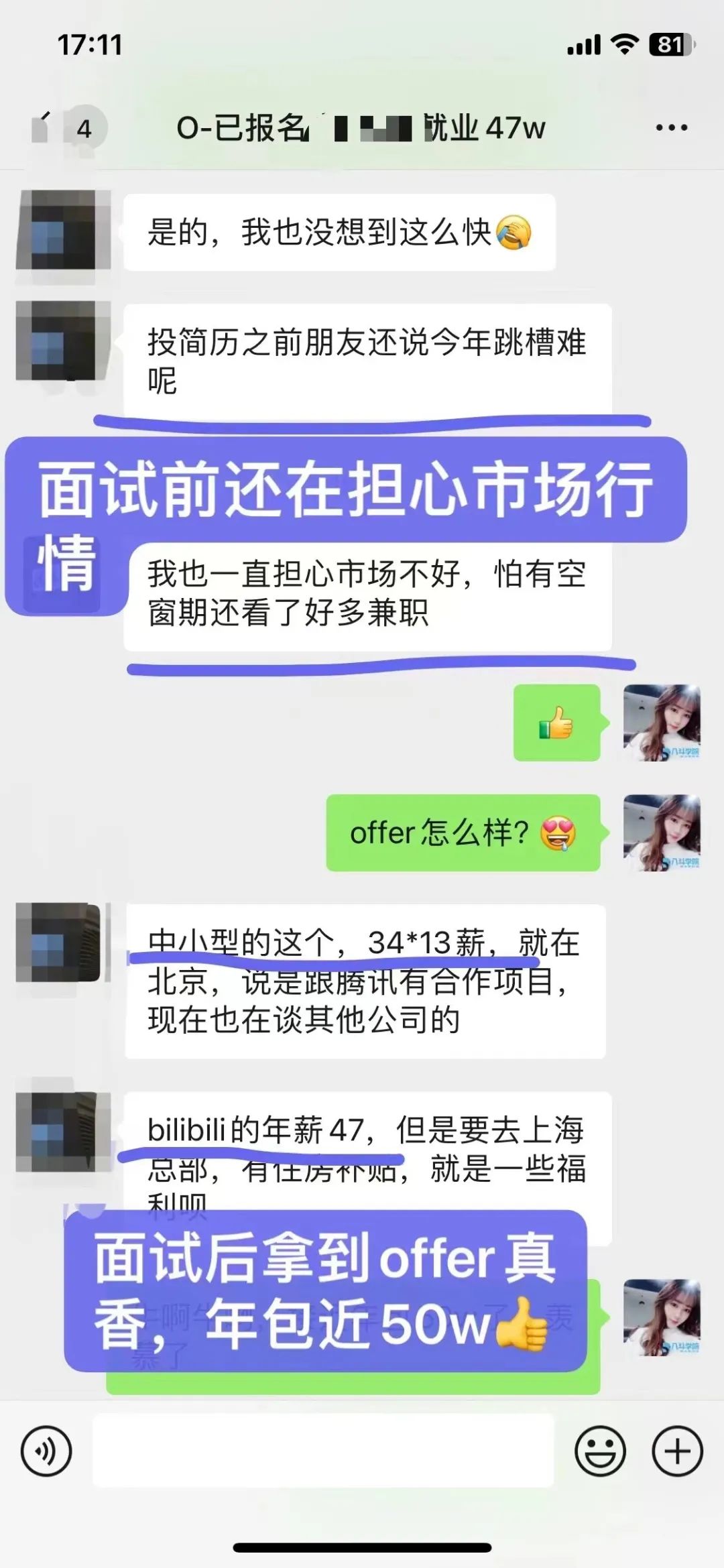
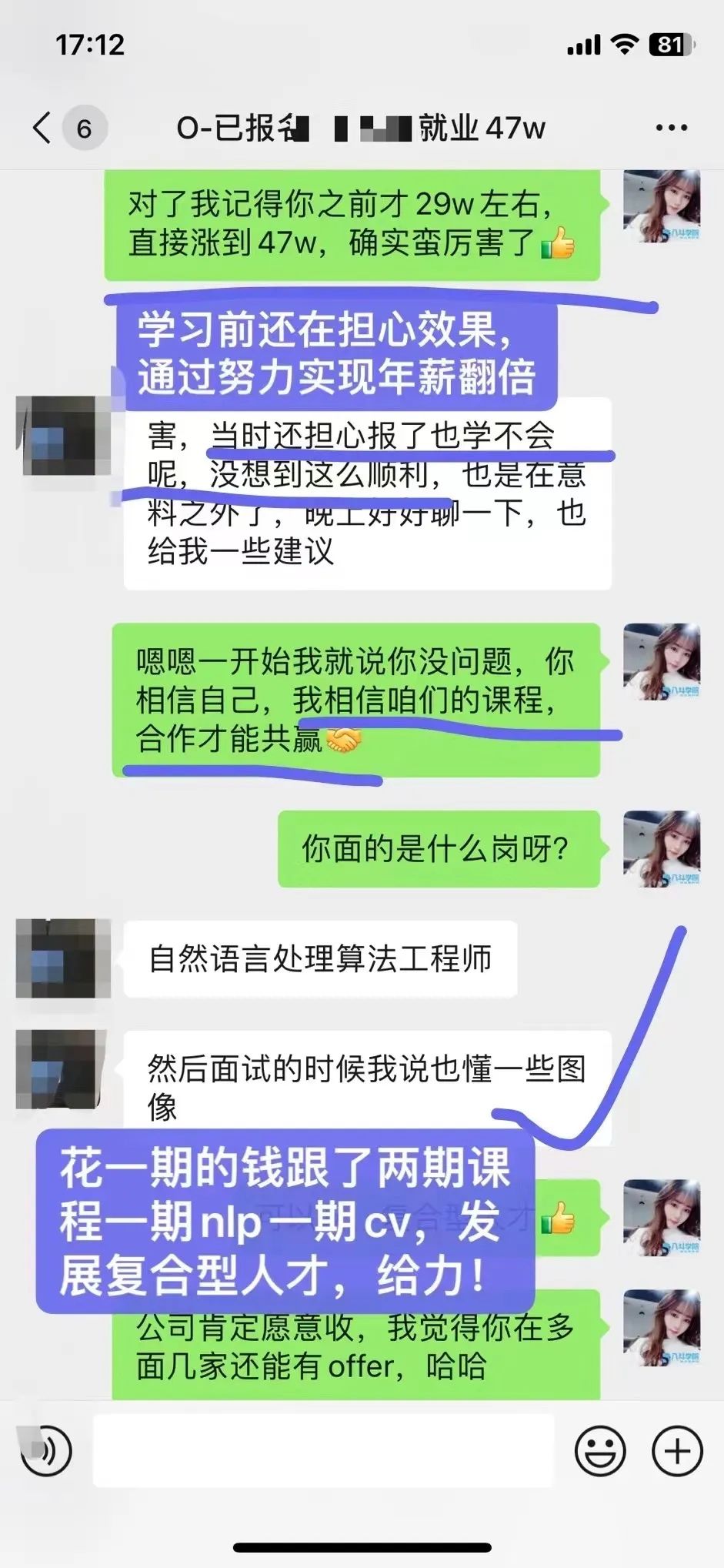
2、咨询我的时候也很担心自己非科班,没有相关工作经验,怕转型失败,好在最后做出了正确的决定,加入课程学习。课程学完刚好赶上金3银4转型旺季,一次性斩获多个大厂offer,bilibili直接开出47w年薪。
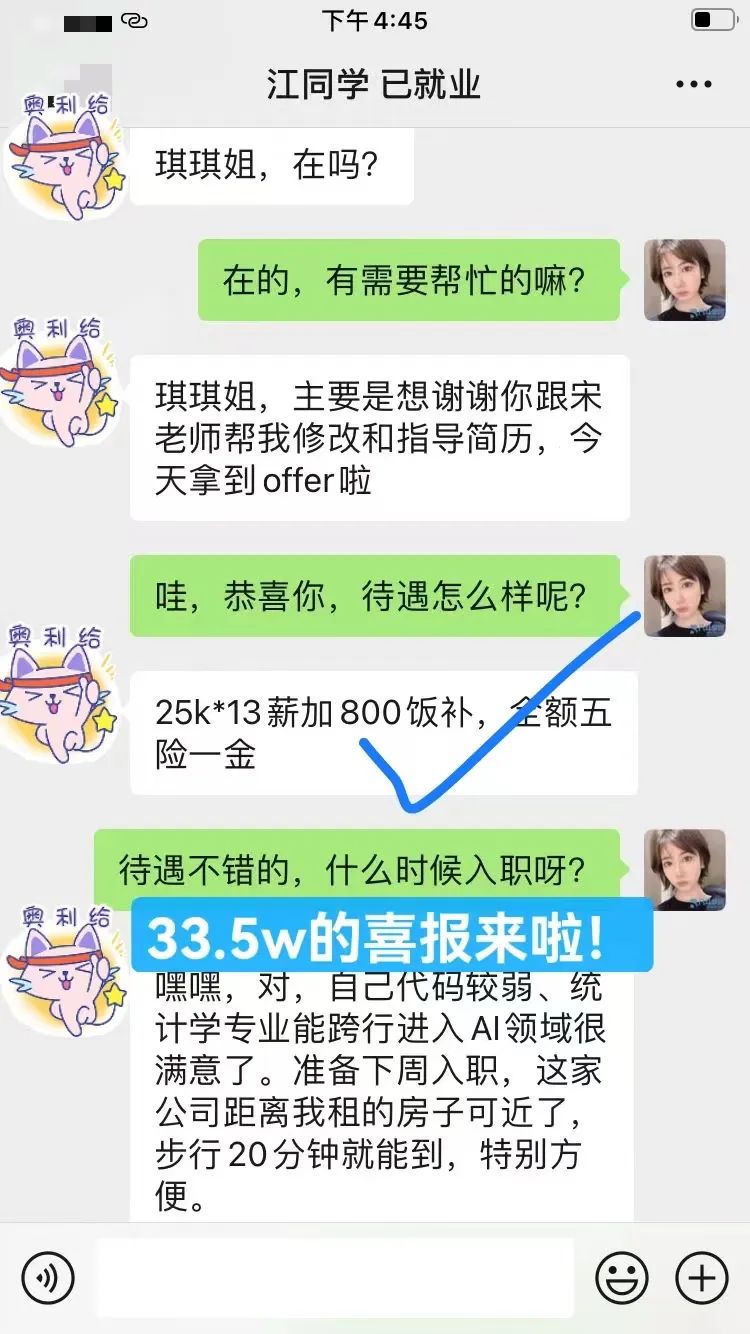
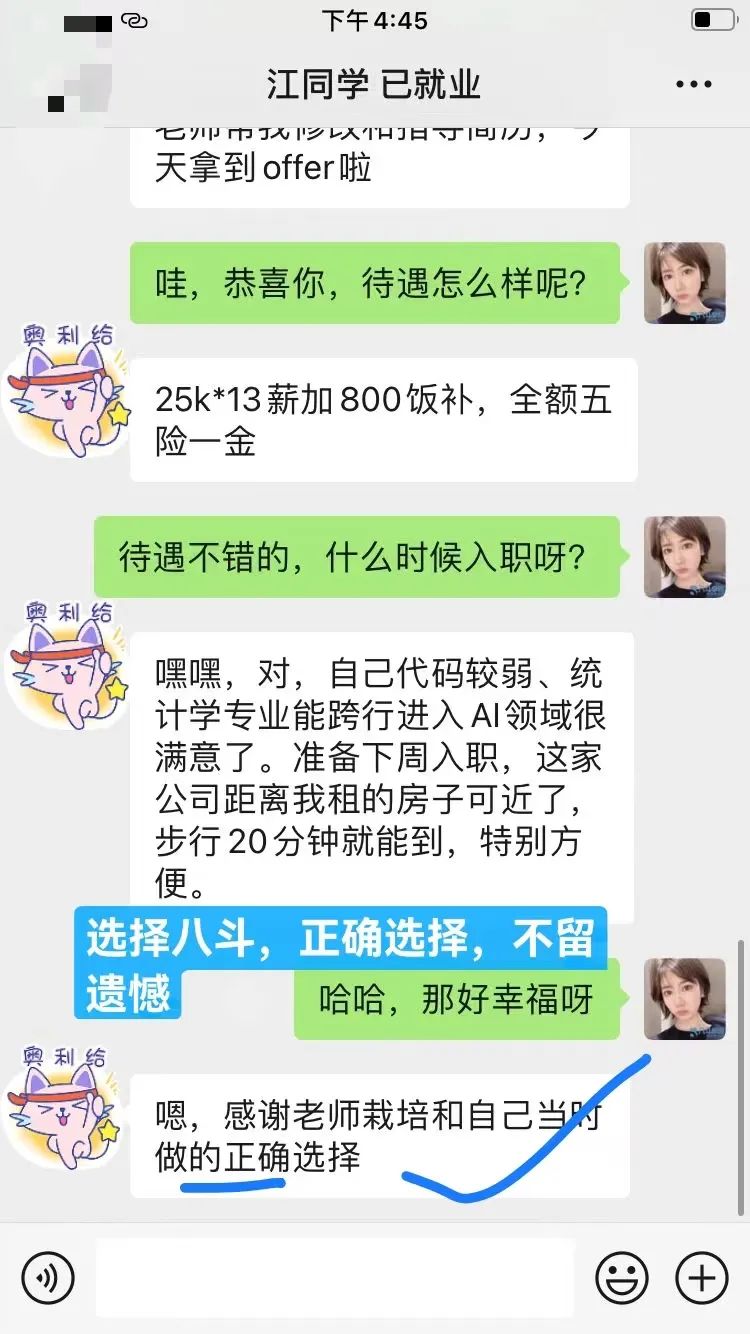
3、统计学专业毕业,看好AI趋势,但是计算机基础和代码能力较弱,考虑跟班系统提升。经同学介绍果断报名八斗跟着宋老师学习,经过4个多月的努力,第一份工作就拿到33.5w的年薪,成功入行!
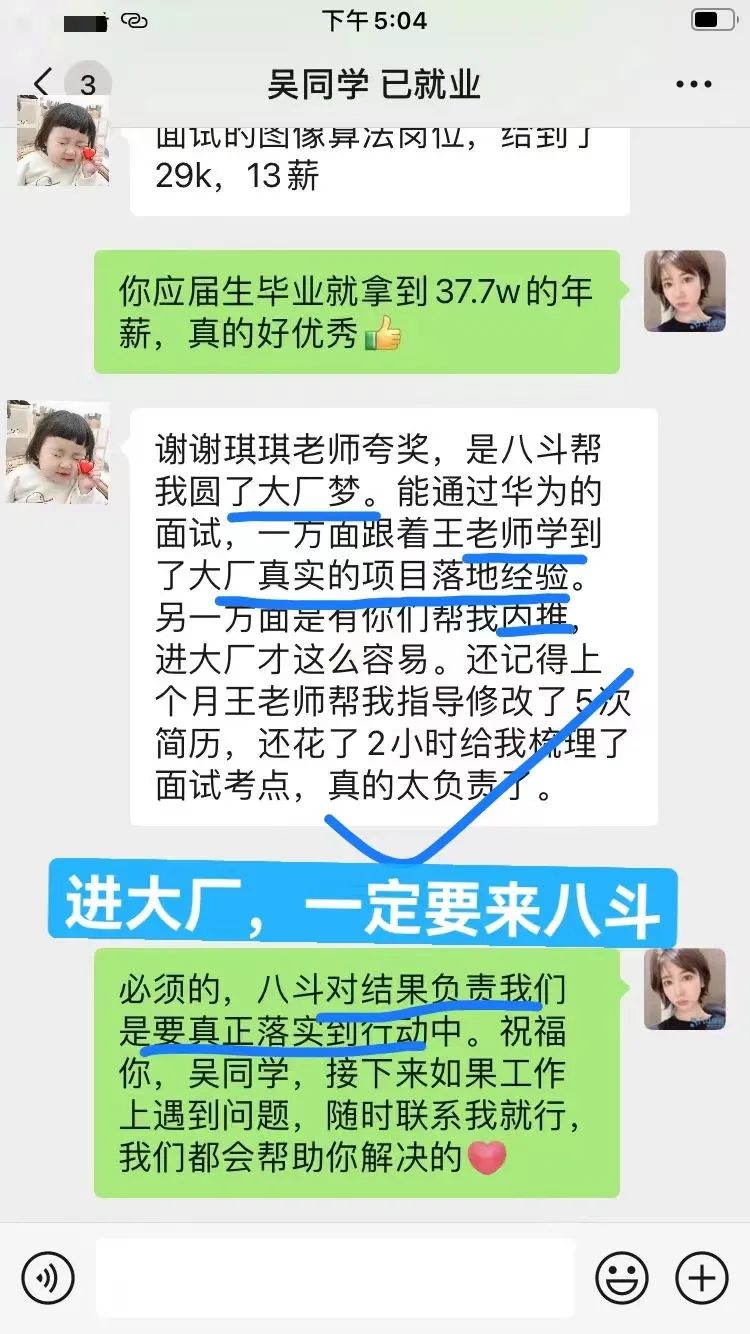
4、应届生吴,通过4个月的学习顺利进入西安华为公司,年薪高达37.7w。八斗对结果负责是落实在行动中的,高质量课程+合作内推,真正能帮大家圆大厂梦。

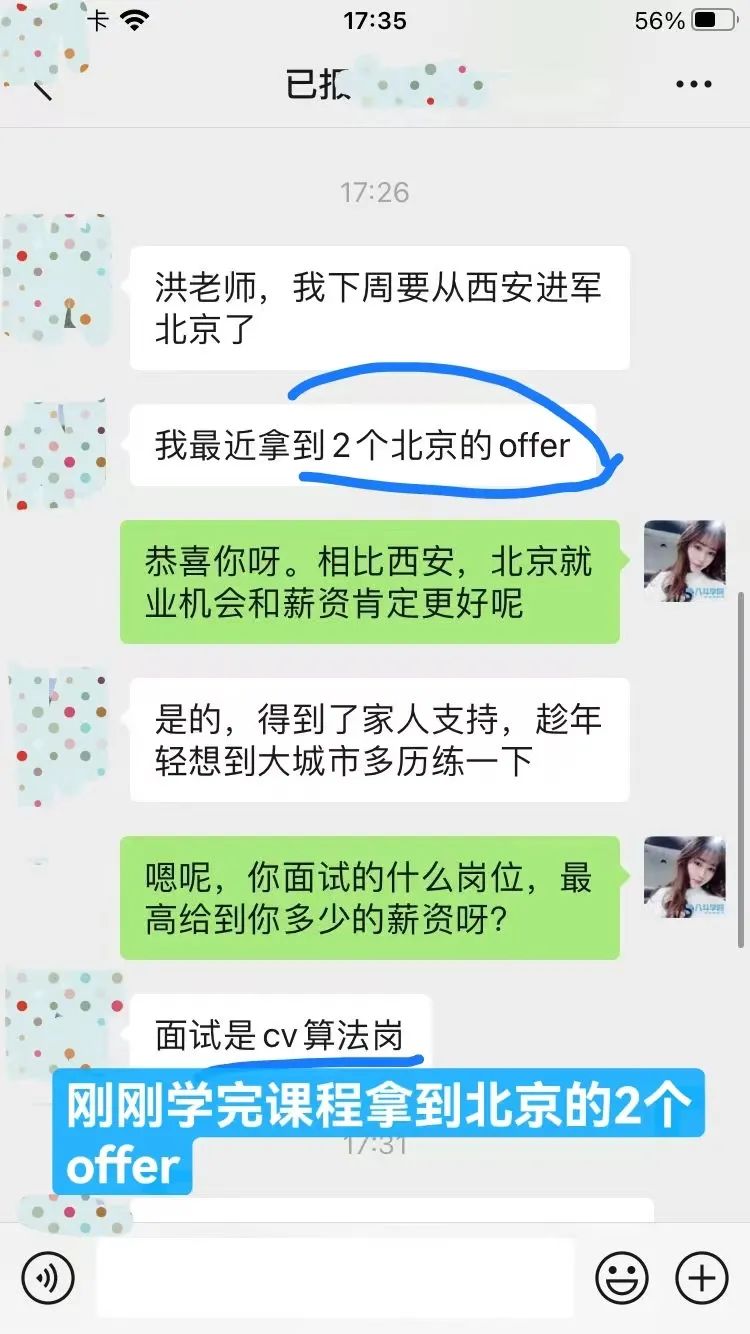
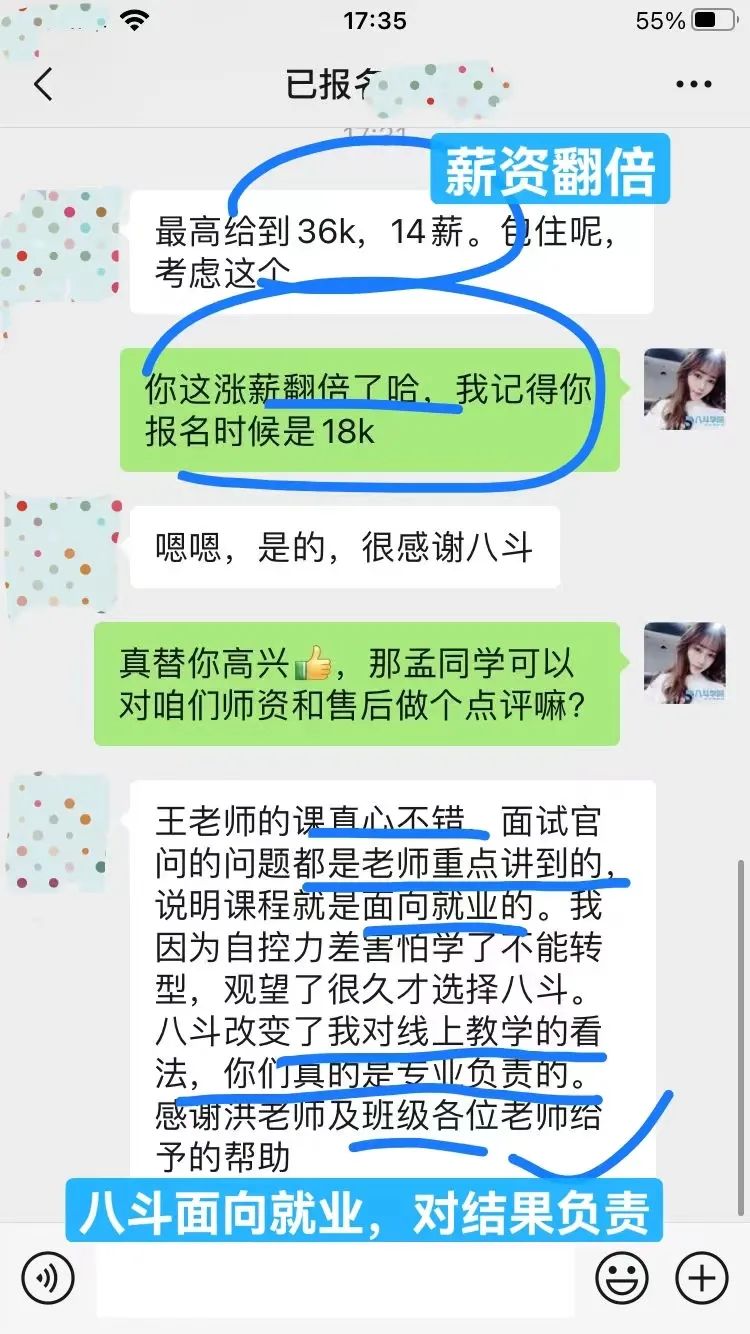
5、孟仅仅用4个月时间,从java开发成功转型CV算法并且实现薪资翻倍。
他在报名前观望考察八斗半年之久,其中最主要的原因是:担心线上学习效果差,但是八斗的学习经历让孟同学彻底改变了这种看法。
八斗线上学习跟线下对比胜在:师资,都是在职大牛授课,项目真正来源于企业实际应用,才能做到所学皆所用,保障就业。
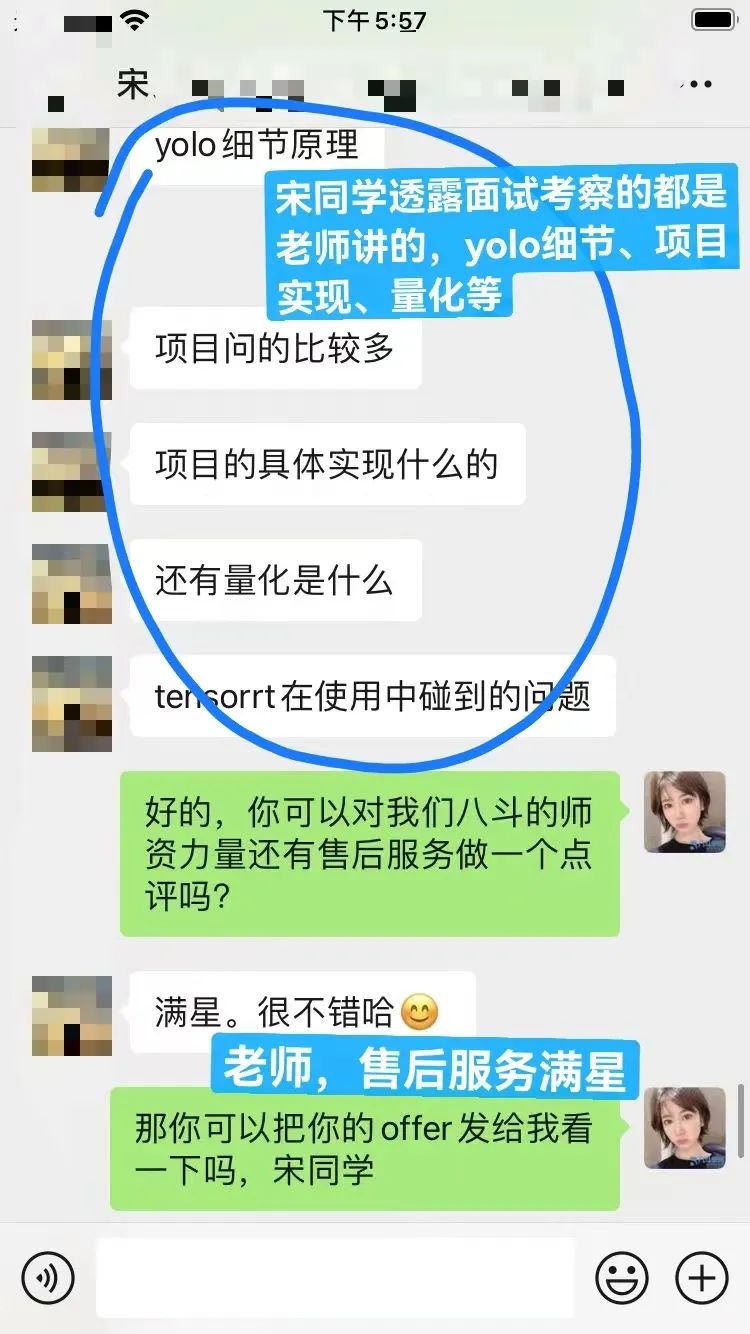
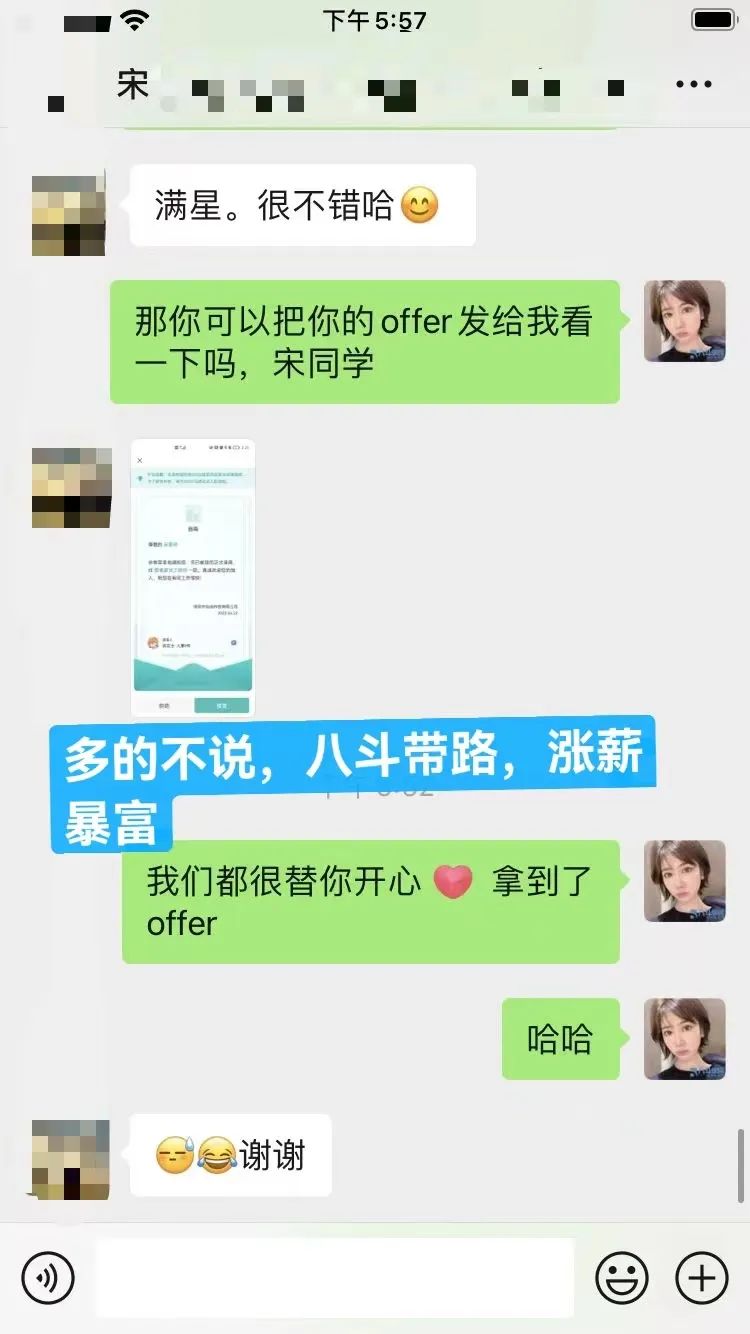
6、课程刚刚结束,宋同学还没来得及准备,去试水参加了一个面试机会就喜获offer,23k,相比自己上一份工作涨薪8k。


分期付款与就业保障


本课程可以为同学提供 3、6、12 期分期付款
报名本就业班的学员,即签订协议,课程结束后若拿不到offer或者就业初始达不到税前年薪25万以上,则全部退还学费。(保薪承诺不限于25w,根据学员情况可调整保薪力度)理论上无限!以与售前老师沟通为准!
扫码添加课程顾问
备注:课程咨询

锁定分期付款名额


















 938
938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









