




论文链接:Visual Prompt Multi-Modal Tracking
开源代码:Official implementation of ViPT
简介
这篇文章说了个什么事情呢,来咱们先看简单的介绍图
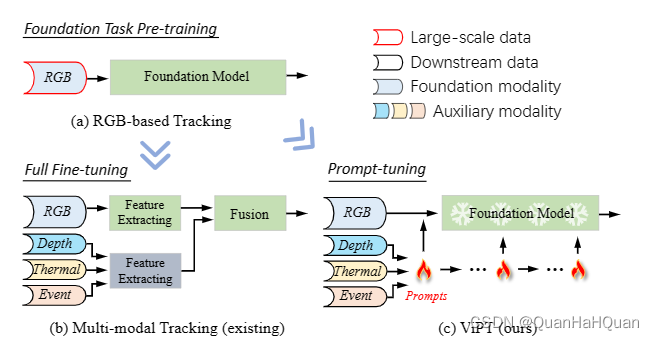
简单来说,这篇文章主要干了这么一个事情:
以前的多模态呢,都是直接提取特征然后拼接到一起。这个文章不一样,我把所有的模态分开主次,其中只有一个主要模态,剩下的都是附加的。这些附加的模态可就不要再提取特征了,而是通过他们来提取prompt出来。并且使用这些prompt来帮助我的模型更好的在主要模态上提取特征。除此之外,还有一个不一样的点就是在主要模态上提取特征的时候,backbone,这里叫fundation model的模型参数是不更新的。
OK,你已经看完这篇文章了。。当然啦,如果还想知道知道更多的技术细节,咱们接着往下看。
关于具体的思路
咱们来看第二张图,模型的详细介绍
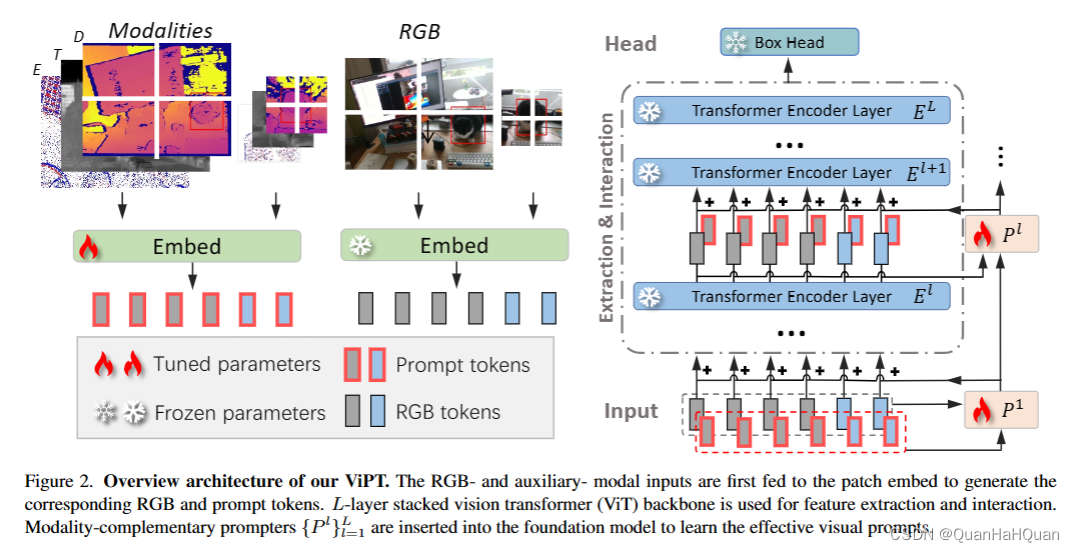
这个图其实画的很好,过程非常直观。接下来咱们只需要展开说说其中的细节就可以了
问题描述
首先,我们想要得到的是追踪器,单模态的方法中,假如说叫做 F R G B : { X R G B , B 0 } → B F_{RGB} : \{X_{RGB}, B_0\} \rightarrow B FRGB:{ XRGB,B0}→B,那么 B B B就是目标的box, B 0 B_0 B0就是这个框的初始值, X R G B X_{RGB} XRGB就是需要搜索的帧。那么接下来,在多模态的方法中,加入了一个啥呢
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1792
1792

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









