




 文章介绍了如何将大语言模型应用于多模态自然语言生成任务,通过MAnTiS方法,使用不同编码器处理文本和非文本模态,实验在FACAD数据集上展示了改进。文章详细阐述了编码映射、多模态微调和ModalityDropout技术。
文章介绍了如何将大语言模型应用于多模态自然语言生成任务,通过MAnTiS方法,使用不同编码器处理文本和非文本模态,实验在FACAD数据集上展示了改进。文章详细阐述了编码映射、多模态微调和ModalityDropout技术。
Paper速读-[Multimodal Conditionality for Natural Language Generation]-Salesforce Einstein-2021.9.2
文章目录
论文链接:Multimodal Conditionality for Natural Language Generation
1. 简介
将大语言模型这种东西应用到传统的NLG(Natural language generation)任务中是一个很好的做法,但是以前的模型基本只局限于一个单一的模态。所以在这个文章里,作者提出MAnTiS(Multimodal Adaptation for Text Synthesis)。做法简单来说就是分别对不同的模态使用不同的编码器,其中文本使用词嵌入。之后将其他模态的特征映射到文本空间中,并且将这些其他模态的特征联合起来表示为一个指导生成的前缀。
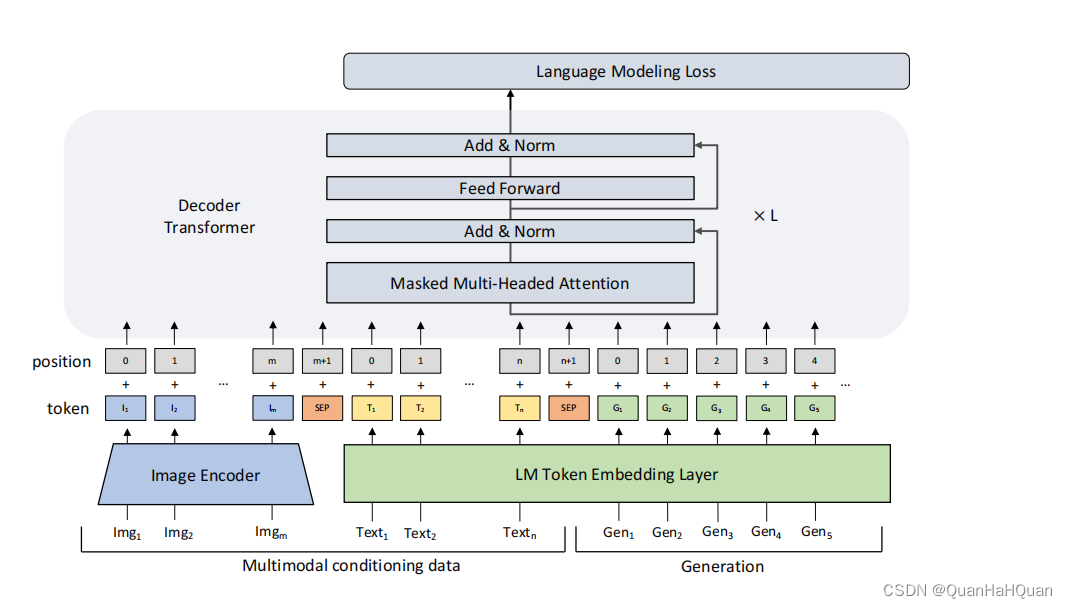
简单来说,这篇文章主要干了这么一个事情:
- 把大语言模型用于自然语言生成这个事情拓展到多模态中来
- 数据集是商品描述数据集,也就是<商品名,图片>-> <描述>,实验验证了模型在这个数据集上表现比以往直接将多个模态的特征直接送入的做法要好

2. 关于具体的思路
原本的生成过程是这样的

现在呢,因为有了其它模态的信息,这个过程就变成了这样
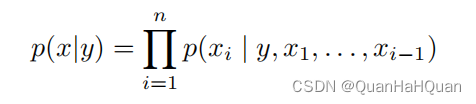
简单来说就是,这个y就是其它模态的信息,类似于引入了一个补充的条件。
2.1 其它细节
2.1.1 编码映射
对于视觉模态,使用预训练过的ResNet-152将每个图片抽取出N维特征,之后使用一个线性层 W ∈ R N × D W \in R^{N \times D} W∈RN×D将特征映射到文本的空间,其中D为语言模型的embedding维度。
对于语言模型,使用GPT-2和基于自注意力的自回归模型。编码器和解码器一起在端到端的情况下进行监督学习的微调。此外,通过这种线性层映射的方式,我们可以轻易地加入更多的更多的模态。
2.1.2 多模态微调
在原本GPT-2的基础上,对于每个模态的token之间,其对应的位置编码也是从0开始。在每个模态之间加入一个[SEP]对应的token来分割,这个token的位置编码是上一个token+1。接下来在第一个条件token前面加入[BOS]对应的token,在最后加入[EOS]对应的token。
此外,对于图片模态对应的token,不需要计算损失函数,因为这部分的信息没有对应的具体词汇,所以没有预测的交叉熵损失。
2.1.3 Modality Dropout
在微调的过程中,因为损失函数的影响,文本模态对于生成结果的影响可能会更大。在训练过程中,作者随机初始化了用于将图片信息映射到文本空间的线性层。此外,在模型训练过程中随机dropout一些不同模态的通道,这可以帮助模型学习到跨模态的表示。
3. 关于效果
3.1 数据集
使用FACAD数据集,数据集的实例如下图。其中一共有55959条描述,经过对于重复内容和缺失内容的排除后,数据集减少到45748。
3.2 训练细节
在WebText数据集上训练的GPT2,这个训练数据集约包含了八百万非维基百科的网页内容,总大小约为40GB。本文使用GPT2-Medium作为baseline的语言模型,嵌入大小为1024,包含24层,每层中有16个头的注意力,总参数量为354M。使用和HuggingFace中同样的词表,其中包含了三个额外的token,分别为BOS,SEP和PAD。使用ResNet152作为图像特征编码器。
此外,对于每一个模型的学习率设置为1e-5到5e-5之间。对于文本模态的随机丢弃概率设置为0.3到0.7,其余丢弃率都设置为0.1。使用AdamW优化器和线性方式增长学习率。
3.3 直观
咱们来看一个很直观的结果
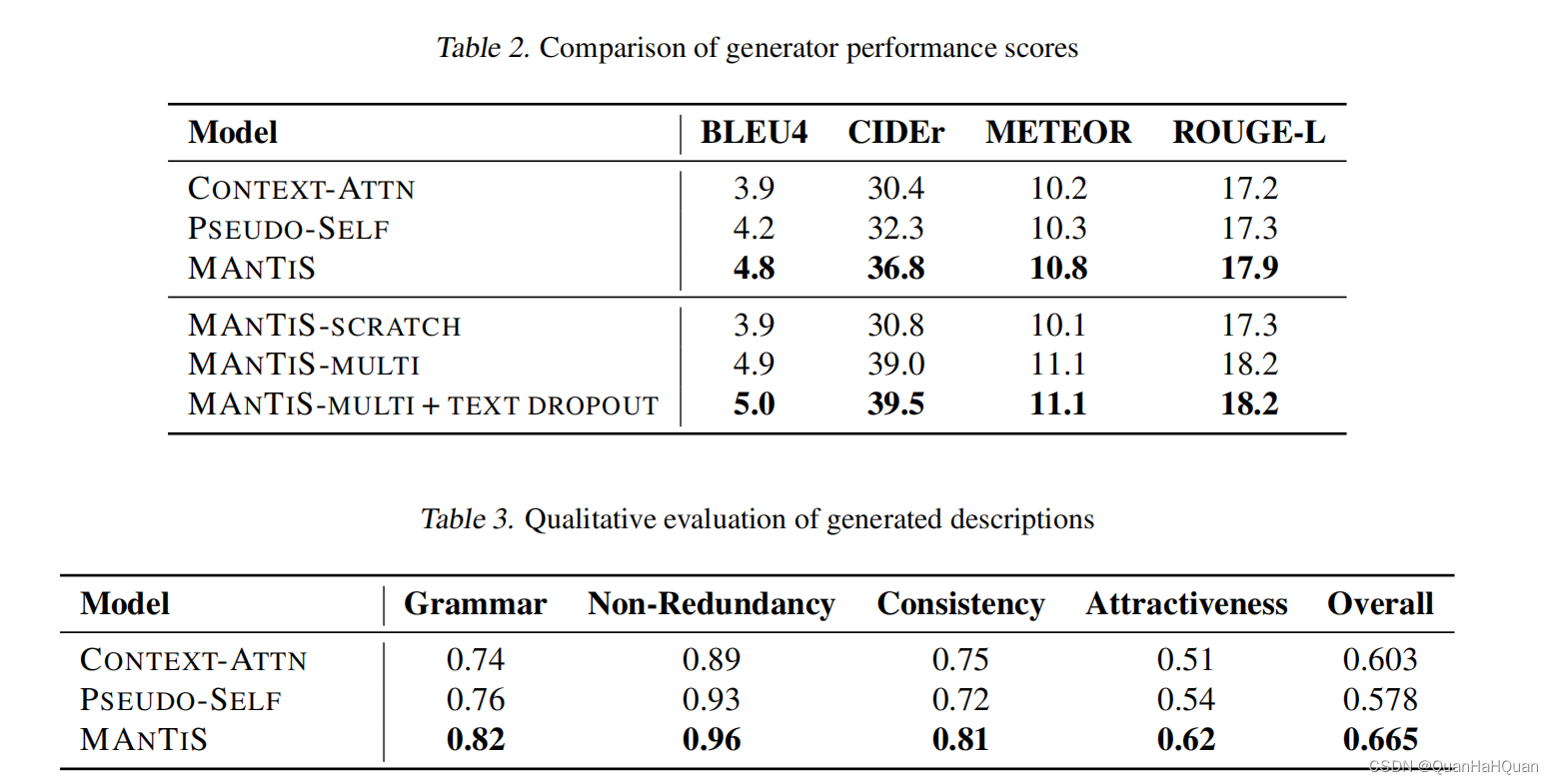
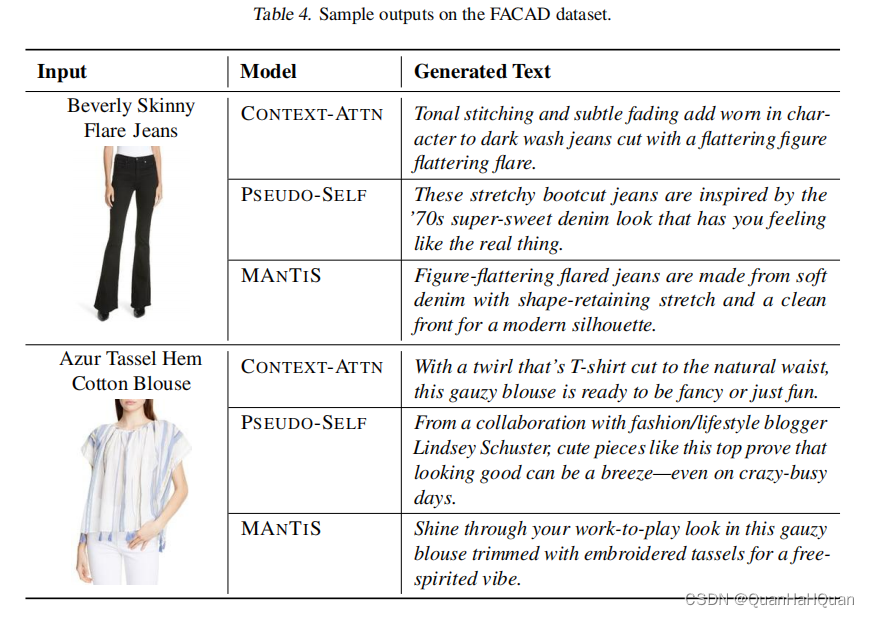
其中,表2为自动计算的指标,表3为人工评估的结果。
OK,那么以上就是本篇文章的全部内容了,感兴趣的小伙伴可以点击开头的链接阅读原文哦
关于更多的文章,请看这里哦文章分享专栏 Paper sharing Blog

















 6313
6313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









