





 超级会员免费看
超级会员免费看

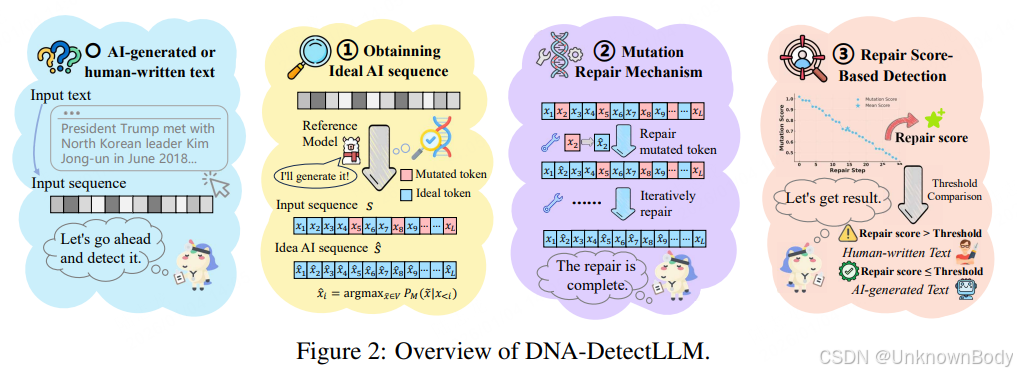
一、主要内容总结
1. 研究背景与问题
随着大型语言模型(LLMs)的快速发展,AI生成文本与人类撰写文本的界限日益模糊,引发了虚假信息传播、著作权归属模糊、知识产权纠纷等社会风险,亟需可靠的AI生成文本检测方法。然而,现有生成模型的输出质量不断提升,导致两类文本的特征分布大量重叠,传统检测方法(基于训练或无训练)因依赖固定特征边界,检测准确性和鲁棒性面临严峻挑战。
2. 核心方法:DNA-DetectLLM
受DNA复制中的突变-修复机制启发,提出一种零样本AI生成文本检测方法,核心流程包括三步:
- 构建理想AI序列:以参考语言模型为基础,通过贪心选择每个位置概率最高的token,生成“理想AI序列”(类比DNA中的模板链);
- 突变修复机制:将输入文本中非最优概率的token视为“突变token”,迭代将其修正为理想token,直至输入文本与理想AI序列完全对齐;
- 修复分数检测:引入修复分数量化修正过程的难度,通过与校准阈值对比区分文本类型——人类撰写文本因“突变”更多,修复分数更高;AI生成文本更接近理想序列,修复分数更低。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1494
1494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











