





 超级会员免费看
超级会员免费看

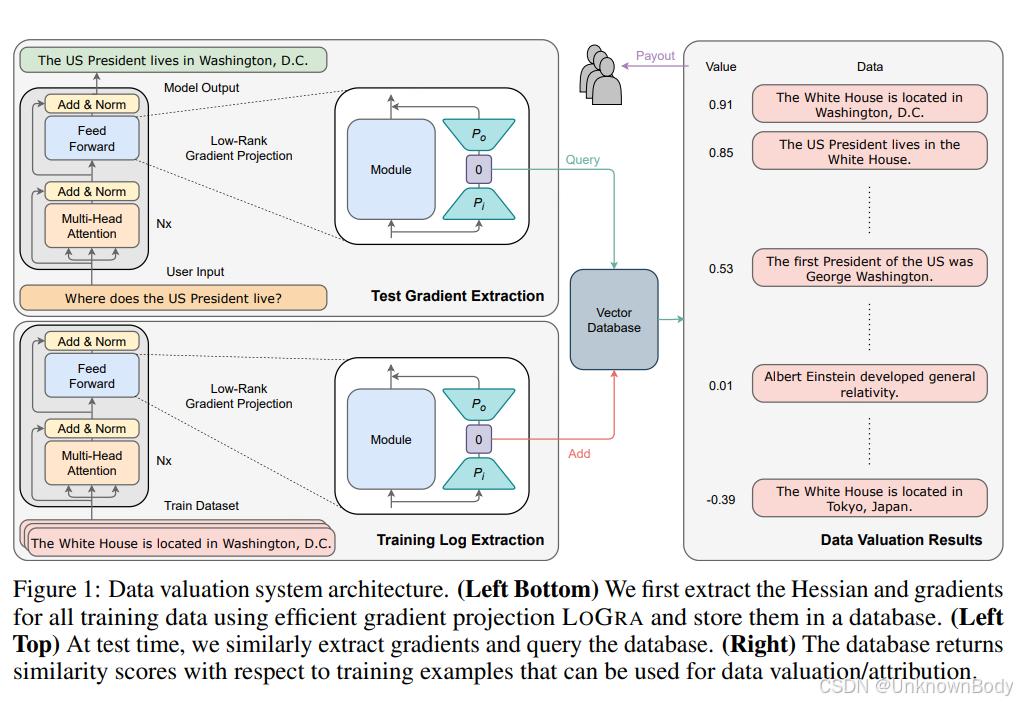
一、文章主要内容总结
本文聚焦大语言模型(LLMs)训练数据的价值评估问题,核心解决现有数据评估方法在LLM场景下计算和内存成本过高的痛点。通过改进基于梯度的影响函数(influence functions),提出低秩梯度投影算法LOGRA和开源软件LOGIX,实现了高效、可扩展的数据价值评估。实验验证了该方案在准确性与效率上的优势,可支持十亿级参数模型和万亿级token数据集的评估,为数据提供者的信用认定与补偿提供技术支撑。
二、核心创新点
- LOGRA算法:利用反向传播中的梯度结构,设计低秩梯度投影策略,将梯度投影的时空复杂度从(O(nk))降至(O(\sqrt{nk})),无需生成完整梯度即可直接计算投影梯度,大幅降低GPU内存占用并提升利用率。
- 理论支撑:将影响函数中的阻尼项解释为谱梯度稀疏化机制,为梯度投影方法提供理论依据,并推导了基于PCA的LOGRA初始化方案。
- LOGIX软件:兼容LLM生态中的主流工具(如DeepSpeed、HF Transformers),仅需少量代码修改即可将现有训练代码转化为数据评估代码,支持自定义扩展。
- 高效扩展性:在Llama3-8B-Instruct等模型上验证,相比现有基线EKFAC influ

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1037
1037

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











