





 超级会员免费看
超级会员免费看

文章总结与翻译
一、主要内容
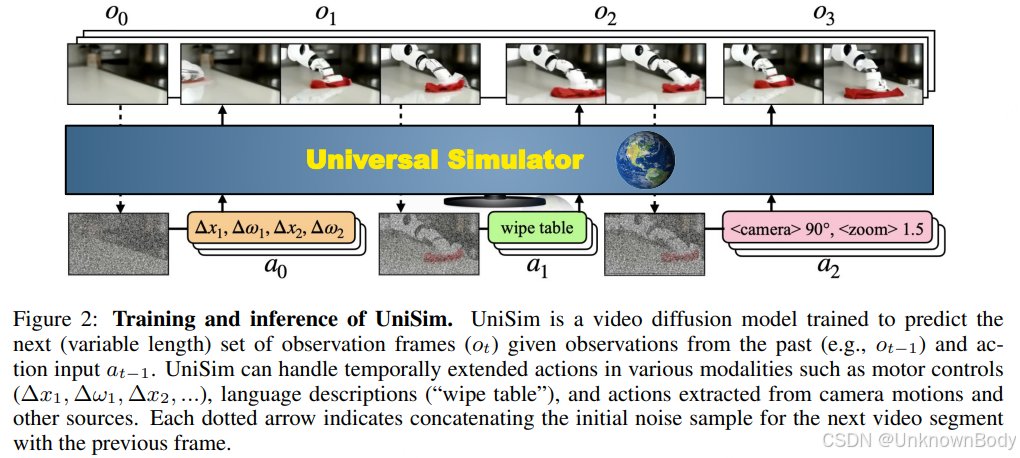
该研究发表于ICLR 2024,提出了一种通用的真实世界交互模拟器(UniSim),旨在通过生成建模实现对现实世界的交互式模拟。核心思路是整合多维度的多样化数据集(包括互联网文本图像、机器人操作数据、人类活动视频、全景扫描等),这些数据集各自涵盖不同维度的信息(如物体丰富度、动作密集度、运动多样性等),通过统一的“动作输入-视频输出”接口,实现对高层指令(如“打开抽屉”)和底层控制(如“沿Δx、Δy移动”)的视觉结果模拟。
UniSim采用视频扩散模型构建观测预测模型,支持自回归展开以实现长时程、一致性的交互模拟。研究验证了其三大核心应用:1)通过事后重标记训练长时程视觉-语言策略;2)基于模型的强化学习训练底层控制策略,且两种策略均能零样本迁移至真实机器人场景;3)为视频描述等视觉-语言任务生成训练数据,提升模型性能。此外,该模拟器还能模拟稀有或危险场景,拓展了生成模型在现实交互场景中的应用边界。
二、创新点
- 多数据集融合框架:首次将不同维度(物体、场景、动作、语言、电机控制等)的多样化数据集整合到统一的“动作-视频”生成框架中,解决了单一数据集信息片面的问题,为通用模拟器奠定数据基础。
- 长时程交互建模:将模拟器构建为基于有限历史条件的观测预测模型,

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 3442
3442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











