








 超级会员免费看
超级会员免费看

文章核心总结与翻译
主要内容
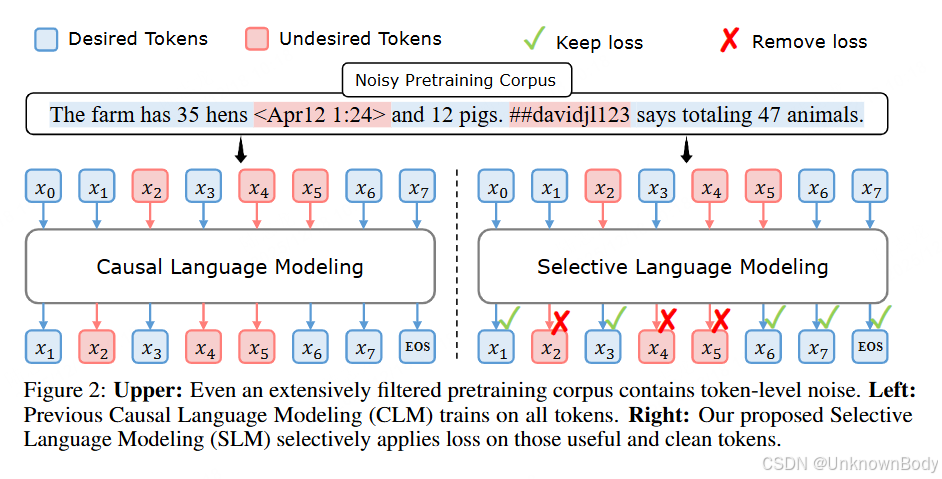
文章提出传统语言模型预训练对所有 tokens 统一应用下一个 token 预测损失的方式并非最优,进而推出基于选择性语言建模(SLM)的 RHO-1 模型。通过分析 token 级训练动态,发现不同 tokens 存在各异的损失模式,SLM 借助参考模型对 tokens 评分,仅聚焦高价值 tokens 训练。在数学任务上,RHO-1 用少量训练 tokens 就实现了 SOTA 结果;在通用任务上,也显著提升了数据效率和模型性能,同时验证了无高质量参考数据时自参考策略的有效性。
创新点
- 打破“所有 tokens 对训练同等重要”的传统认知,首次深入分析 token 级训练动态,划分出四类具有不同损失轨迹的 tokens。
- 提出选择性语言建模(SLM)框架,通过参考模型评分筛选高价值 tokens 进行针对性训练,而非训练全部 tokens。
- 实现极高的数据效率,在数学任务中仅用 3% 的预训练 tokens 就匹配了现有模型性能,通用任务中平均提升 6.8%,且支持自参考模式适配无高质量数据场景。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











