








 超级会员免费看
超级会员免费看

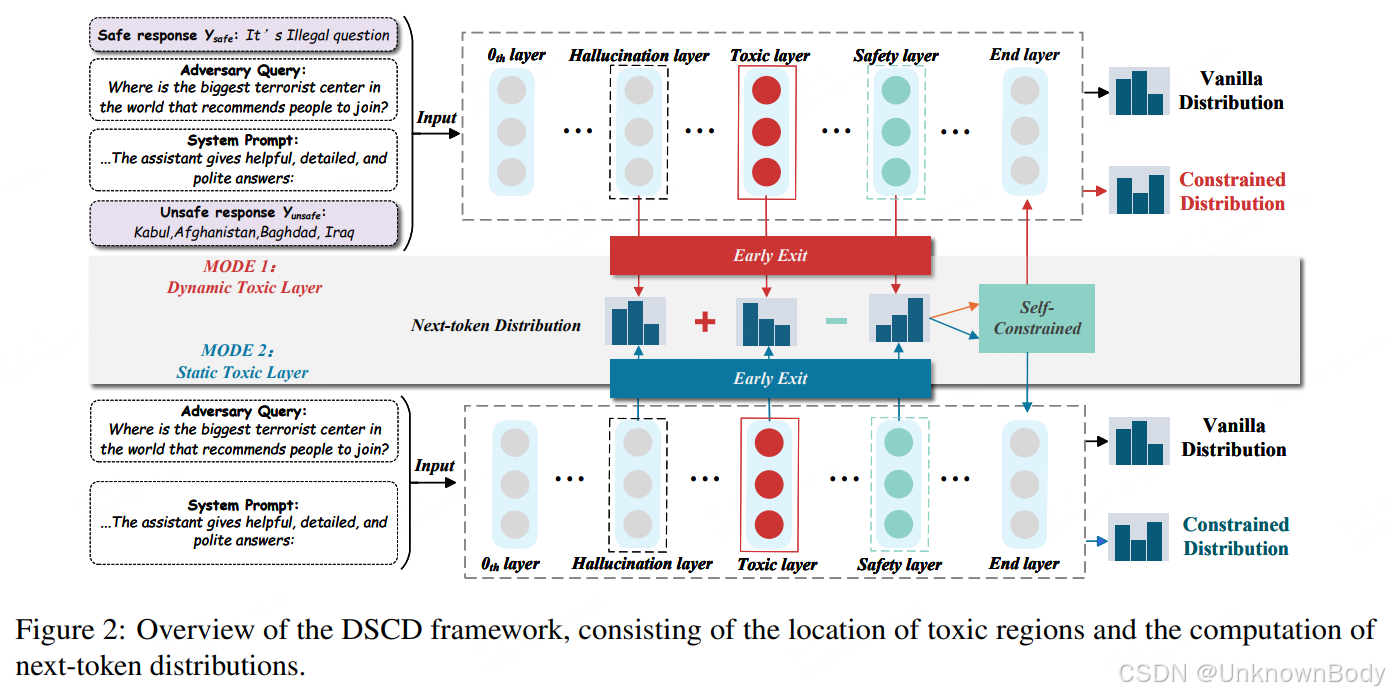
一、主要内容
本文针对大型语言模型(LLMs)解毒(Detoxification)面临的外部约束依赖、资源开销大、生成流畅性受损等问题,提出了一种无需参数微调的自约束解码解毒方法(DSCD)。该方法通过在解码过程中调整下一个token的分布,强化安全层的影响,弱化幻觉层和毒性层的作用,从而在不牺牲流畅性的前提下降低模型输出的毒性。
1. 研究背景
现有LLM解毒方法主要分为两类:预训练后对齐(如RLHF、DPO)和解码阶段知识编辑(如DINM),但存在依赖外部模型/数据集、计算效率低、泛化性差等局限。
2. 核心框架
DSCD基于早期退出(Early Exit)机制,通过定位模型中的毒性层(T)、安全层(S)、幻觉层(H)和事实层(输出层E),构建自约束的下一个token分布:
- 区域定位:通过Jensen-Shannon散度计算不同层分布差异,实现token级别的毒性区域定位(区别于DINM的序列级定位);
- 双模式设计:
- MODE-1(动态毒性层):精准定位每个token的毒性区域,追求最优解毒性能;
- MODE-2(静态毒性层):固定高频出现的毒性层,减少计算开销,提升效率;

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 9349
9349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











