








 超级会员免费看
超级会员免费看

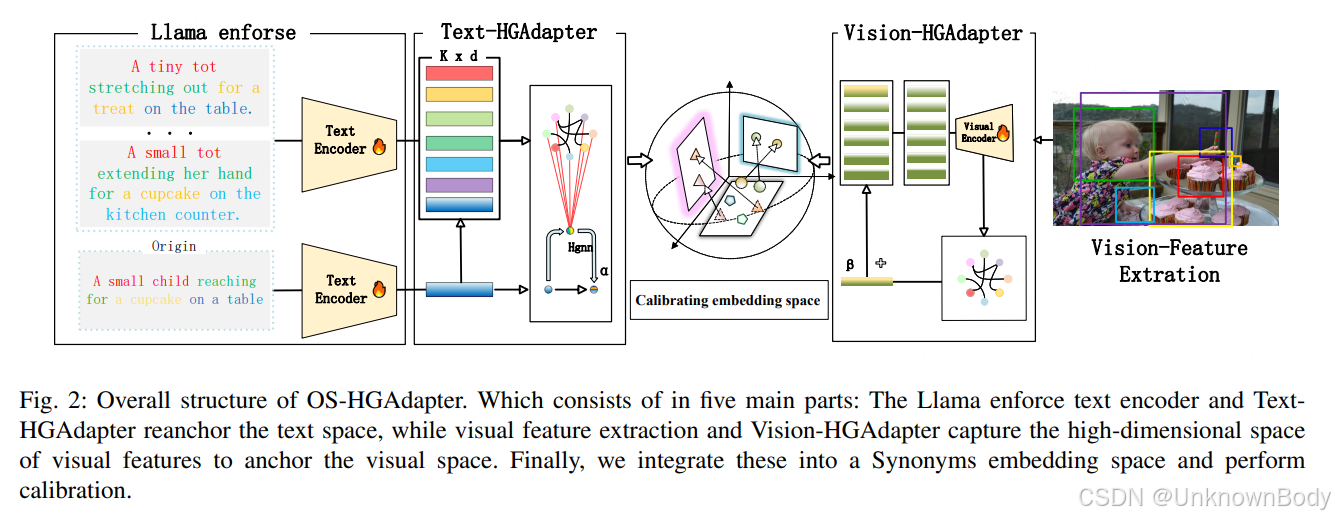
一、主要内容
该研究聚焦于图文跨模态对齐这一多媒体内容理解的核心挑战,针对文本与图像间的信息熵差异导致的检索不平衡问题,提出了开放语义超图适配器(OS-HGAdapter)框架。其核心思路是借鉴人类跨模态感知的熵增机制,通过大语言模型(LLM)补充模态熵差,结合超图结构优化嵌入空间对齐。
核心解决的问题
- 模态信息熵不平衡:文本信息熵(约9比特)远低于图像(约20比特),导致文本到图像检索精度显著低于图像到文本检索。
- 嵌入空间失真:现有方法依赖确定性对齐,无法捕捉同义词语义关联,且LLM生成的开放语义易引入噪声。
- 跨模态匹配误差:固定维度嵌入难以建模复杂语义关系,存在正负样本匹配错误。
技术框架
- LLM驱动的同义词句子增强模块:设计开放式提示模板(如“{}, Generate synonymous sentences”),引导Llama-3-8B生成同义词句,扩充文本语义多样性,提升文本模态信息熵。
- 双路径超图适配器:
- 文本超图适配器(Text-HGAdapter):构建原始文本与同义词句的多边语义关系,通过降维拟合减少开放语义噪声。
- 视觉超图适配器(Vision-HGAdapt

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











