







 超级会员免费看
超级会员免费看
该论文提出基于LoRA的拒绝训练方法,解决大语言模型安全对齐中“提升安全性必牺牲通用性能”的核心问题,通过理论与实验证明LoRA能将安全维度解耦到与模型固有空间正交的低维子空间,实现低成本、保性能的安全对齐。
一、文章主要内容总结
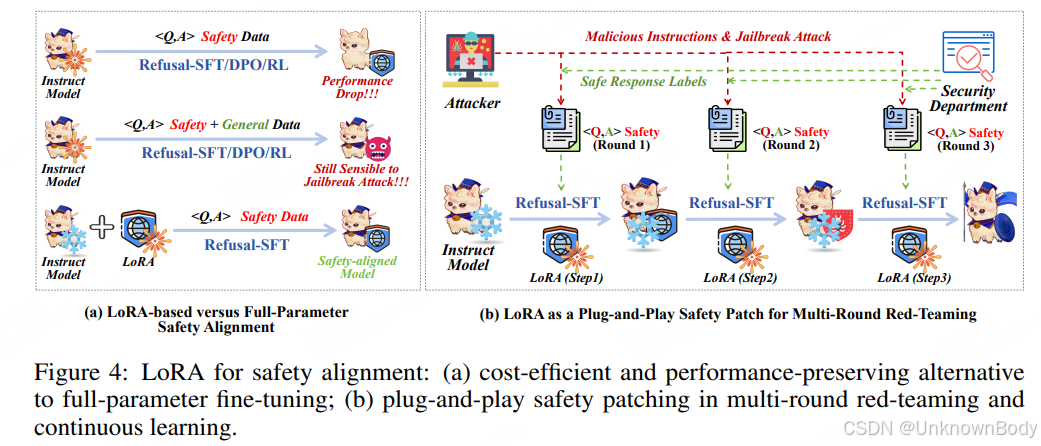
- 核心问题:现有大语言模型(LLMs)安全对齐方法(如SFT、RLHF、DPO)存在两大痛点——需耗费大量计算资源平衡安全数据与通用数据比例,且提升安全性时易导致模型通用能力(如知识问答、数学推理、代码生成)“灾难性遗忘”。
- 解决方案:提出基于LoRA(低秩适应)的拒绝训练(Refusal-training),仅用安全数据训练即可实现安全对齐,无需混合通用数据。LoRA在此场景下具备三大优势:
- 性能保留:大幅降低越狱攻击成功率(ASR),同时几乎不损失模型通用能力;
- 成本高效:仅训练少量外部参数,对齐成本远低于全参数微调;
- 即插即用:可作为轻量化模块,在多轮红队测试与持续学习中迭代优化安全性能。
- 理论支撑:引入“变换子空间正交性”理论,通过奇异值分解(SVD)证明:LoRA引入的权重更新(ΔW)所张成的安全子空间

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 2516
2516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











