





 超级会员免费看
超级会员免费看


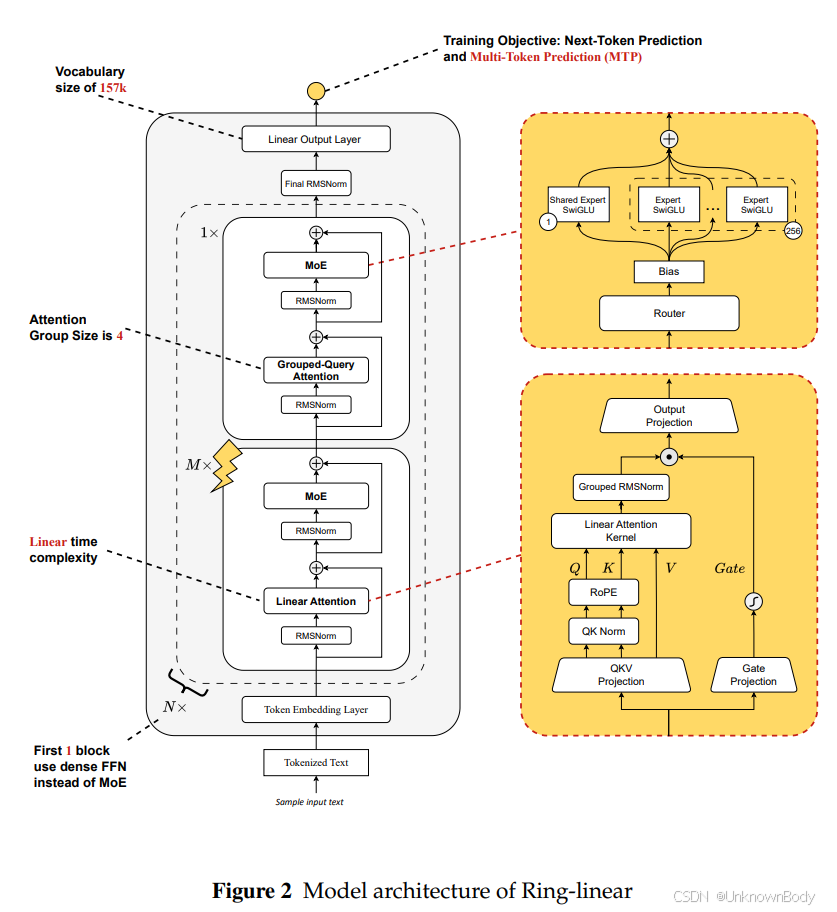
一、文章主要内容
- 模型概述:提出Ring-linear模型系列(含Ring-mini-linear-2.0和Ring-flash-linear-2.0),采用线性注意力与softmax注意力融合的混合架构,上下文长度均支持128K,分别具备16B和104B总参数,聚焦长上下文推理场景。
- 核心优化:基于自研FP8算子库LingHe实现核融合、量化融合等优化,训练效率提升50%,推理成本较32B稠密模型降低至1/10,较初代Ring系列降低超50%。
- 训练流程:采用“持续预训练(4K→32K→128K上下文扩展)+ 监督微调(SFT)+ 强化学习(RL)”三阶段流程,通过训练-推理系统对齐解决RL训练崩溃问题。
- 性能表现:在数学推理、代码生成、通用推理等17个基准测试中,与同参数规模SOTA模型性能相当,长上下文场景下(>8K)预填充吞吐量超基线模型8倍,解码吞吐量超10倍。
二、核心创新点
- 系统探索混合线性注意力架构的预训练配置,确定最优层组规模与注意力比例(Ring-flash-linear-2.0为1:7,Ring-mini-linear-2.0为1:4),平衡效率与表达能力。
- 基础设

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











