





 超级会员免费看
超级会员免费看

一、文章主要内容
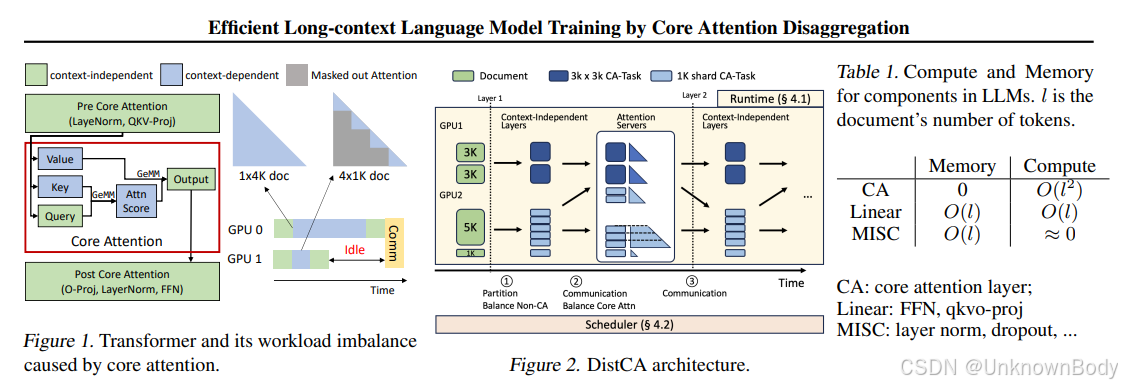
本文针对长上下文大语言模型(LLM)训练中的负载不均衡问题,提出核心注意力解耦(CAD)技术及对应的DistCA系统。核心痛点是核心注意力(CA)计算量随序列长度呈二次增长,而其他组件呈近线性增长,导致数据并行(DP)和管道并行(PP)中出现“掉队者”,严重影响训练吞吐量。CAD通过将无状态、可组合的CA计算与其他模型组件分离,调度到独立的注意力服务器,动态分片并重批处理CA任务,实现负载均衡;DistCA进一步优化通信与内存利用,最终在512个H200 GPU、512K上下文长度下,端到端训练吞吐量提升最高1.35倍,同时消除DP/PP掉队者,保持计算与内存平衡。
二、核心创新点
- 核心注意力解耦(CAD)技术:首次将CA计算从Transformer其他组件中分离,独立调度到专用注意力服务器,解决二次增长的CA与线性增长组件的负载不匹配问题。
- 利用CA的关键特性:基于CA无状态性(无训练参数、暂态状态少)和可组合性(支持任意长度令牌分片的融合批处理),实现高效分片与重批,不损失内核效率。
- DistCA系统优化:设计乒乓执行方案,完全重叠通信与计算;采用原地注意力服务器,提升内存利用率;提出通信感知贪心调度器,平衡负载与通信开销。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 284
284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











