








 超级会员免费看
超级会员免费看

一、文章主要内容
本文聚焦推荐系统中传统方法存在的“语义-协同鸿沟”问题——传统推荐方法依赖ID表征或物品侧内容特征,难以捕捉与用户偏好对齐的底层语义(如推荐理由),而基于大语言模型(LLM)的特征提取方法又面临“如何让LLM具备推荐对齐推理能力并生成精准个性化推荐理由”的挑战。
为此,作者提出CURec(Content Understanding from a Collaborative Perspective)框架,核心流程包含三部分:
- 推荐对齐预训练:通过构建推荐任务相关提示(如分析用户历史交互、推荐候选物品),用强化学习(GRPO算法)微调LLM,使其具备遵循结构化指令、链式推理(CoT)的能力,并能结合世界知识完成推荐任务,初步对齐LLM与推荐目标。
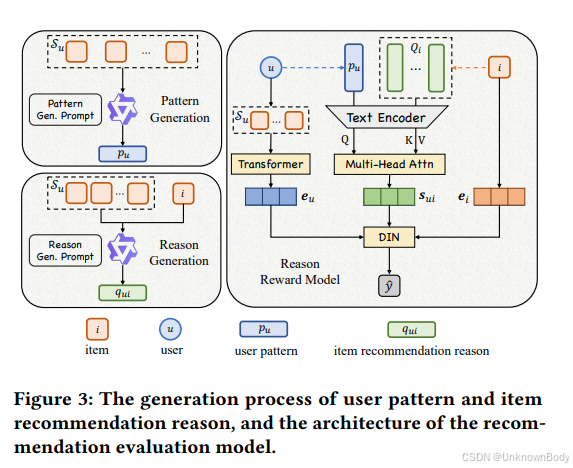
- 带推荐信号的奖励模型:借鉴传统推荐架构设计奖励模型,输入用户兴趣模式与物品推荐理由列表,通过多头注意力机制计算用户-物品匹配分数,评估推荐理由的准确性与个性化程度,同时该模型可直接作为推荐模型使用。
- 时序链式推理修正:用奖励模型的评分作为信号,通过强化学习交替微调LLM与更新推荐理由——先让LLM生成新理由,经奖励模型评估后优化LLM,再用优化后的LLM更新用户兴趣模式与物品理由列表,确保理由精准且实时适配用户动态偏好。 </

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1557
1557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











