








 超级会员免费看
超级会员免费看

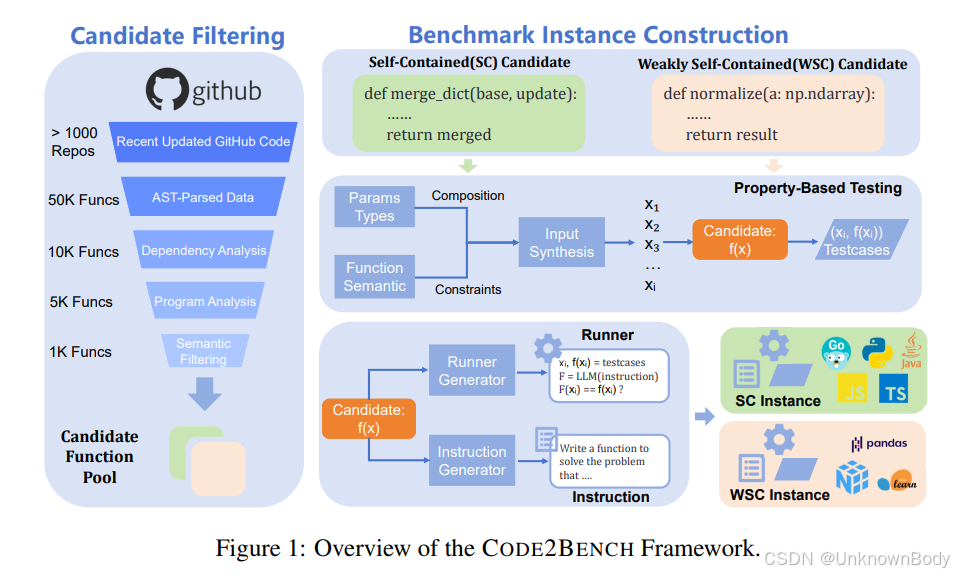
一、文章主要内容
本文聚焦于大型语言模型(LLMs)在真实软件开发场景中代码生成能力的评估问题,针对现有基准测试存在的数据污染、测试严谨性不足、依赖处理缺失等缺陷,提出了动态基准测试构建框架CODE2BENCH,并基于该框架构建了首个动态基准测试集CODE2BENCH-2505。
1. 现有基准测试的核心问题
- 数据污染风险高:多数静态基准测试集(如HumanEval、MBPP)依赖固定数据集,LLMs在训练过程中可能接触到这些数据,导致评估结果失真;部分动态基准测试(如LiveCodeBench)虽能缓解污染,但未直接从真实软件仓库提取任务,缺乏场景真实性。
- 测试严谨性不足:多数基准测试采用手动设计或简单生成的测试用例,难以覆盖复杂逻辑和边缘情况,无法有效暴露模型的细微缺陷(如EvalPlus虽增强测试,但仍基于静态手动任务)。
- 依赖处理与多语言支持缺失:现有基准测试要么未处理代码依赖(如HumanEval-X),要么依赖处理不规范(如RepoBench),且多数仅支持单一语言,无法评估LLMs的跨语言代码生成能力。
2. CODE2BENCH框架核心流程
框架通过“候选筛选”和“基准

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 3015
3015

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











