





 超级会员免费看
超级会员免费看

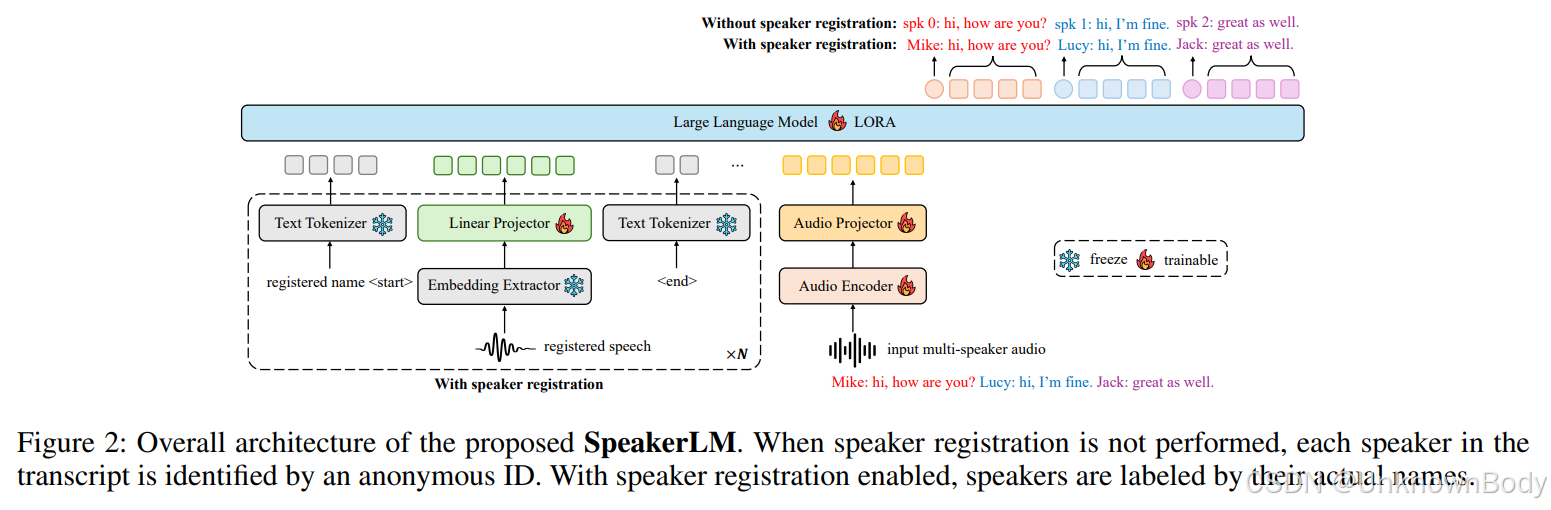
一、论文主要内容
本文聚焦于“说话人日志与识别(SDR)”任务(目标是预测音频片段中“谁在何时说了什么”),针对现有级联式SDR系统(结合说话人日志SD与自动语音识别ASR模块)存在的误差传播、难以处理重叠语音、缺乏联合优化等问题,提出了SpeakerLM——首个用于端到端SDR的多模态大型语言模型(MLLM),并通过多阶段训练策略与灵活的说话人注册机制,实现了更优的SDR性能与更强的场景适应性。
1. 研究背景与现有问题
- SDR任务定义:需同时解决“谁在何时说(SD)”与“说了什么(ASR)”,在会议转录、对话系统等多说话人场景中至关重要。
- 现有系统局限:
- 级联式系统(SD+ASR):SD模块的误差(如边界错误、标签分配错误)会传递至ASR,导致转录质量下降;难以处理现实对话中常见的重叠语音;SD与ASR独立训练,无法利用两者协同性。
- 现有改进方向不足:“说话人归因ASR(SA-ASR)”需依赖预提取的说话人嵌入,场景受限;“LLM后处理”(SD+ASR+LLM)受限于初始SD/ASR输出质量,无法根本解决上游误差。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 989
989




 到【灌水乐园】发言
到【灌水乐园】发言









