





 超级会员免费看
超级会员免费看


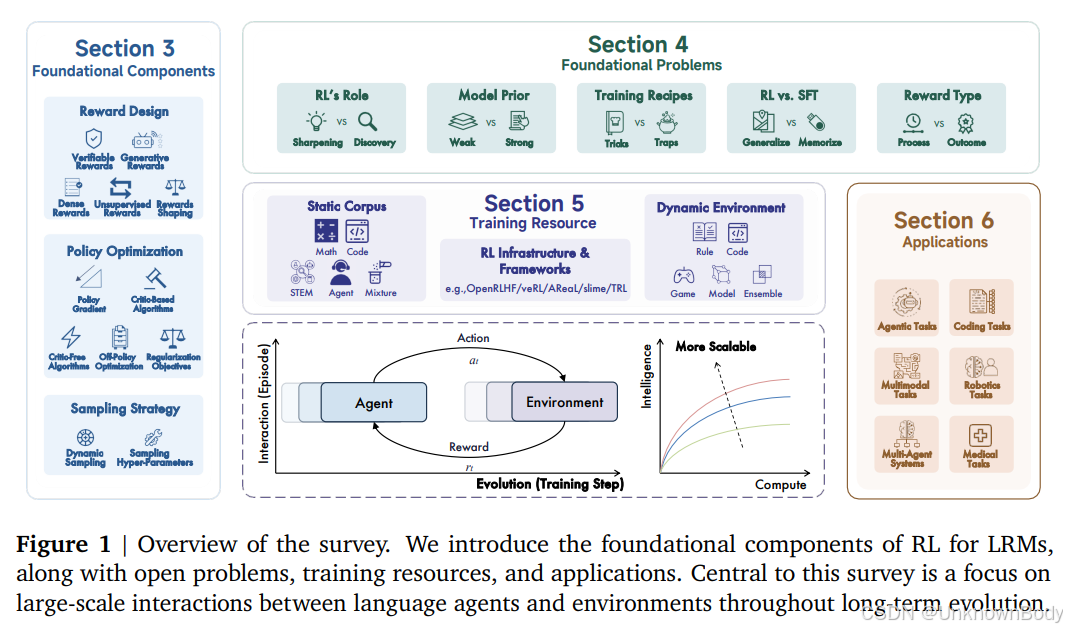
一、主要内容总结
本文是2025年9月发布的关于强化学习(RL)在大型推理模型(LRMs)中应用的系统性综述,聚焦于RL如何推动大型语言模型(LLMs)向具备复杂推理能力的LRMs转化,核心内容可分为以下模块:
1. 研究背景与定位
- 技术演进脉络:RL最初通过RLHF、DPO等方法实现LLMs的人类对齐(提升"3H"能力:有用性、诚实性、无害性),近年转向RLVR(基于可验证奖励的强化学习),成为提升数学、编码等复杂推理能力的核心技术,典型代表如OpenAI o1和DeepSeek-R1。
- 核心挑战:LRMs的RL规模化面临计算资源、算法设计、训练数据与基础设施四大瓶颈,亟需系统性梳理以探索向通用人工智能(ASI)演进的路径。
2. 基础组件解析
- 奖励设计:涵盖可验证奖励(规则驱动,适用于数学/编码等可自动校验任务)、生成式奖励(LLM生成结构化反馈,适配主观任务)、稠密奖励(Token/步骤/轮次级反馈,优化信用分配)、无监督奖励(模型自生成信号,突破人工标注限制)及奖励塑形(组合多源信号稳定训练)。
- 策略优化:包括基于批评家(Critic-based,如P

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1006
1006

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











