




青稞社区:https://qingkeai.online/
原文:https://mp.weixin.qq.com/s/2BB_vycJHCpAL2nYf481Vw

清华课题组和上海人工智能实验室,系统梳理了面向推理模型的 RL 研究,形成一篇关于 RL for Large Reasoning Models 的综述论文。
论文:A Survey of Reinforcement Learning for Large Reasoning Models
链接:https://arxiv.org/pdf/2509.08827
Github:https://github.com/TsinghuaC3I/Awesome-RL-for-LRMs
这篇综述全面介绍了 RL for LRMs 的基础组成、前沿问题、训练资源与应用场景,以及未来面临的挑战。特别关注大模型与环境在长期进化中的交互与学习,希望能为“如何让算力更高效地转化为推理智能”带来一些新思考和启发。
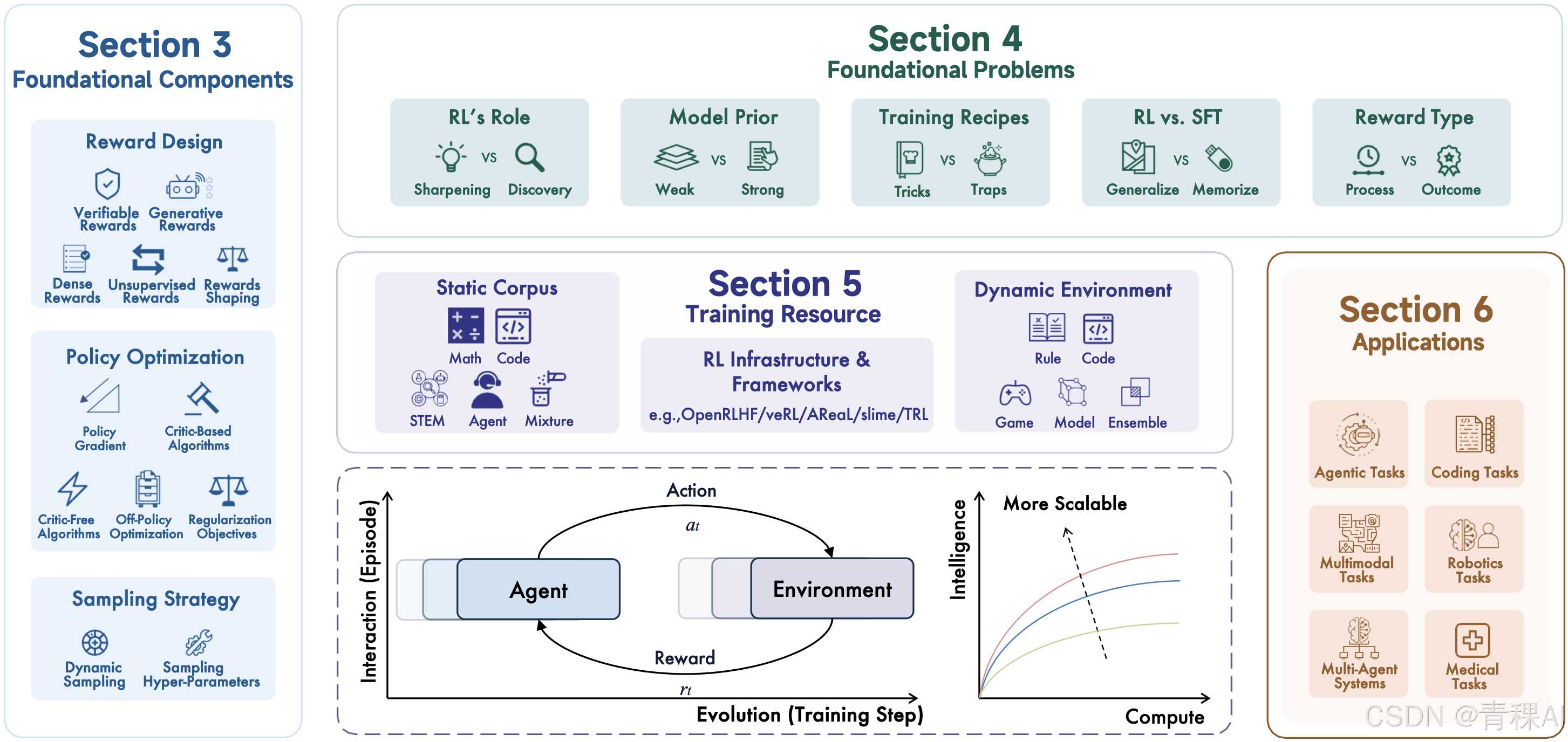
10月21日(周二)晚8点,青稞Talk 第80期,清华大学博士生张开颜,将对此进行直播分享《RL for LRMs:探讨面向推理模型的 RL 最新研究》。
分享嘉宾
张开颜,清华大学三年级博士生,导师为周伯文教授。研究方向为大语言模型测试时扩展(Test-time Scaling)、强化学习和多智能体协同技术。在NeurIPS,ICLR,ICML,ACL,EMNLP,COLM等国际人工智能顶级会议与期刊上发表论文十余篇。
主题提纲
RL for LRMs:探讨面向推理模型的 RL 最新研究
1、LRM 语境下 RL 建模的基本定义及最新发展
2、不同奖励设计、策略优化和采样策略方案的对比
3、讨论 RL 角色、RL vs. SFT、模型先验、训练方法以及奖励定义
4、未来潜在研究方向上的探讨
直播时间
10月21日(周二)20:00 - 21:00
如何观看
Talk 将在青稞社区【视频号:青稞AI、Bilibili:青稞AI】上进行,欢迎预约!
同时,嘉宾已经入驻青稞社区·知识星球,想要提问交流的朋友可以加入星球!


















 1780
1780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









