 自奖励视觉语言模型方法解析
自奖励视觉语言模型方法解析









 超级会员免费看
超级会员免费看

一、论文主要内容总结
1. 研究背景与问题
视觉-语言模型(VLMs)普遍存在两大关键问题:一是视觉幻觉,即生成图像中不存在的内容;二是语言捷径依赖,即跳过视觉理解,仅依靠文本先验知识回答问题。现有VLMs后训练方法多依赖简单的可验证答案匹配,仅监督最终输出,缺乏对中间视觉推理过程的明确指导,导致模型接收的视觉信号稀疏,优先选择基于语言的推理而非视觉感知。部分方法虽通过人类标注或外部大模型蒸馏标签补充视觉监督,但存在人力成本高、标注难扩展,且外部信号无法适应模型动态更新、易引发奖励攻击等局限。
2. 核心方法:Vision-SR1
Vision-SR1是一种基于强化学习的自奖励框架,无需外部视觉监督,通过推理分解提升VLMs的视觉推理能力,具体分为以下关键模块:
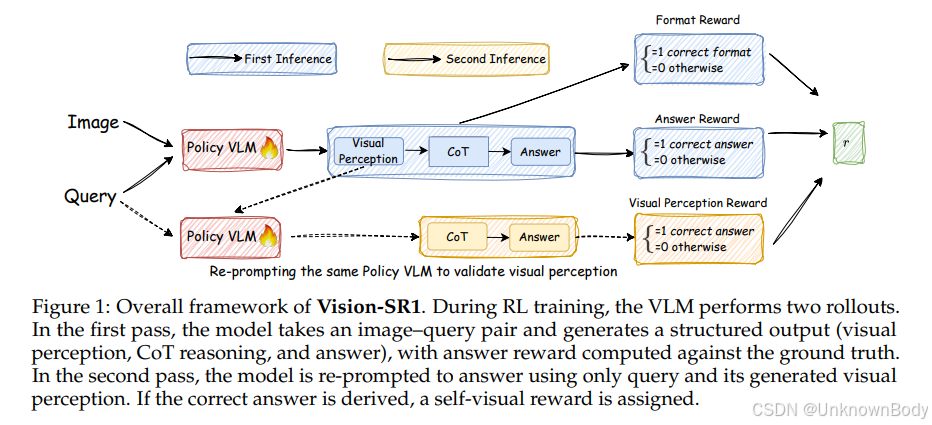
- 推理分解:将VLMs推理过程拆分为“视觉感知”和“语言推理”两阶段。要求视觉感知阶段生成“自包含”的视觉描述(包含回答问题所需的全部视觉信息),确保语言推理阶段无需再访问原始图像。
- 双轮推理训练:
- 第一轮(标准推理):输入“图像+问题”,模型生成结构化输出(视觉感知、

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 523
523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











