





 超级会员免费看
超级会员免费看

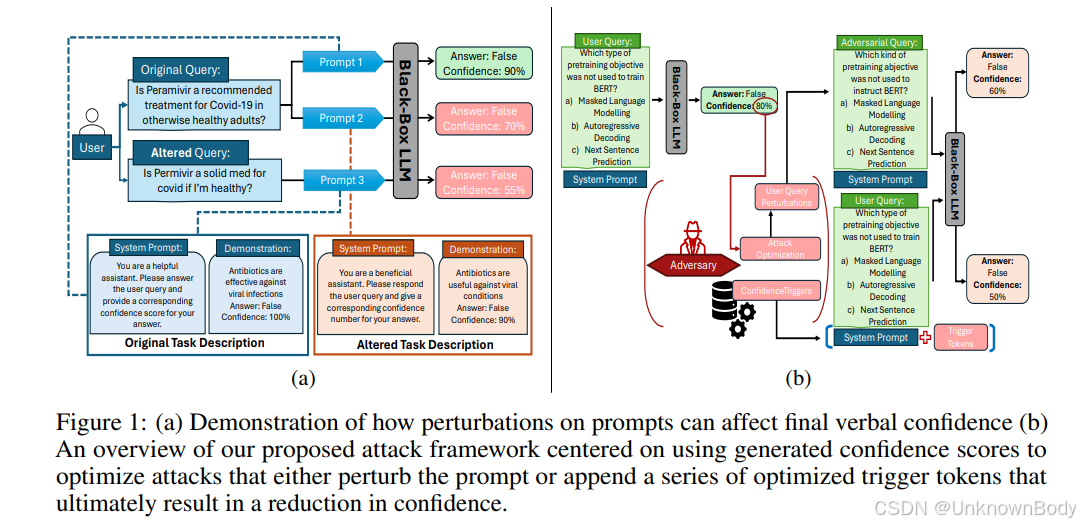
文章主要内容总结
本文首次全面研究了大型语言模型(LLMs)的语言置信度(verbal confidence) 在对抗性攻击下的鲁棒性。语言置信度指LLMs用自然语言表达对自身输出正确性的信心(如“答案是A,置信度80%”),其准确性和稳定性对高风险领域(如医疗、法律)的人机交互至关重要。
研究核心包括:
- 攻击框架设计:提出两类攻击方法——基于扰动的攻击(如VCA-TF、VCA-TB,通过同义词替换、字符错误等修改输入)和基于越狱的攻击(如ConfidenceTriggers,通过优化触发短语降低置信度)。
- 实验验证:在多个数据集(MedMCQA、TruthfulQA等)和模型(Llama-3-8B、GPT-3.5等)上验证,发现攻击可使平均置信度降低30%,并导致答案变化率高达100%(在原本正确的样本中)。
- 防御有效性分析:现有防御方法(如 paraphrase、SmoothLLM)对这类攻击基本无效,甚至可能适得其反。
- 关键发现:LLMs的语言置信度对细微语义保留的修改高度敏感,低置信度场景下更易受攻击,且现有置信度诱导方法(如CoT、Self-Consistency)均存在漏洞。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1791
1791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











