 推理型LLM在物理问题求解中的优势
推理型LLM在物理问题求解中的优势








 超级会员免费看
超级会员免费看
文章主要内容总结
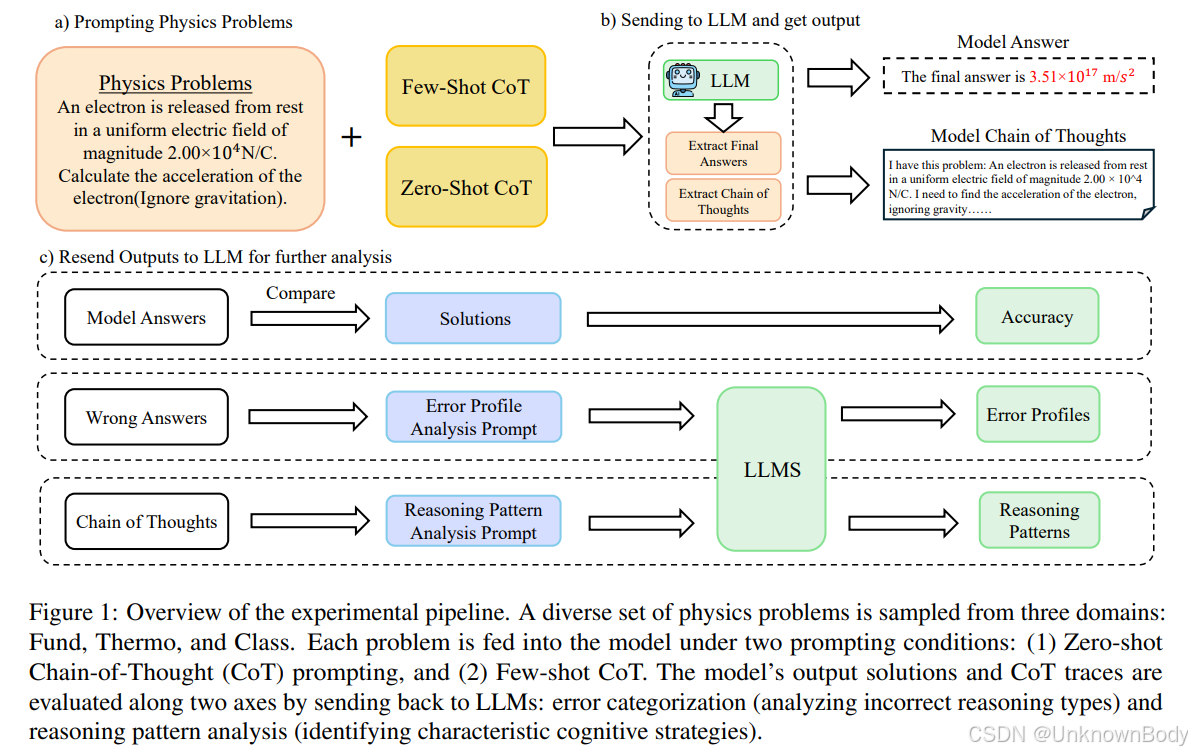
本文聚焦于推理型大型语言模型(LLMs)在物理问题求解中的能力,以Deepseek-R1及其蒸馏模型为研究对象,通过SciBench基准中的三个物理数据集(涵盖经典动力学、热力学、基础物理),系统评估了零样本思维链(Zero-Shot CoT)和少样本思维链(Few-Shot CoT)两种提示策略的效果。主要发现包括:
- 推理型LLM(如Deepseek-R1)在无需大量提示工程或外部工具的情况下,物理问题求解准确率显著优于通用聊天模型(如GPT-4-Turbo),零样本平均准确率达75.9%,少样本进一步提升至81.3%。
- 推理型模型偏好符号推导(先通过代数操作方程,再代入数值计算),而聊天型模型更依赖逐步数值代入,这种差异是推理型模型在多步骤物理问题中表现更优的关键。
- 少样本提示对先进推理模型仍有显著增益,尤其在经典力学领域(准确率从62.5%提升至84.8%)。
- 蒸馏模型(如R1-distill-Qwen-32B)在降低计算成本的同时,性能可媲美甚至超越更大规模的通用模型,体现了任务特定优化的价值。
创新点
- 首次系统验证推理型LLM的独立物理推理能力:证明先进指令微调推理模型无需复杂提示工程或外部工具,即可

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 215
215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











