







 超级会员免费看
超级会员免费看
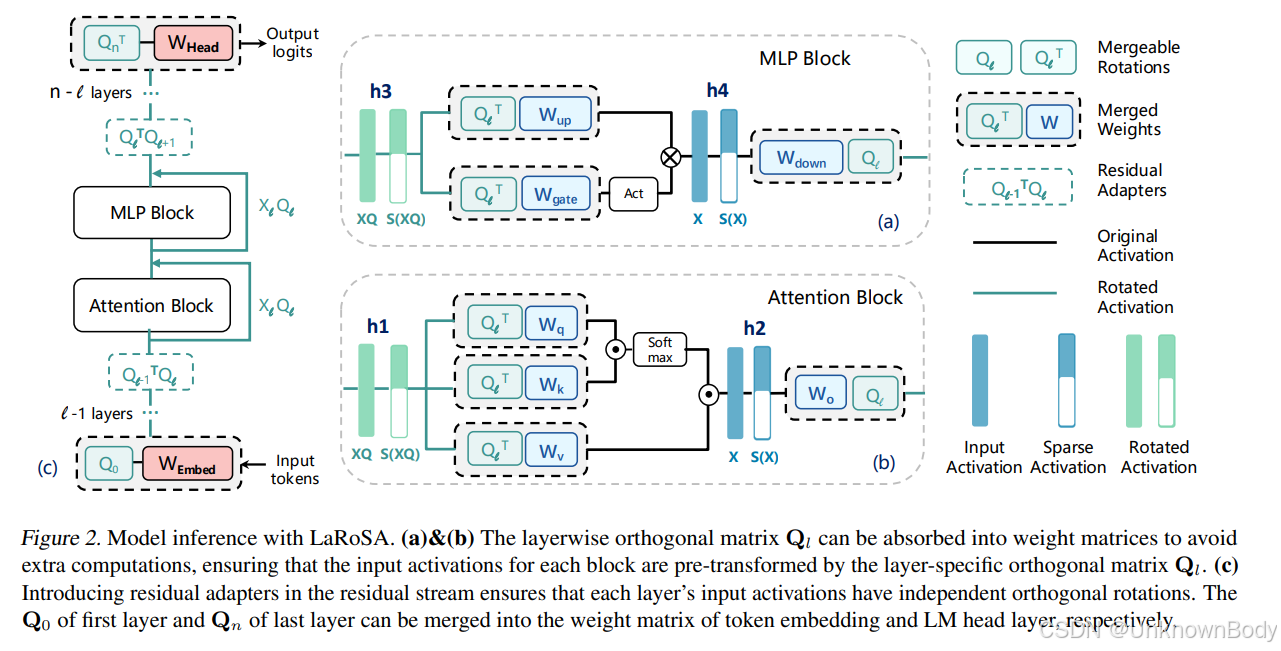
文章主要内容总结
本文提出了一种名为LaRoSA(Layerwise Rotated Sparse Activation,层-wise旋转稀疏激活)的新方法,旨在通过激活稀疏化提升大型语言模型(LLM)的推理效率。其核心思路是利用层-wise正交旋转将输入激活转换为更适合稀疏化的形式,再通过Top-K选择实现稳定的模型级稀疏性,从而在不额外训练或依赖经验幅度剪枝的情况下,减少计算开销和内存传输,同时保证性能下降最小化。
实验表明,LaRoSA在多种类型、大小的LLM(如LLaMA2、LLaMA3、Qwen2.5、Mistral等)上均有效:在40%稀疏度下,LLaMA2-7B的困惑度差距仅0.17,实际运行时间加速1.30倍,零样本任务精度差距仅0.54%,显著优于TEAL(提升1.77%)和CATS(提升17.14%)。
创新点
- 层-wise正交旋转:通过正交旋转矩阵(基于PCA构建)转换输入激活,使激活更易稀疏化,且旋转矩阵可融入权重矩阵,避免额外计算开销。
- 一致的模型级稀疏性:采用Top-K函数替代基于幅度的剪枝,解决了现有方法稀疏性波动、推理速度不稳定的问题,实现了稳定的稀疏度控制。
- 无需额外训练:无需恢复训练或经验阈值校准,适用于非ReLU激活的现代LLM(如使用Sw

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 448
448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











