







 超级会员免费看
超级会员免费看
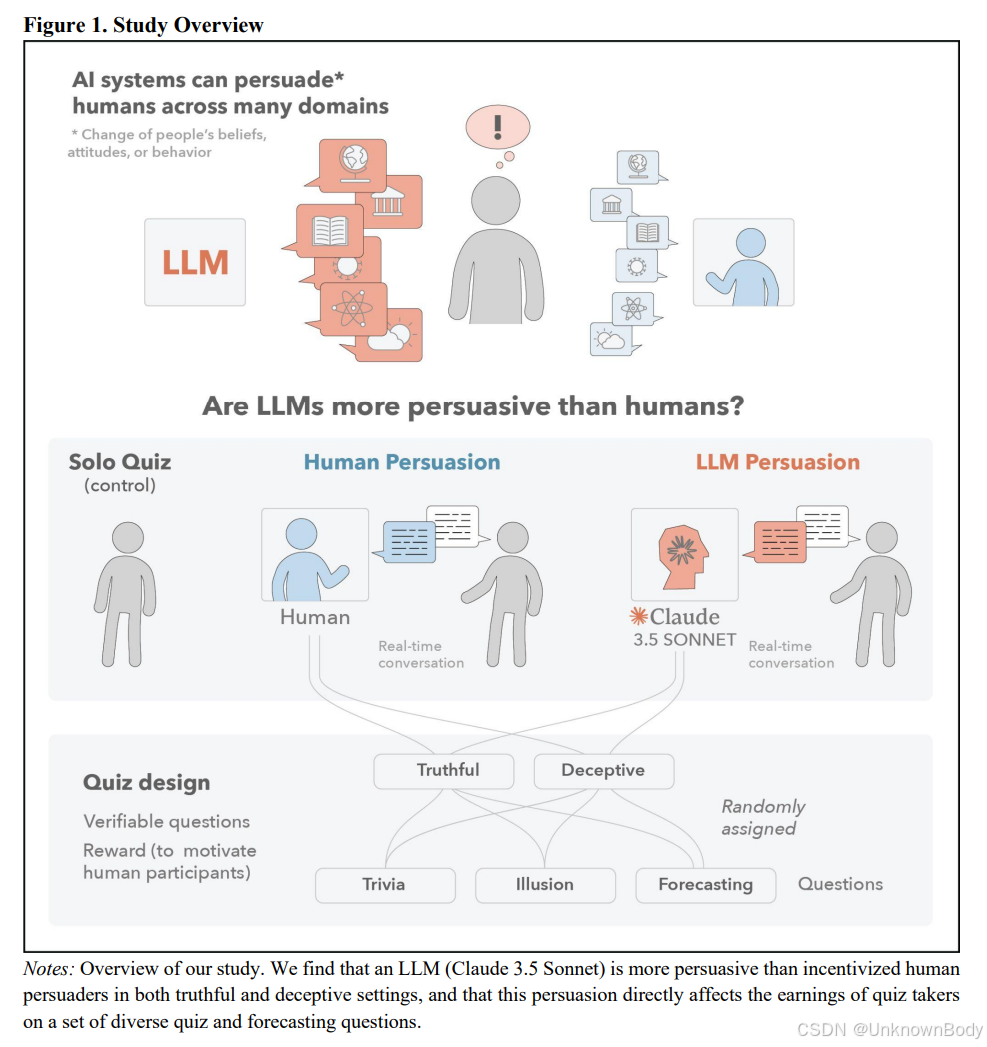
文章主要内容总结
本文通过大规模实验对比了前沿大语言模型(LLM,Claude Sonnet 3.5)与受激励人类说服者的说服能力,发现LLM在真实(引导正确答案)和欺骗性(引导错误答案)场景中均显著优于人类,且其说服力直接影响答题者的准确率和收益。研究强调了AI说服能力的潜在风险,呼吁加强对齐和治理框架。
创新点
- 实时对话场景:在交互式实时对话测验中进行实验,更贴近真实世界的说服场景,突破了静态单轮信息的局限。
- 双场景对比:同时考察真实(引导正确答案)和欺骗性(引导错误答案)说服情境,揭示LLM在不同伦理维度的表现。
- 强激励基准:人类说服者和答题者均有金钱奖励,确保人类表现接近真实高 stakes 场景,增强了实验的基准有效性。
- 多维度评估:结合准确率、合规率、语言复杂度分析,从行为和语言特征层面解析LLM的说服机制。
英文摘要、引言、结论翻译
摘要
我们在一个交互式、实时对话测验环境中,直接比较了前沿大语言模型(LLM;Claude Sonnet 3.5)与受激励人类说服

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











