








 超级会员免费看
超级会员免费看

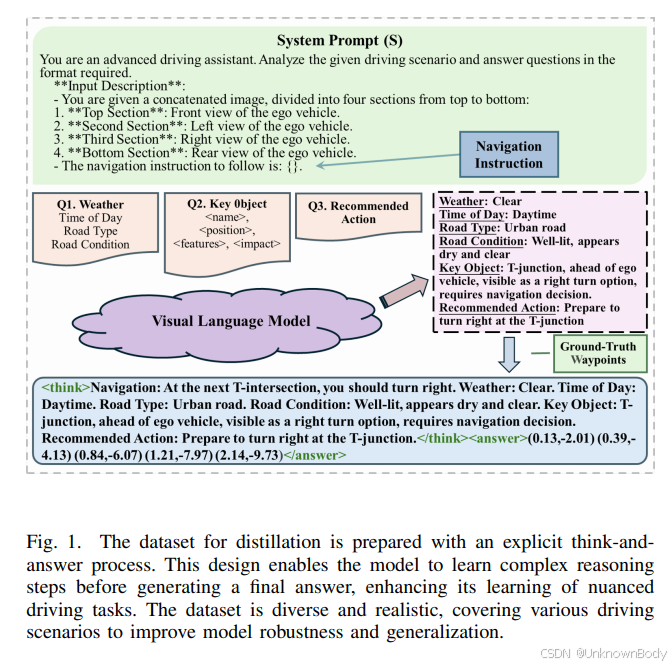
一、文章主要内容总结
本文提出了一种轻量级端到端自动驾驶框架 DSDrive,旨在解决传统端到端自动驾驶框架中认知过程不足的问题,同时应对大语言模型(LLMs)在自动驾驶中集成时面临的计算效率低和高层语义推理与低层轨迹规划脱节的挑战。具体内容包括:
- 框架设计:
- 知识蒸馏:利用紧凑型LLM(如LLaMA-1B)作为学生模型,通过蒸馏从大型视觉语言模型(VLM,如Qwen2.5-VL-max)中提取推理能力,生成结构化的“思考-回答”数据集,保留复杂推理能力。
- 双头部协调模块:设计航点驱动的双头部模块(推理头和规划头),将航点作为推理的最终答案,统一优化目标,实现高层推理与低层轨迹规划的对齐。
- 实验验证:
- 在CARLA模拟器中进行闭环仿真,DSDrive在驾驶分数(DS)、路线完成率(RC)等关键指标上优于或接近基准模型(如LMDrive),且模型体积更小、计算效率更高。
- 定性分析表明,DSDrive能在复杂场景(如交通灯识别、弯道让行)中生成可解释的推理过程,并精准预测航点。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 8829
8829

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











