







 超级会员免费看
超级会员免费看
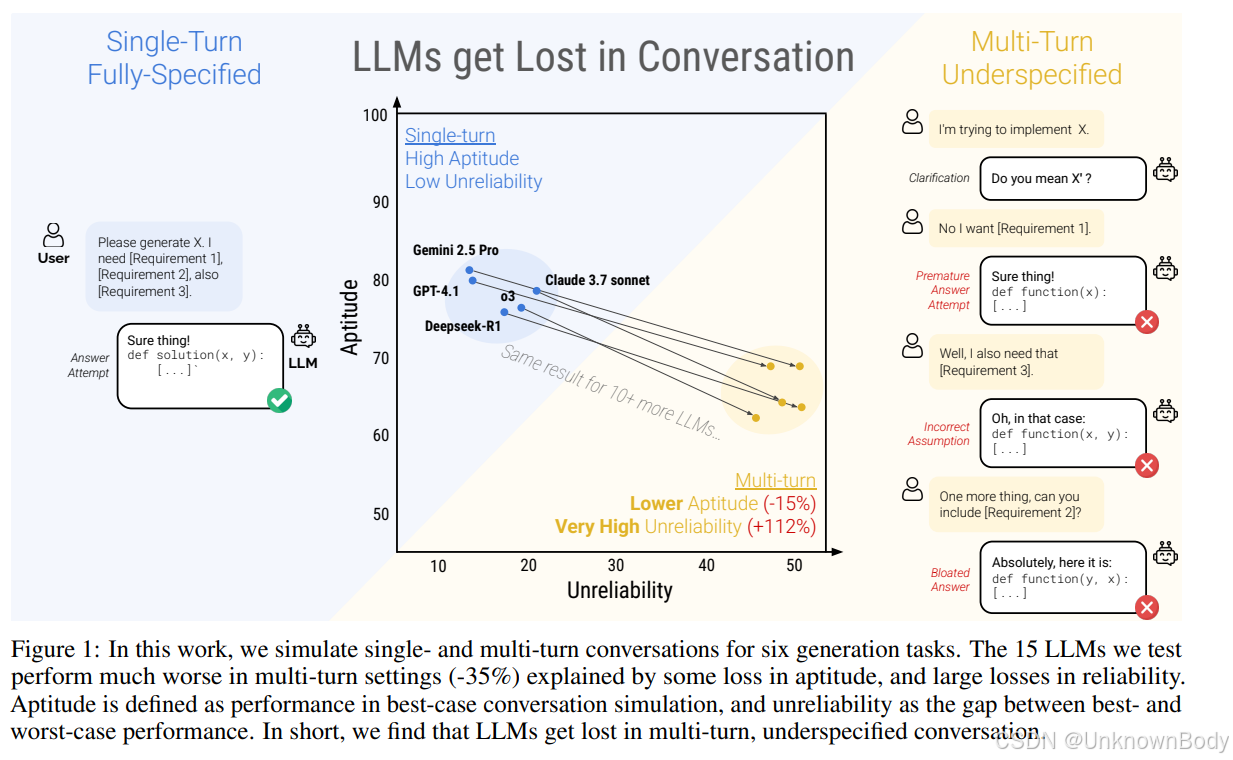
文章主要内容
本文聚焦于大语言模型(LLMs)在多轮对话中的表现问题。通过大规模模拟实验,对比了LLMs在单轮和多轮对话中的性能差异,发现所有测试的LLMs在多轮对话中的表现显著低于单轮,平均下降39%。研究将性能下降分解为两个部分:能力的轻微下降和不可靠性的显著增加。进一步分析表明,LLMs在对话早期常做出假设并过早尝试生成最终解决方案,且一旦出现错误就难以恢复。此外,文章还探讨了任务类型、模型规模等因素对多轮对话表现的影响,并提出了可能的改进方向和对系统构建者、模型开发者的建议。
文章创新点
- 模拟实验设计:开发了“分片模拟”环境,将单轮完整指令拆分为多个分片,逐步在多轮对话中揭示,以模拟真实的不完整指令场景。
- 性能分解框架:提出将LLMs在多轮对话中的性能下降分解为“能力损失”和“不可靠性增加”,量化了两者的贡献(能力平均下降15%,不可靠性增加112%)。
- 错误机制分析:识别出LLMs在多轮对话中的四种典型错误行为:过早生成答案、过度依赖先前错误回答、忽略中间对话内容、响应冗长导致假设偏差。
- 跨模型一致性结论:实验覆盖15个主流LLMs(包括开源和闭源模型),发现无论模型规模和能力如何,多轮对话中的性能下降具有普遍性。 </

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 2119
2119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











