







 超级会员免费看
超级会员免费看
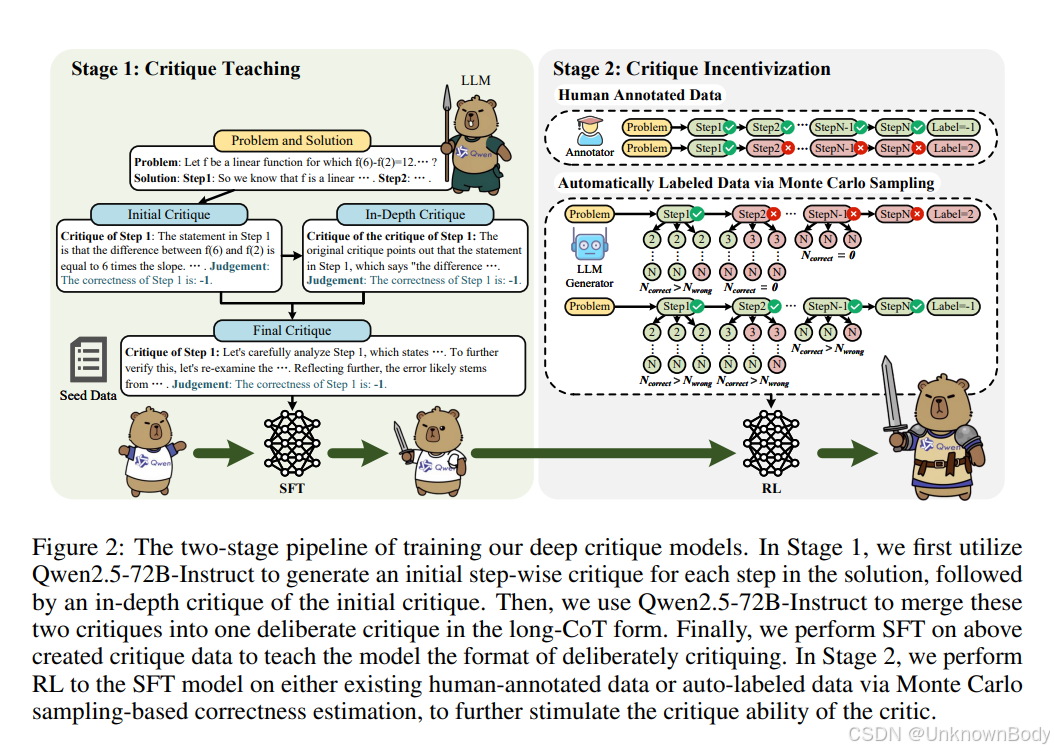
主要内容
- 研究背景:大语言模型(LLMs)发展迅速,对其输出进行有效监督至关重要。利用LLMs作为批判模型实现自动监督是有前景的方向,但现有LLM批判模型在数学推理等复杂领域能力有限,批判往往过于肤浅,无法提供准确可靠的反馈。
- 相关工作:介绍了LLMs批判能力和推理能力的研究现状,指出当前研究旨在利用和提升LLMs的批判能力,同时探索LLMs在各领域的推理能力。
- 方法
- 问题公式化:定义了批判问题的设置,包括问题、解决方案以及批判模型的输出形式。
- DeepCritic模型:提出两阶段训练管道。第一阶段,利用Qwen2.5 - 72B - Instruct生成包含多视角验证和元批判的长格式批判数据作为种子数据,进行监督微调(SFT),使模型学习刻意批判的格式和结构。第二阶段,基于SFT模型,使用人类标注数据(如PRM800K)或通过蒙特卡罗采样自动标注的数据进行强化学习(RL),进一步激励模型的批判能力。
- 实验与分析
- 实验设置:选择Qwen2.5 - 7B - Instruct为基础模型,在三个错误

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 410
410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











