








 超级会员免费看
超级会员免费看


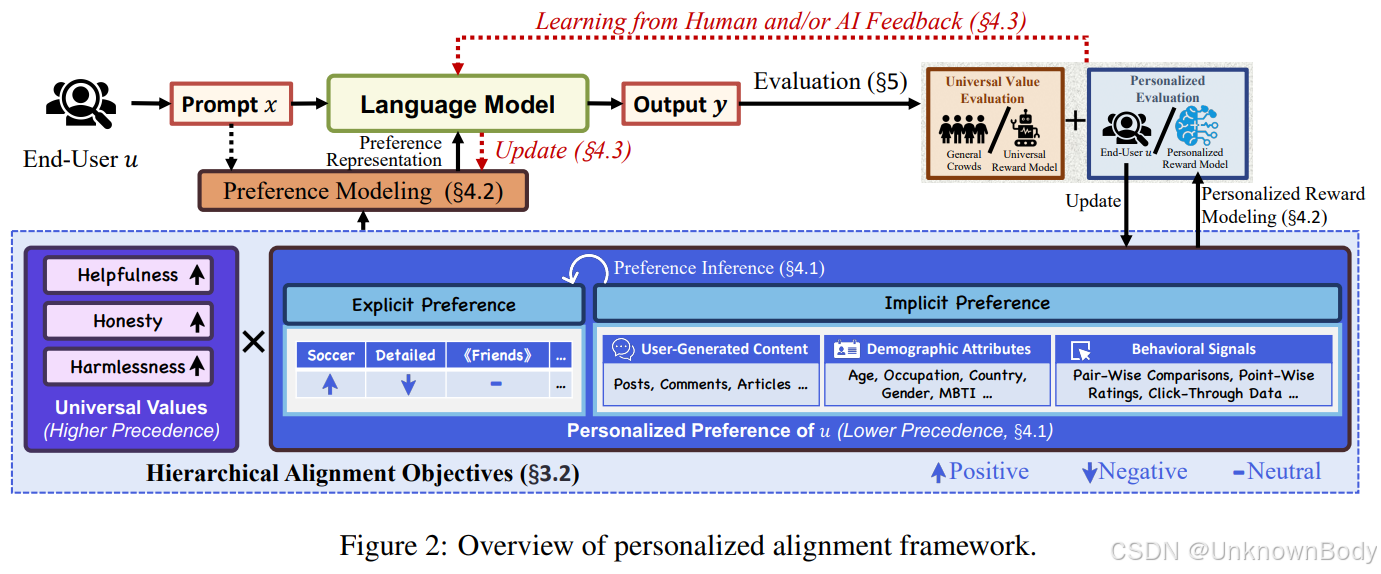
文章主要内容总结
本文系统探讨了大型语言模型(LLMs)在实际应用中的个性化对齐问题。当前LLMs通过监督微调(SFT)和人类反馈强化学习(RLHF)实现了与通用人类价值观(如帮助性、诚实性、无害性)的对齐,但在适应个体用户偏好方面存在显著不足。作者提出了一个统一的个性化对齐框架,包含以下三个核心组件:
-
偏好记忆管理
- 管理用户显式(如直接反馈)和隐式(如行为数据、用户生成内容)的偏好信息。
- 通过偏好推理将隐式信号转化为结构化的偏好空间。
-
个性化生成与奖励
- 通过提示注入、编码嵌入、参数微调或代理工作流等方式,将用户偏好融入生成过程。
- 结合通用价值观约束与个性化奖励模型,优化生成质量。
-
基于反馈的对齐
- 利用用户反馈更新偏好记忆和生成策略,平衡训练时和推理时的对齐优化。
论文还分析了现有技术(如提示工程、参数高效微调、联邦学习)的优缺点,讨论了评估方法、应用场景(如个人助理、教育、医疗)

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











